Test the benefits of Rabin Fingerprinting vs normal chunking #137
Comments
|
cc @20zinnm |
|
I found that Rabin did great with historical archives, i.e. where you have the same thing at different points in time (archive.org style). Using Rabin, you could potentially reduce archives of websites (WARCs) by significant amounts. However, in some cases a diff might be more applicable. |
|
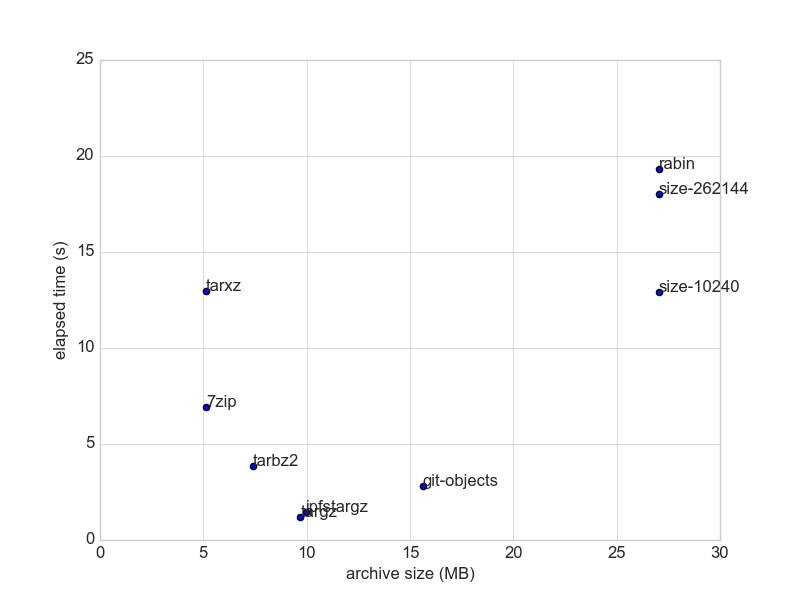
ahem (cleanse throat), here is one benchmark (using nixpkgs narinfo [1], 20k of 10KB files, data size: 22.5MiB)
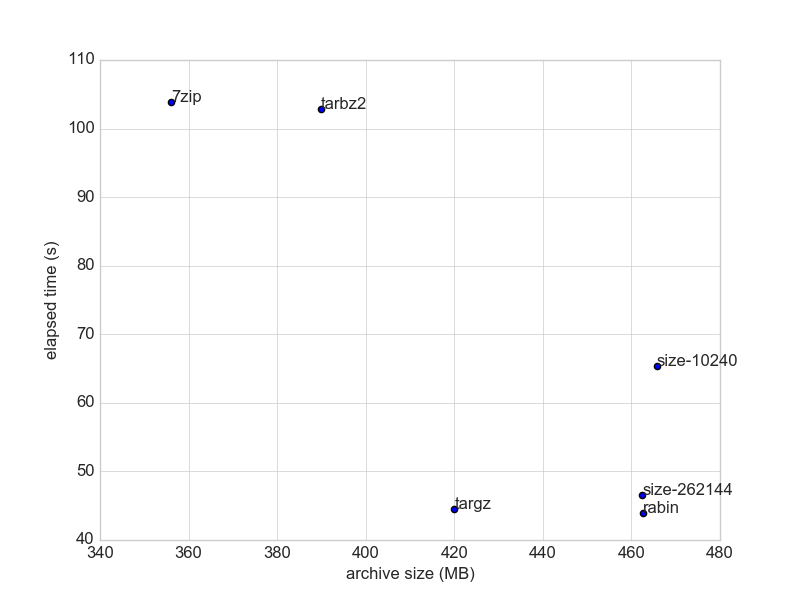
, and here is another (using president's daily brief [2], 2.5k of 200-600KB files, data size: 481.95MB)
In at least two datasets, the default chunker (size-262144) and rabin chunker did not provide significant compression (<10%). Therefore, what should an archivist use? (internetarchive uses torrent for distributing the data) Code to reproduce: https://github.com/rht/sfpi-benchmark/tree/master/chunk [1] ipfs/kubo#3621, https://ipfs.io/ipfs/QmcsrSRuBmxNxcEXjMZ1pmyRgnutCGwfAhhnRfaNn9P94F |
|
@rht thank you for taking a stab at this. Please compare the two ipfs chunking algorithms (default vs rabin)I wasn't clear in the description of this issue. This issue is not seeking to compare ipfs against other tools. It's seeking to compare two of the chunking algorithms that are already implemented in ipfs. We are trying to see if the rabin fingerprinting option on This is, in part, so we can decide whether we should implement some other, more efficient, chunking algorithm. To that point, the git-objects number is quite interesting to me because it tells us we might want to implement something that imitate's git's packing strategy. You only included it in the first graph, so the results are inconclusive, but it's an interesting data point. Please remove comparisons to compression algorithmsWe are not looking to compare rabin fingerprinting against compression algorithms like gzip -- those two technologies were designed for different purposes, so the comparison is confusing rather than useful. Cite your Source Data and Describe its CharacteristicsInformation we need in order to know what benchmarks are telling us:
Rabin fingerprinting is designed to deduplicate content at the block level. It's ideal for data that is repetitive, like version histories of data that have changed gradually over time. The fingerprint algorithm catches that duplication at the level of blocks, with a default block size of 256kb. For that reason, I would not expect it to catch much duplication in something like a series of speeches because speeches repeat words and sentences but they've very unlikely to precisely repeat 256k blocks of content. Use a Variety of Test DataI recommend using a variety of test data -- some with a lot of repetition that rabin fingerprinting should catch, others with less repetition. For example, in one test you could use sample data that contains many copies of the same file with varying sizes of edits to the file. In another test you could use a series of speeches, like you did in the first test run. If you choose a variety of test data like that it will give us a better basis for analyzing the results. |
|
@flyingzumwalt addressing your points. I am curating the benchmark (facts) not just for the sake of the maintainers, but also archivists, institutions, etc looking to store large datasets using the IPFS protocol. I believe I have the right to put informative datasets to locate the performance of ipfs storage within the archiving tools ecosystem. What is the point of having a graph that shows "chunking algorithm x does better than chunking algorithm y by such amount" (but hides the order of magnitude of the overall improvement of storage saving compared to the existing archival tools?). For archivists, such benchmark is much clearer and transparent to parse (and used as premises) than a fuzzy statement to the point that one is led to say "using Rabin, you could potentially reduce archives of websites (WARCs) by significant amounts". I have added the citations and code to reproduce (though I already stated what the dataset is and already described the characteristics).
For the narinfo data, the schema is a key-value map, and they all share the same key. For archival purpose (store many, read occassionally), it is always worth it to use the more expensive compression algorithm (7z/bz2 over gz).
My data choice and variety are constrained by the disk space I have on my own device, the variety of the pinned data in archives.ipfs.io, and whether I could practically download them w/ |
|
TL;DR: Given the storage size ballooning due to pinning, the very specific data-saving condition of the chunking, the ipfs toolset is not ready for large data archival (this statement is backed by data). Corollary: it is dishonest if it is marketed by protocol labs as otherwise. |
|
@rht You're violating our code of conduct. This is not the first time. I'm not willing to tolerate being bullied in this way and I completely disagree with your repeated, baseless implications that people are being dishonest or trying to hide information. We make huge efforts to operate in transparent ways and to provide people with good information. There are plenty of ways to press for better information without falsely and baselessly accusing people of bad intentions. We want everyone to help us make sure that we're providing the best possible information in transparent ways, but you must also respect our need to maintain a Friendly, Harrassment-free Space. For the record, I like the idea of the benchmarks you're proposing. To do those benchmarks properly would require proper planning. Due to the tone of this conversation, I'm unable to help you with that work. |
|
I've done some experiments on the modarchive dataset (#73). I'd assumed rabin might show an improvement since it's thousands of files with an awful lot of recycled soundfont samples. For a small directory, with files 35KB or less, adding Using With a much larger set of files (file size up to 3MB) adding And not intended as a comparison, but just to show there's quite a lot of duplicate data hiding there: Lastly, I added the entire directory tree with Anyway, results are a bit of a letdown but I hope the data is worth something. |
|
Thank you very much. We should evaluate rebin chunker as it should provide better results. So far it looks like it might be better as no-op. |
|
Wow. Thanks @flussence. This confirms our suspicions that the current rabin fingerprinting chunker might just slow things down without any benefit. Bummer. Like @Kubuxu said, we will have to look into why it's not providing more benefits. I'm confident that we will be able to develop better chunking algorithms over time and I suspect that the choice of chunking algorithm will be highly dependent on the type of data and the use cases surrounding the data (ie. many incremental edits vs. accumulation of new info over time, etc.) For now I think we can close this specific issue because we have our answer to the original question in this issue: With the current code base, the rabin chunker isn't worth it. People should just use the default chunking algorithm until someone improves the rabin chunker or publishes an awesome alternative chunker. I'm still intrigued by the types of benchmarks that @rht started pushing for. Before closing this current issue I'd like to create a separate issue flagging the need for us to do those broader, farther-reaching benchmarks in a carefully planned, repeatable way. Can anyone help me figure out how to characterize what questions @rht was trying to answer with those tests? Based on that I can write a new issue that describes the questions and sketches how the tests might be structured. |
|
Hey @flussence, thank you so much for the data! If you don't mind, could you try out a few other things? The rabin chunker does accept parameters (though, horribly documented, i had to go diving through the source before writing this comment to figure it out). Examples: The average value should be a power of two (otherwise it gets truncated to one), the min and max can be any numbers so long as they are lower and higher than the average, respectively. Could you try out some different parameters to rabin? Perhaps try a much smaller average size to start, maybe 1024, then 16386, then maybe 64k ? |
|
@whyrusleeping that seems to make it even worse, somehow... Numbers are for the /ahx/ directory -
Not only are the smaller chunk sizes larger overall, they seem to get exponentially slower. The last two were adding files at more or less dialup modem speeds, and they seem to be entirely disk IO-bound too - I'm not sure what's happening there. |
|
@flussence the slow down was very likely because it caused ipfs to create a much large number of objects, the cost of storing each object has a base cost (something like Disappointing that rabin fingerprinting isnt showing any gains here... |
The real goal here is to figure out which chunking algorithm(s) are ideal for archiving datasets so that we can recommend those chunking algorithms in any instructions we provide to archivists and data rescuers.
As @Kubuxu said in #134 (comment)
@Kubuxu could you provide suggestions about how you would test/compare these options?
The text was updated successfully, but these errors were encountered: