Model Pipeline
This page describes the overall architecture of the IceNet pipeline and details of implementation(s) / repositories that support its deployment and execution.
The model is effectively an exemplar of operationalising a characteristic DL model, the underpinning pipeline approach should be fittable to any similar model.
As such, the execution environment needs to remain as portable and supportable as possible. This is not a technical adoption exercise but rather a best-practice implementation adopting SRE/DevOps style release and support considerations to produce a high uptime, reliable and continuously delivered model.
Decomposing IceNet2
Currently the IceNet2 code is private, please ask Tom Andersson for access if required.
The original IceNet procedure worked on the following high level principle:
- Source data, project and preprocess the variety of SIC/reanalysis/simulation/forecast data, involving some cross dataset processing
- Create necessary data store for full dataset
- Pre-train with simluation data (CMIP6 MRI-ESM2.0/EC-Earth3 ensembles 1850-2100)
- Fine-tune train/calibrate with observational data (SIC/ERA5 reanalysis data 1979-2011)
- Validate (2012-2017)
- Test generalisation (2018-2020)
The training took place with an ensemble of variantly initialised models and the published code will be made available here. This is a very standard ML pipeline to consider.
The process listed above will be largely the same for IceNet2, with some alterations to process, train and predict based purely on daily data. Thankfully, much of the work for this is already done, but we look to refactor the existing research code to facilitate ongoing operational predictions, transferred retraining with up-to-date sources and research activities that can be easily adopted into the pipeline.
To do this I will use some common strategies found in SRE-style roles as the foundation for ongoing continual improvements to the model. Though this thinking is commonly used in commercial and business deployments, these tactics are not in any way pinned to such areas and are definitely required to produce a maintainable, flexible pipeline that can support applications and services into the future.
- The implementation of the execution environment is to be distinct from the model code - infrastructure provisioning code and model code will live in different repositories and be distinctly packaged. This will allow the pipeline to be adapted for use with other models looking forward.
- CI/CD workflows are defined for keeping track of packages deployed and facilitate ease of failover/deployment.
- Monitoring and supportability are critical and will be specified.
- To avoid vendor lock-in we only entertain strict dependencies, to ensure future portability and reproducability.
- The pipeline will facilitate blue-green deployment for staging and consider the practicality of ongoing research usage.
- Each model-run environment needs to be capable of running an ensemble of models, with local post processing prior to egress (if desired).
- The intention is that the processing chain can be easily invoked by support staff and monitored as required. As such, any stage of the workflow should be subject to documented manual intervention.
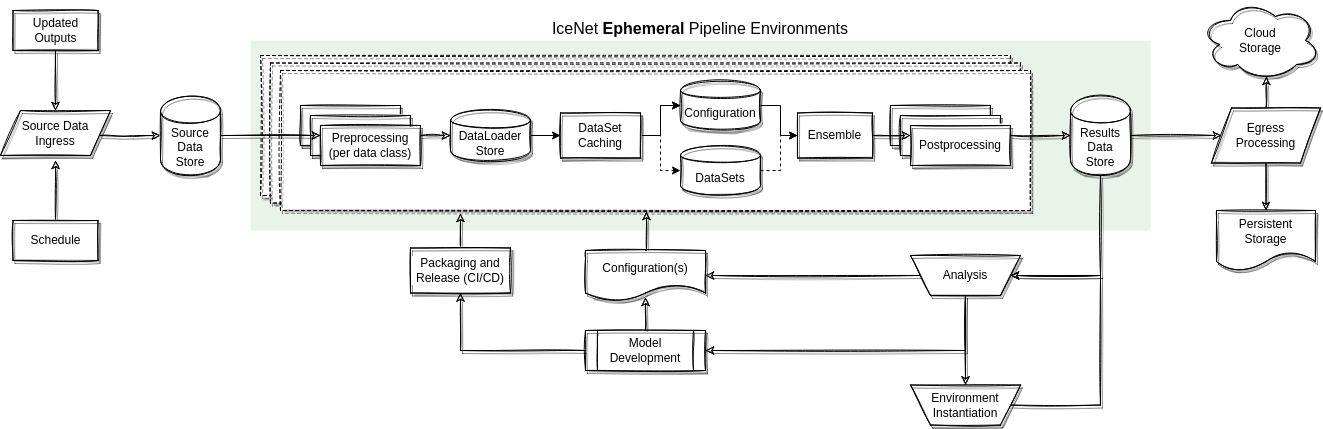
The IceNet2 code requires some level of refactoring from the original research codebase to distinctly separate the tasks out.
The pipeline above is roughly split into three segments of functionality: input, model and output.
The inputs being consumed will evaluated each day, so therefore a mechanism for either (a) event-driven subscription or, more likely, (b) polling of the remote API(s) to draw out data needs to be maintained and invoked automatically when new data is available, in part or in full. Depositing of this new data in the source data store will make it available to any subsequent runs that take place (though it is not necessarily in scope to connect these activities through automation in the first instance, this should not be hampered by design if it is to take place in the future.)
The plan is to use ECMWF real time products for the input, though there are also publicly available 5-day reanalyses data available in the meantime.
This is composed of the Icenet2 Ephemeral Ensemble Environments, as labelled in the diagram above, and the pipeline operations that will bind together the acyclic operation.
The former environment will be encapsulated by a semantically versioned package built from the IceNet codebase. This will be packaged via github actions and pushed out via a repo host (e.g. PyPI). Doing this allows environments to be running differing versions of packages which supports research/alpha testing/non-production data streams to be run alongside the staging/production environment, based on the distribution of updated packages.
The pipeline element of the operational phase (under the environment block) is a manual set of operations in the first instance. Implementation details to note are the use of code-based provisioning to deploy the environment in whole, which will be stored in the codebase. This will provision the necessary installation of the depedencies, packages and filesystem structure. By keeping this automated we can easily create environments in any infrastructure, with the acyclic operation of the full pipeline managed by any suitable workflow manager.
The output will contain both a mean and standard deviation for the sea ice concentration at each grid cell and lead time. The NetCDF will be CF compliant with the following dimensions: leadtime, y, x, quantities, where the quantities will be a set containing 'mean' and 'std', in the first instance. As with the input, egress actions to external stores should respond to creation of forecasts in the results data store.
Additional export postprocessing will also take place at this stage.
The IceNet2 model codebase will be pip packaged with dependencies as per best practice. We'll rely on direct github interaction for packaging and installation for the development phase but we will want this to be distributed through PyPI eventually. If you need more information on Python packaging and how to do it, I seriously advise reading this guide.
The IceNet codebase will be refactored to provide atomic console entry points for each action taken by the system. This saves time and effort in creating the necessary CLI entry points that can be leveraged by a workflow implementation, whilst ensuring the API for customisation is clear and consistent with the workflows.
TODO: will be completed for reference after refactor
The IceNet2 codebases are still private, I'll discuss with Tom what the eventual position will be on the model code. The input/output segments will likely become independent tools in the long run as well.