Performance is slow with larger result sets #15
Comments
|
Original comment by Aaron Bartell (Bitbucket: aaronbartell, GitHub: aaronbartell). Hi @krisbaehr, Could you share the Node.js code you're using to calculate the Node.js stats? If the code is more than 100 lines then maybe create a Bitbucket Snippet. |
|
Original comment by Kristopher Baehr (Bitbucket: krisbaehr, GitHub: krisbaehr). @aaronbartell Be forewarned, I'm pretty new to this Node.js thing! https://bitbucket.org/snippets/krisbaehr/keBa4E/node-sql-sp-call-for-performance-testing |
|
Original comment by Xu Meng (Bitbucket: mengxumx, GitHub: dmabupt). Hello @krisbaehr , My test -- |
|
Original comment by Jesse G (Bitbucket: ThePrez, GitHub: ThePrez). @krisbaehr, any luck? I'm hoping this shows proof of concept while we work on a more permanent fix. |
|
Original comment by Xu Meng (Bitbucket: mengxumx, GitHub: dmabupt). @krisbaehr Commit b56ab92 and c97e353 fixed the problem. Now the column width is accurate. You can upgrade idb-connector to v1.0.6 to verify that. |
|
Original comment by Xu Meng (Bitbucket: mengxumx, GitHub: dmabupt). @krisbaehr Does version 1.0.6 fix the problem? I forgot to mention that in the fix there is no more environment variable to set the column width. The accurate column width is calculated automatically to save memory usage. |
|
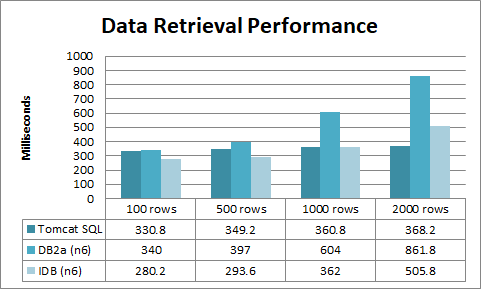
Original comment by Kristopher Baehr (Bitbucket: krisbaehr, GitHub: krisbaehr). @dmabupt, We switched over to version 1.0.6 last week and ran some tests. There was a significant performance improvement! Before db2a was performing about the same as JDBC at 500 rows, after our various tweaks, including OS tweaks for improved multi-threaded processing. Now, 1.0.6 is equal with JDBC at 1000 rows. At 2000 rows, it's still performing pretty well and flat out smokes db2a (I'm not sure what version that was). Thanks for everything. |
|
Awesome! |
Original report by Kristopher Baehr (Bitbucket: krisbaehr, GitHub: krisbaehr).
I've noticed that this connector is slower than jdbc in terms of handling the result sets and I have an idea. The idb connector is converting the result set to json, where as jdbc is not. I'm thinking that this may be the major difference in execution time that I'm seeing. I've tried turning debugging on for the connection but didn't get what I was hoping for.
I'd like someone (I'm willing to help with assistance) to modify dbconn.cc to accumulate time spent performing various functions. Specifically, how much time is being spent converting the odbc result to json. Then, add debug() statements to report these times to the console.
If we find that the json conversion is where a large majority of time is being spent, I would like the maintainers to explore alternate solutions.
Thanks!
The text was updated successfully, but these errors were encountered: