💻Online Demo |
🤗Huggingface |
📃Paper |
💭Discord
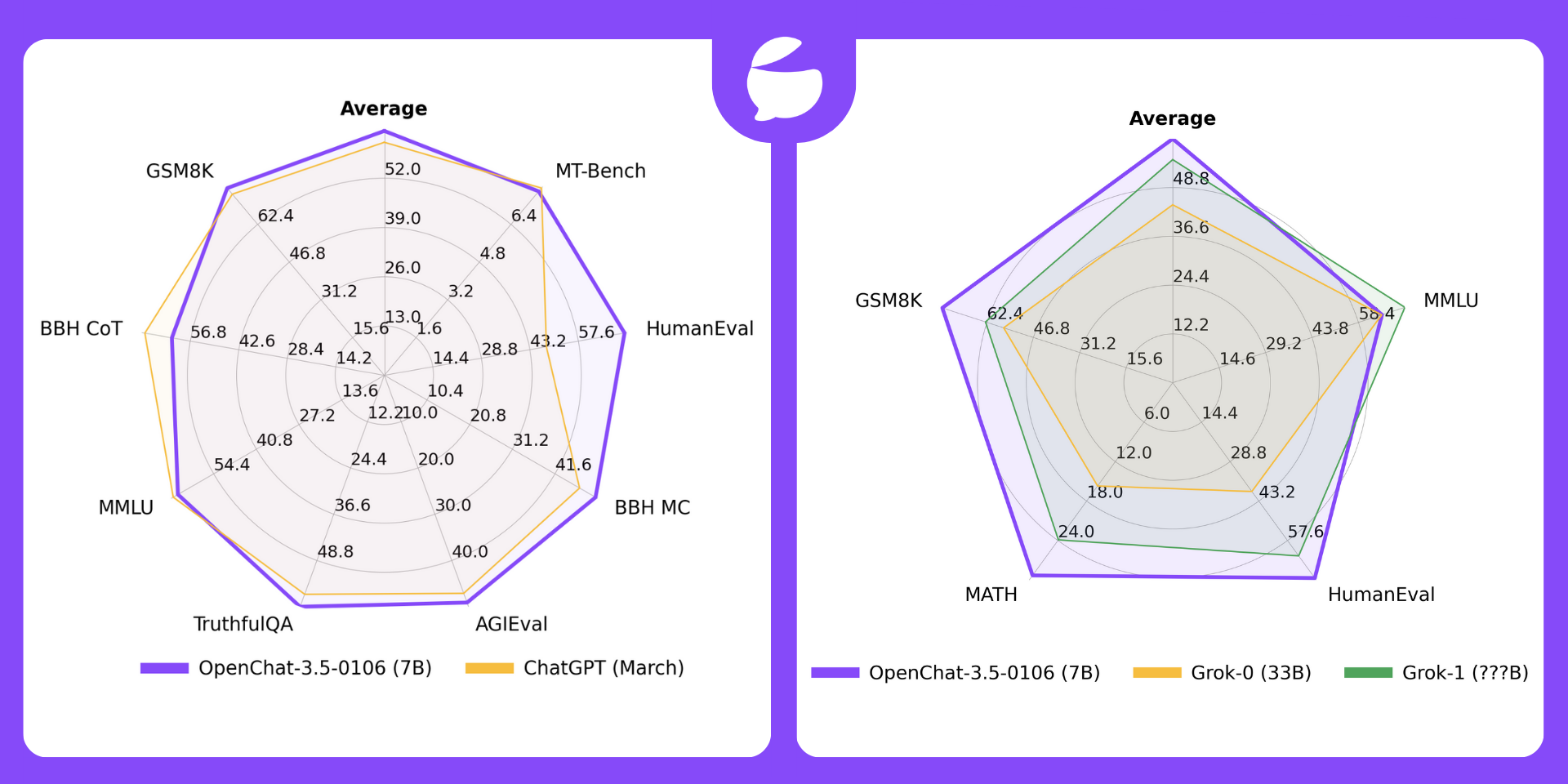
🏆 The Overall Best Performing Open Source 7B Model 🏆
🤖 Outperforms ChatGPT (March) and Grok-1 🤖
- OpenChat is an innovative library of open-source language models, fine-tuned with C-RLFT - a strategy inspired by offline reinforcement learning.
- Our models learn from mixed-quality data without preference labels, delivering exceptional performance on par with
ChatGPT, even with a7Bmodel which can be run on a consumer GPU (e.g. RTX 3090). - Despite our simple approach, we are committed to developing a high-performance, commercially viable, open-source large language model, and we continue to make significant strides toward this vision.
-
[2024/01/06] We released the second update, OpenChat 3.5 0106, further improved coding and overall performance 🏆.
-
[2023/12/10] We released the first update, OpenChat 3.5 1210, improved coding by 15 points 🚀.
-
[2023/11/01] We released the OpenChat-3.5-7B model, surpassing ChatGPT on various benchmarks 🔥.
-
[2023/09/21] We released our paper OpenChat: Advancing Open-source Language Models with Mixed-Quality Data.
Read more
-
[2023/09/03] We released the OpenChat V3.2 SUPER model.
-
[2023/08/04] We have launched an Online Demo featuring the latest version, OpenChat 3.2.
-
[2023/07/30] We are thrilled to introduce the OpenChat V3 model series, based on Llama 2, and now available for free for commercial use!
-
[2023/07/07] We released the OpenChat V2 model series.
-
[2023/07/01] We released the OpenChat V1 model series.
| Model | # Params | Average | MT-Bench | HumanEval | BBH MC | AGIEval | TruthfulQA | MMLU | GSM8K | BBH CoT |
|---|---|---|---|---|---|---|---|---|---|---|
| OpenChat-3.5-0106 | 7B | 64.5 | 7.8 | 71.3 | 51.5 | 49.1 | 61.0 | 65.8 | 77.4 | 62.2 |
| OpenChat-3.5-1210 | 7B | 63.8 | 7.76 | 68.9 | 49.5 | 48.0 | 61.8 | 65.3 | 77.3 | 61.8 |
| OpenChat-3.5 | 7B | 61.6 | 7.81 | 55.5 | 47.6 | 47.4 | 59.1 | 64.3 | 77.3 | 63.5 |
| ChatGPT (March)* | ???B | 61.5 | 7.94 | 48.1 | 47.6 | 47.1 | 57.7 | 67.3 | 74.9 | 70.1 |
| OpenHermes 2.5 | 7B | 59.3 | 7.54 | 48.2 | 49.4 | 46.5 | 57.5 | 63.8 | 73.5 | 59.9 |
| OpenOrca Mistral | 7B | 52.7 | 6.86 | 38.4 | 49.4 | 42.9 | 45.9 | 59.3 | 59.1 | 58.1 |
| Zephyr-β^ | 7B | 34.6 | 7.34 | 22.0 | 40.6 | 39.0 | 40.8 | 39.8 | 5.1 | 16.0 |
| Mistral | 7B | - | 6.84 | 30.5 | 39.0 | 38.0 | - | 60.1 | 52.2 | - |
| Open-source SOTA** | 13B-70B | 61.4 | 7.71 | 73.2 | 49.7 | 41.7 | 62.3 | 63.7 | 82.3 | 41.4 |
| WizardLM 70B | WizardCoder 34B | Orca 13B | Orca 13B | Platypus2 70B | WizardLM 70B | MetaMath 70B | Flan-T5 11B |
Evaluation details
*: ChatGPT (March) results are from GPT-4 Technical Report, Chain-of-Thought Hub, and our evaluation.^: Zephyr-β often fails to follow few-shot CoT instructions, likely because it was aligned with only chat data but not trained on few-shot data.
**: Mistral and Open-source SOTA results are taken from reported results in instruction-tuned model papers and official repositories.
All models are evaluated in chat mode (e.g. with the respective conversation template applied). All zero-shot benchmarks follow the same setting as in the AGIEval paper and Orca paper. CoT tasks use the same configuration as Chain-of-Thought Hub, HumanEval is evaluated with EvalPlus, and MT-bench is run using FastChat. To reproduce our results, follow the instructions below.
Reproducing benchmarks
Reasoning and Coding:
Note: Please run the following commands at the base directory of this repository.
python -m ochat.evaluation.run_eval --condition "GPT4 Correct" --model openchat/openchat-3.5-0106 --eval_sets coding fs_cothub/bbh fs_cothub/mmlu zs/agieval zs/bbh_mc_orca zs/truthfulqa_orca
python ochat/evaluation/view_results.py
python ochat/evaluation/convert_to_evalplus.pyThen all humaneval code samples are placed in ochat/evaluation/evalplus_codegen. Use the following command to evaluate an individual code sample named samples.jsonl using Docker as a sandbox.
docker run -v $(pwd):/app ganler/evalplus:latest --dataset humaneval --samples samples.jsonlMathematical Reasoning:
Note: Please run the following commands at the base directory of this repository.
python -m ochat.evaluation.run_eval --condition "Math Correct" --model openchat/openchat-3.5-0106 --eval_sets fs_cothub/gsm8k zs/math
python ochat/evaluation/view_results.pyMT-Bench:
Please first launch a local API server, then download FastChat and run the following commands.
Note: Due to non-zero temperature and GPT-4 API changes over time, there might be variations in the results.
cd fastchat/llm_judge
python gen_api_answer.py --model openchat-3.5-0106 --max-tokens 4096 --parallel 128 --openai-api-base http://localhost:18888/v1
python gen_judgment.py --model-list openchat-3.5-0106 --parallel 8 --mode single🎇 Comparison with X.AI Grok
🔥 OpenChat-3.5-0106 (7B) now outperforms Grok-0 (33B) on all 4 benchmarks and Grok-1 (???B) on average and 3/4 benchmarks.
| License | # Param | Average | MMLU | HumanEval | MATH | GSM8k | |
|---|---|---|---|---|---|---|---|
| OpenChat-3.5-0106 | Apache-2.0 | 7B | 61.0 | 65.8 | 71.3 | 29.3 | 77.4 |
| OpenChat-3.5-1210 | Apache-2.0 | 7B | 60.1 | 65.3 | 68.9 | 28.9 | 77.3 |
| OpenChat-3.5 | Apache-2.0 | 7B | 56.4 | 64.3 | 55.5 | 28.6 | 77.3 |
| Grok-0 | Proprietary | 33B | 44.5 | 65.7 | 39.7 | 15.7 | 56.8 |
| Grok-1 | Proprietary | ???B | 55.8 | 73 | 63.2 | 23.9 | 62.9 |
Note
Need pytorch to run OpenChat
pip3 install ochatImportant
If you are facing package compatibility issues with pip, try the conda method below or check this issue
conda create -y --name openchat python=3.11
conda activate openchat
pip3 install ochatsudo apt update
sudo apt install build-essential
sudo apt install -y curl
curl -o miniconda.sh https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash miniconda.sh
# Restart WSL terminal if the following conda command does not work
conda create -y --name openchat python=3.11
conda activate openchat
pip3 install ochatClone this repo and install openchat from source in editable mode
git clone https://github.com/imoneoi/openchat
cd openchat
pip3 install --upgrade pip # enable PEP 660 support
pip3 install -e . # Editable mode, you can make changes in this cloned repo⚡ Our API server is ready for production use and compatible with the OpenAI API protocol. It is highly optimized with vLLM and can dynamically batch requests.
📎 Note: For 20 series or older GPUs that do not support bfloat16, add --dtype float16 to the server args.
python -m ochat.serving.openai_api_server --model openchat/openchat-3.5-0106# N is the number of tensor parallel GPUs
python -m ochat.serving.openai_api_server --model openchat/openchat-3.5-0106 --engine-use-ray --worker-use-ray --tensor-parallel-size Nuse -h to see more settings
python -m ochat.serving.openai_api_server --model openchat/openchat-3.5-0106 -hDeploy as online service
If you want to deploy the server as an online service, you can use --api-keys sk-KEY1 sk-KEY2 ... to specify allowed API keys and --disable-log-requests --disable-log-stats --log-file openchat.log for logging only to a file. For security purposes, we recommend using an HTTPS gateway in front of the server.
Once started, the server listens at localhost:18888 for requests and is compatible with the OpenAI ChatCompletion API specifications.
💡 Default Mode (GPT4 Correct): Best for coding, chat and general tasks
curl http://localhost:18888/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "openchat_3.5",
"messages": [{"role": "user", "content": "You are a large language model named OpenChat. Write a poem to describe yourself"}]
}'🧮 Mathematical Reasoning Mode: Tailored for solving math problems
curl http://localhost:18888/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "openchat_3.5",
"condition": "Math Correct",
"messages": [{"role": "user", "content": "10.3 − 7988.8133 = "}]
}'🌐 Web UI - OpenChat-UI
After launching the API server, OpenChat provide user interface that easy to interact with. Click here to check Web UI
Warning
It's recommended to use our optimized API server for deployment. Inferencing with Transformers will be slower.
💡 Default Mode (GPT4 Correct): Best for coding, chat and general tasks
GPT4 Correct User: Hello<|end_of_turn|>GPT4 Correct Assistant: Hi<|end_of_turn|>GPT4 Correct User: How are you today?<|end_of_turn|>GPT4 Correct Assistant:
🧮 Mathematical Reasoning Mode: Tailored for solving math problems
Math Correct User: 10.3 − 7988.8133=<|end_of_turn|>Math Correct Assistant:
<|end_of_turn|> as end of generation token.
The default (GPT4 Correct) template is also available as the integrated tokenizer.chat_template, which can be used instead of manually specifying the template.
The OpenChat training system utilizes padding-free training and the Multipack Sampler, achieving a 3~10x speedup compared to the conventional padded training.
OpenChat supports Llama 2 and Mistral models. Please first choose a base model to fit your needs. Each base model has a corresponding weight repo, model type, and recommended batch size as listed below, they should be filled into BASE_REPO, MODEL_TYPE, and BATCH_SIZE in the following instructions.
| Base Model | Size | Weights (with EOT token) | Model Type | Recommended Batch Size per GPU (8xA100 80GB) |
|---|---|---|---|---|
| Mistral | 7B | imone/Mistral_7B_with_EOT_token |
openchat_v3.2_mistral |
77824 |
| Llama 2 | 7B | imone/LLaMA2_7B_with_EOT_token |
openchat_v3.2 |
77824 |
| Llama 2 | 13B | imone/Llama2_13B_with_EOT_token |
openchat_v3.2 |
36864 |
Note: The OpenChat conversation template requires an <|end_of_turn|> special token. The base model specified must include this token. Our provided weights are the original base weights with this token added. If you want to add them manually, use the convert_llama_weights_to_hf_add_tokens.py or mistral_add_tokens.py in the scripts directory.
First, ensure that the CUDA nvcc compiler is available in your environment. If it is not, install the CUDA toolkit that matches the version used by PyTorch.
Next, install building dependencies:
pip install packaging ninjaFinally, install the packages:
pip install deepspeed flash-attnTo utilize the OpenChat trainer, prepare your SFT data into a JSON Lines format where each line corresponds to a Conversation object:
class Message(BaseModel):
role: str # Must be "user" or "assistant"
content: str # Message content
weight: Optional[float] = None # Loss weight for this message. Typically 0 for user and 1 for assistant to supervise assistant's responses only
class Conversation(BaseModel):
items: List[Message] # All messages within the conversation
condition: str = "" # C-RLFT condition, can be any string or empty.
system: str = "" # System message for this conversationFor basic SFT, assign weight as 0 for human messages and 1 for assistant responses.
SFT example:
{"items":[{"role":"user","content":"Hello","weight":0.0},{"role":"assistant","content":"Hi","weight":1.0},{"role":"user","content":"How are you today?","weight":0.0},{"role":"assistant","content":"I'm fine.","weight":1.0}],"system":""}
{"items":[{"role":"user","content":"Who are you?","weight":0.0},{"role":"assistant","content":"I'm OpenChat.","weight":1.0}],"system":"You are a helpful assistant named OpenChat."}For C-RLFT, condition should be set as the class the conversation belongs to (e.g. GPT3 or GPT4). The weight is assigned as 0 for human messages and w for assistant responses, where w is the weight of the class (e.g. 0.1 for GPT3 and 1 for GPT4, as found in our C-RLFT paper).
C-RLFT example:
{"items":[{"role":"user","content":"What is C-RLFT?","weight":0.0},{"role":"assistant","content":"C-RLFT is a method for improving open-source LLMs with mixed-quality data.","weight":1.0}],"condition":"GPT4","system":""}
{"items":[{"role":"user","content":"What is C-RLFT?","weight":0.0},{"role":"assistant","content":"I don't know.","weight":0.1}],"condition":"GPT3","system":""}You'll then need to pre-tokenize the dataset using the command (please specify a filename as PRETOKENIZED_DATA_OUTPUT_PATH to store the pretokenized dataset):
python -m ochat.data.generate_dataset --model-type MODEL_TYPE --model-path BASE_REPO --in-files data.jsonl --out-prefix PRETOKENIZED_DATA_OUTPUT_PATHYou can now launch the OpenChat trainer using the command below.
- 13B model requires eight
A/H100swith 80GB VRAM - 7B model can be trained with four
A/H100swith 80GB VRAM or eightA/H100swith 40GB VRAM.
For hyperparameters, we recommend first setting the batch size to the recommended batch size. If OOM occurs, try setting it to the exact maximum that VRAM can hold and as a multiple of 2048.
Other hyperparameters have been carefully selected as the default. Furthermore, the learning rate is automatically determined based on the inverse square-root rule.
Training Commands (click to expand)
NUM_GPUS=8
deepspeed --num_gpus=$NUM_GPUS --module ochat.training_deepspeed.train \
--model_path BASE_REPO \
--data_prefix PRETOKENIZED_DATA_OUTPUT_PATH \
--save_path PATH_TO_SAVE_MODEL \
--batch_max_len BATCH_SIZE \
--epochs 5 \
--save_every 1 \
--deepspeed \
--deepspeed_config ochat/training_deepspeed/deepspeed_config.jsonYou can find checkpoints of all epochs in PATH_TO_SAVE_MODEL. Then you may evaluate each epoch and choose the best one.
Despite its advanced capabilities, OpenChat is still bound by the limitations inherent in its foundation models. These limitations may impact the model's performance in areas such as:
- Complex reasoning
- Mathematical and arithmetic tasks
- Programming and coding challenges
OpenChat may sometimes generate information that does not exist or is not accurate, also known as "hallucination". Users should be aware of this possibility and verify any critical information obtained the model.
OpenChat may sometimes generate harmful, hate speech, biased responses, or answer unsafe questions. It's crucial to apply additional AI safety measures in use cases that require safe and moderated responses.
Our OpenChat 3.5 code and models are distributed under the Apache License 2.0.
| Model | Size | Context | Weights | Serving |
|---|---|---|---|---|
| OpenChat 3.5 0106 | 7B | 8192 | Huggingface | python -m ochat.serving.openai_api_server --model openchat/openchat-3.5-0106 --engine-use-ray --worker-use-ray |
| OpenChat 3.5 1210 | 7B | 8192 | Huggingface | python -m ochat.serving.openai_api_server --model openchat/openchat-3.5-1210 --engine-use-ray --worker-use-ray |
| OpenChat 3.5 | 7B | 8192 | Huggingface | python -m ochat.serving.openai_api_server --model openchat/openchat_3.5 --engine-use-ray --worker-use-ray |
The following models are older versions of OpenChat and have inferior performance compared to the latest version. They will be deprecated in the next release. Please note that OpenChat V1 and V2 series are now deprecated, please install 3.1.x for using V1 and V2 models
To run the models on multiple GPUs with smaller VRAM, you can enable tensor parallelization, for example, using the --tensor-parallel-size 2 flag.
| Model | Size | Context | Weights | Serving |
|---|---|---|---|---|
| OpenChat 3.2 SUPER | 13B | 4096 | Huggingface | python -m ochat.serving.openai_api_server --model openchat/openchat_v3.2_super --engine-use-ray --worker-use-ray |
@article{wang2023openchat,
title={OpenChat: Advancing Open-source Language Models with Mixed-Quality Data},
author={Wang, Guan and Cheng, Sijie and Zhan, Xianyuan and Li, Xiangang and Song, Sen and Liu, Yang},
journal={arXiv preprint arXiv:2309.11235},
year={2023}
}
Project Lead:
- Guan Wang [imonenext at gmail dot com]
- Alpay Ariyak [aariyak at wpi dot edu]
Main Contributors:
- Sijie Cheng [csj23 at mails dot tsinghua dot edu dot cn]
- Xianyuan Zhan (Tsinghua University)
- Qiying Yu (Tsinghua University)
- Changling Liu (GPT Desk Pte. Ltd.)
- LDJ
- AutoMeta (Alignment Lab AI)
Sponsors:
- Sen Song (Tsinghua University)
- Yang Liu (Tsinghua University)
- 01.AI Company
- RunPod
Special Thanks: