智能运维,即AIOps(Artificial Intelligence for IT Operations),将人工智能应用于运维领域,基于已有的海量的运维数据(日志、监控信息、应用信息等),通过机器学习总结与提炼规则,将实际问题转化为算法问题,将通过机器学习得到的模型应用到运维场景中,进一步解决自动化运维没办法解决的问题。1
AIOps的建设是不断升级的过程,并且注重已有成果("学件"[^学件])的复用与迁移1:
st=>start: 无AI
e=>end: 智能运维
op1=>operation: 局部单点探索
op2=>operation: 单点能力完善
op3=>operation: 局部运维AI"学件"|current
op4=>operation: 学件组合or AI单点
st->op1(right)->op2(right)->op3(right)->op4->e
AIOps的演化过程中有一个能力分级

最终能实现的例子:
- 智能化的监控预测及告警
- 免干预的自动化扩缩容
- 免干预的性能调优
- 免干预的成本组成调优
- awesome-AIOps
- aiops-handbook
- 时间序列异常检测
- 日志异常检测
- 日志分析算法Paper 值得一提的是,老师提供的参考skywalking归属于根因分析的调用链一块.
调研说明:作为智能运维Collector和aggregator的部分成员主要调研Prometheus的存储机制.
2.1. Prometheus简介
Prometheus是新一代的云原生监控系统,提供开源的完整监控解决方案.其对传统监控系统的测试和告警模型进行了彻底的颠覆,形成了基于中央化的规则计算、统一分析和告警的新模型。
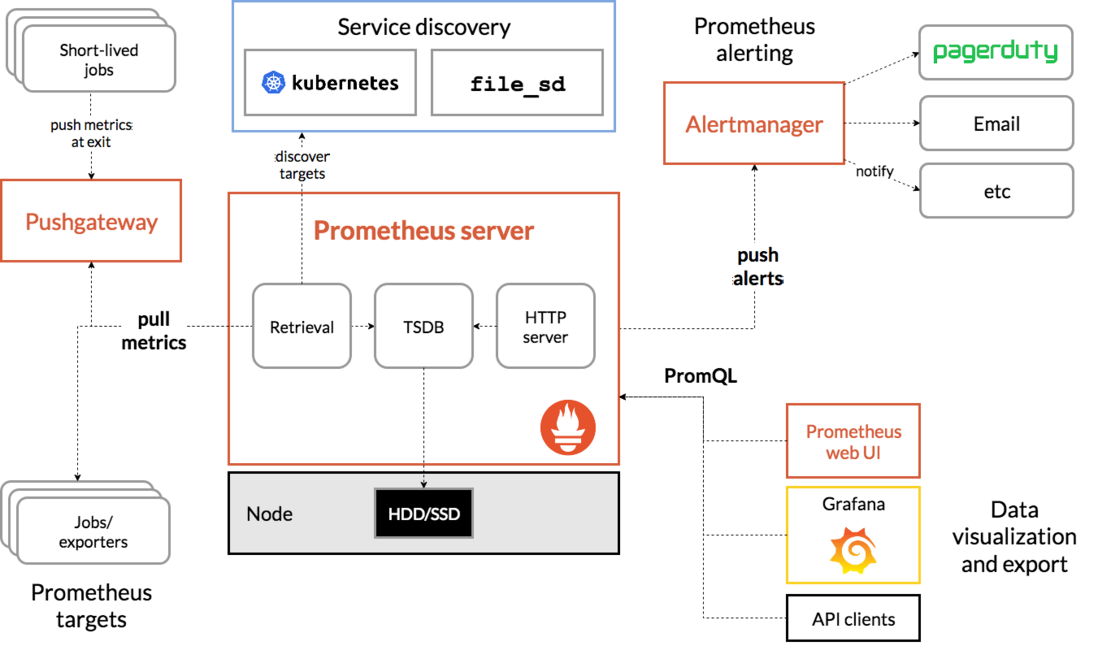
Retrieval/Ingestion负责定时去暴露的目标页面上去抓取采样指标数据Storage负责将采样数据写磁盘PromQL是Prometheus提供的查询语言模块 
易于管理 Prometheus核心部分只有一个单独的二进制文件,不存在任何的第三方依赖(数据库,缓存等等)。唯一需要的就是本地磁盘,因此不会有潜在级联故障的风险。 强大的数据模型 所有采集的监控数据均以指标(metric)的形式保存在内置的时间序列数据库当中(TSDB),可以方便地对监控数据进行聚合,过滤,裁剪。 内置的强大查询语言PromQL Prometheus 通过PromQL可以实现对监控数据的查询、聚合。同时PromQL也被应用于数据可视化(如Grafana)以及告警当中。 通过PromQL可以轻松回答类似于以下问题:
- 在过去一段时间中95%应用延迟时间的分布范围?
- 预测在4小时后,磁盘空间占用大致会是什么情况?
- CPU占用率前5位的服务有哪些?(过滤)
Prometheus有着高效的时间序列数据存储方法,每个采样数据仅仅占用3.5byte左右空间,上百万条时间序列,30秒间隔,保留60天,只需200多G3. Prometheus 1.x版本的TSDB(V2存储引擎)基于LevelDB,并且使用了和Facebook Gorilla一样的压缩算法,能够将16个字节的数据点压缩到平均1.37个字节。4 如果需要对Prometheus Server的本地磁盘空间做容量规划时,可以通过以下公式计算:
磁盘大小 = 保留时间 * 每秒获取样本数 * 样本大小
本地存储(15天)带来了简单高效的存储体验,但尽管压缩数据的能力强大,单节点存储不可避免:
- 可扩展性差
- 只能用于短期窗口的timeseries数据保存和查询
- 数据不持久,无法存储大量历史数据
- 不具有高可用性(宕机会导致历史数据无法读取) 为了解决单节点存储的限制,prometheus没有自己实现集群存储,而是提供了远程读写的接口(remote_write/remote_read),让用户自己选择合适的时序数据库来实现prometheus的扩展性,工作方式主要是5
- Prometheus 按照标准的格式将metrics写到远端存储
- prometheus 按照标准格式从远端的url来读取metrics

最原始的抓取数据上来看,基本如下图: 
- timestamp是当前抓取时间戳
- 每个Metric name代表了一类的指标,他们可以携带不同的Labels
- 每个Metric name + Label组合成代表了一条时间序列的数据
数据存储细节 对于时间序列的基本特性来说,通常是过去的数据一般是只读的,是不会变更的,当前时间的数据才会可能写.故时间序列的存储可以设计成key-value存储的方式(基于BigTable): 
在Prometheus的世界中,无论是内存还是磁盘,它都是以1KB单位分成块来操作的2。它按2小时一个block进行存储,每个block由一个目录组成4:
- 一个或者多个chunk文件(保存timeseries数据)
- 一个metadata文件
- 一个index文件(通过metric name和labels查找timeseries数据在chunk文件的位置)
最新写入的数据保存在内存block中,达到2小时后写入磁盘。为了防止程序崩溃导致数据丢失,实现了WAL(write-ahead-log)机制,启动时会以写入日志(WAL)的方式来实现重播,从而恢复数据。 删除数据时,删除条目会记录在独立的tombstone文件中,而不是立即从chunk文件删除。
通过时间窗口的形式保存所有的样本数据,可以明显提高Prometheus的查询效率,当查询一段时间范围内的所有样本数据时,只需要简单的从落在该范围内的块中查询数据即可。
这些2小时的block会在后台压缩成更大的block,数据压缩合并成更高level的block文件后删除低level的block文件。
社区已经实现了对于Prometheus以下的远程存储方案4:
- AppOptics: write
- Chronix: write
- Elasticsearch: write
- InfluxDB: read and write
- OpenTSDB: write
- PostgreSQL/TimescaleDB: read and write
- clickhouse: read and write
部分成果如"存储底层"部分整合在了时间序列数据库调研之InfluxDB
机器学习算法加一个互联网公司的数据(或者NASA的),做一个符合metis学件规约的学件出来.可以直接集成一个时间序列数据库,里面存着各种指标的时间序列,不同的学件按照自己的算法需要,自己去读想要的序列值(数据规约);算力不够改成分布式的
4.1. 成熟的开源产品6
Metis 是智能运维领域的首个开源产品,旨在通过算法从海量运维数据中学习摸索规则,逐步降低对人指定规则的依赖,减少人为失误。目前,Metis在运维质量、效率、成本三个方面逐步构建出成熟的智能化运维场景.
4.2. 应用场景多,潜力巨大7
- 1. 业务高质量保障
利用机器学习技术,进行异常检测、故障定位、瓶颈分析等,可在无人工干预下,智能地保障业务高质量运行。场景有:
- 时间序列异常检测
- DLP 生死指标监控
- 多维下钻
- 关联分析
- ROOT 根源分析
- 2. 运维效率提升
利用自然语言处理、机器学习技术,深挖智能问答、智能变更、智能决策,显著地提升运维人员的效率。场景有:
- 智能客服机器人
- 舆情监控
- 智能负载均衡
- 数据库调参
- 极限调度等场景
- 3. 成本优化管理 利用大数据智能分析技术,进行资源(设备、带宽、存储)管理,可迅速分析资源使用的明细,并通过横向大数据对比挖掘可优化点。
- 此外还有智能检测、通用模型和规则学习,潜力巨大
metis没有DB层,只提供了/app/dao的数据库实例层.存储层主要依赖于django的orm模型,将数据抽象为对象存储,从外面调数据.如netman里的时间序列的数据传进metis. 我们数据持久化的工作相当于做一个缓冲层(集成进一个时间序列数据库)来对数据存储并处理,在此基础上看了下api的接口,metis的api不多,接口请求参数或传入参数是python字典或结构体这样. 或者另外的手段就是将netman的算法放到学件提供的算法模块中,将netman的时间序列数据直接传进metis.
它通过建模随机变量的时间相关性对多元时间序列进行异常检测. OmniAnomaly是一个随机的递归神经网络模型,它将门控递归单元(GRU)和变分自动编码器(VAE)粘合在一起,其核心思想是学习多元时间序列的正态分布,并利用重构概率进行异常判断。 数据集包括三个部分:
- NASA的土壤水气主动无源卫星SMAP,以及火星科学实验室的漫游者号
- 互联网公司的五周长数据集SMD(实际有的)
SMD来自20台机器,也就有28个子集,维度为38,总异常率4.16%,相比NASA的数据集低了超过60%.SMD分为50%的训练集和50%的测试集,
测试集中提供测试标签标志异常:单/多时间序列异常检测, 提供维度解释标签标志不同维度对异常判断的贡献:多维数据的根因定位

一组指标作为一个向量,重构概率越高越好.
算法如何调用?接口在哪? 各个维度是什么?能对接吗?
- Metis
- 当前检测时间窗口选取为3小时,每分钟1个数据点,即窗口值为180
- 2、率值检测:适用于正态分布类型数据的检测,使用无监督算法进行检测,如成功率等生死指标数据的检测----源数据
- 1、量值检测:适用于大多数KPI指标数据的检测,使用无监督o和有监督联合检测,会加载检测模型----tset_labels
- 数据准备
调用
utils中的get_data()
- 传入数据集,最大训练大小,最大测试大小,是否打印日志,是否做预处理,训练集与测试集的起始位置
- 返回
(train_data, None), (test_data, test_label)
- 调用构造函数
model = OmniAnomaly(config=config, name="model")- 传入the model under
variable_scopenamed 'model' - 返回一个model
- 传入the model under
- 构造训练者
trainer = Trainer(model=model,
model_vs=model_vs,
max_epoch=config.max_epoch,
batch_size=config.batch_size,
valid_batch_size=config.test_batch_size,
initial_lr=config.initial_lr,
lr_anneal_epochs=config.lr_anneal_epoch_freq,
lr_anneal_factor=config.lr_anneal_factor,
grad_clip_norm=config.gradient_clip_norm,
valid_step_freq=config.valid_step_freq)- 构造预测者
predictor = Predictor(model, batch_size=config.batch_size, n_z=config.test_n_z,
last_point_only=True)- 存储来自
save_dir的变量 - 训练模型
train_start = time.time()
best_valid_metrics = trainer.fit(x_train)
train_time = (time.time() - train_start) / config.max_epoch
best_valid_metrics.update({
'train_time': train_time
})- 得到来自POT算法的训练集结果
- 解析
argumens - 处理得到的结果对象并预览
- SPOT类:在单变量数据集上运行SPOT算法(upper bounds)
-
定义SPOT对象
-
给SPOT对象提供数据包括添加数据
def add(self, data): -
初始化
-
def _rootsFinder(fun, jac, bounds, npoints, method):
Find possible roots of a scalar function -
def _log_likelihood(Y, gamma, sigma):
Compute the log-likelihood for the Generalized Pareto Distribution (μ=0)- 寻找所有可能的根
-
def _grimshaw(self, epsilon=1e-8, n_points=10):
Compute the GPD parameters estimation with the Grimshaw's trick -
def _quantile(self, gamma, sigma):
Compute the quantile at level 1-q -
根据运行的结果画图
-
- biSPOT类:在单变量数据集上运行biSPOT算法(upper and lower bounds)
- dSPOT类:在单变量数据集上运行DSPOT算法(upper bounds)
- bidSPOT类:在单变量数据集运行DSPOT算法(upper and lower bounds)
学习思路

- SPOT类:在单变量数据集上运行SPOT算法(upper bounds)
-
定义SPOT对象
-
给SPOT对象提供数据包括添加数据
def add(self, data): -
初始化
-
def _rootsFinder(fun, jac, bounds, npoints, method):
Find possible roots of a scalar function -
def _log_likelihood(Y, gamma, sigma):
Compute the log-likelihood for the Generalized Pareto Distribution (μ=0)- 寻找所有可能的根
-
def _grimshaw(self, epsilon=1e-8, n_points=10):
Compute the GPD parameters estimation with the Grimshaw's trick -
def _quantile(self, gamma, sigma):
Compute the quantile at level 1-q -
根据运行的结果画图
-
- biSPOT类:在单变量数据集上运行biSPOT算法(upper and lower bounds)
- dSPOT类:在单变量数据集上运行DSPOT算法(upper bounds)
- bidSPOT类:在单变量数据集运行DSPOT算法(upper and lower bounds)
主要是功能二次封装(如apeend())寻根-拟合树(日志相似性)-剪枝(GPD参数)-计算得到结果-绘图 有个问题就是对于Omni所使用算法的学习的确有些力不从心,于是关注Metis的一些问题.
于是找Metis自己训练模型与数据的接口,不过完整的接口文档暂时没有找到.
- metis以过去一周/过去一天/过去180min这样的形式去判断是否为异常点有理论支撑么? 进行时间序列异常检测是需要使用历史数据的。一般情况下可以选择历史14天的数据,或者历史一周的数据。或者选择其中的一个时间序列切片,正如这个项目所示。 关于有监督方法或者特征工程,
- 开源工具:tsfresh,tsfresh is a python package. It automatically calculates a large number of time series characteristics, the so called features. Further the package contains methods to evaluate the explaining power and importance of such characteristics for regression or classification tasks.
- 论文:清华大学裴丹教授在2015年发表的 Opprentice 系统
- blog: 时间序列简介(一) 如何理解时间序列?— 从 Riemann 积分和 Lebesgue 积分谈起 时间序列的自回归模型—从线性代数的角度来看 做时间序列的特征与做推荐系统的特征有类似之处,更多的是结合自身的业务场景,针对自身的时间序列走势和趋势,甚至对正负样本的理解,在通用特征的基础上,做一些贴近业务的特征。在数据选择方面,可以根据自身的需求选择最合适的数据。
- 单节点的Metis异常检测学件能支持多少条时序曲线的并发?
(Kafka)->InfluxDB->Metis 多指标的数据应该都可以使用Omni算法,单指标的数据也可以,只是基于Meits自己的规约不好改造,接口文档也缺失,所以转向对集成数据库的研究与应用比较靠谱.
- 自己暂停了Omni算法的研究:多指标;缺少文档;较为陌生.开会后转向看InfluxDB,kafka暂时没接触
- 尝试跑了一下InfluxDB,在之前基础上完善了一下文档:https://www.yuque.com/uuavi8/mc67cr/utkeib
- 官方说明:内部用的moniter时序存储,支持200w以上指标。monitor存储方案本质上是分布式的kv存储,开源的方案有hbase,influxdb等。在内部使用自研的存储方案基于多阶hash表实现,并做了冷热数据分离。2天内的热数据存储在内存,2天前的冷数据转存到文件。应用于智能检测时为提升检测性能,每天定时将历史数据从冷数据存储批量拉入执行检测的机器的内存中,实时的时序数据每分钟从分布式内存存储中拉取,从而实现基于内存数据的高并发异常检测。
- Metis使用
sklearn + tsfresh从中选了一些比较简单的特征- tsfresh:一个时间序列特征提取的库
- 有一些是 Opprentice 里使用了一些拟合特征
- 有一些是结合自身业务所写的同环比类特征,其函数是 time_series_periodic_features
- 有监督学习模型使用的是开源的 GBDT 和 XGBoost;量值检测:是无监督 + 有监督;率值检测:是无监督 在有监督算法前加上统计判别算法和无监督算法进行数据的过滤,只有当第一层输出异常的时候,才会给有监督算法进行判断
Kafka在设计之初作为日志流平台和运营消息管道平台,作为消息中间件它可实现消息顺序和海量堆积能力.其典型的使用场景如下:
- 数据管道和系统解耦。
- 异步处理和事件驱动。
- 流量削峰。
- 事务消息和分布式事务的最终一致性。
Broker: 缓存代理,Kafka集群中一台或多台服务器Topic:区分Kafka的消息类型,将不同的消息写到不同的Kafka Topic中Partition:Topic物理上的分组,一个Topic可以分为多个Partition,每个Partition都是一个有序的队列.Partition中的每条消息都会被分配一个有序的id(offset)Producer:消息生产者Consumer:消息消费者Consumer Group: 每一组消费者都有相同的Group id,这样可以保证多个消费者不重复消费同一条消息
Kafka数据的写入和读取是顺序的。根据局部性原理,在实际测试中,磁盘顺序写入和随机写入的性能比相差最大可达6000倍8.Kafka之所以能做到如此,主要是
- 把磁盘中的数据缓存到内存中,把对磁盘的访问变为对内存的访问,同时这种
Page Cache中的数据会按照一定的策略更新到磁盘。 - 将数据直接从磁盘文件复制到网卡设备中,而不需要经由应用程序之手。从而大大减少内核和用户模式之间的上下文切换,这种零拷贝技术依赖于底层的 sendfile() 方法实现。
Kafka顺序读写磁盘,使用NIO网络模型支持数千个客户端同时读/写.传统的 BIO 通过socket.read()读取服务端的数据,如果TCP RecvBuffer里没有数据,函数会一直阻塞,直到收到数据。当有很多客户端访问服务端,但客户端未发送数据,服务端线程处于线程阻塞,等待客户端响应,在大量并发的情况下,可能会导致服务端崩溃。所以诞生了NIO网络模型:

- 非阻塞式I/O模型。(服务器端提供一个单线程的Selector来统一管理客户端socket接入的所有连接,并负责每个连接所关心的事件)
- 弹性伸缩能力强。(服务器端不再是通过多个线程来处理请求,而是通过一个线程来处理所有请求,对应关系变为 N:1)
- 单线程节省资源。(线程频繁创建、销毁,线程之间的上下文切换等带来的资源消耗得要缓解)
官方诚言:
算法的角度来讲,最理想的是 14 天的全部数据,但是在百万时间序列的量级上,就要考虑窗口的长度了。
所以事实上Metis考虑到线上的计算压力,也不得不对数据做了较多规约.目前实现分布式的Metis似乎还没苗头.为了实现高并发异常检测,Metis在内部使用自研的存储方案,基于内存将实时的时序数据每分钟从分布式内存存储中拉取,又因为内存有限,从而以两天为界,做了内存热数据和磁盘冷数据划分,并定时将历史数据从冷数据存储批量拉入执行检测的机器的内存中.Metis内部的做法其实与Kafka不谋而合.Kakfa据消费的实时性将消息消费者行为划分两类8:
- 实时消费者:对数据实时性要求较高,需要采用实时消费消息的方式。在实时消费的场景下,Kafka会利用系统的
page cache缓存,生产消息到broker,然后直接从内存转发给实时消费者,磁盘压力为零。 - 离线消费者:又名定时周期性消费者,消费的消息通常是数分钟前或是数小时前的消息。而这类消息通常存储在磁盘中,消费时会触发磁盘的IO操作。
这实际上对应的就是热读与冷读流量.所以InfluxDB->(Kafka)->Metis可行.
对于传统的电商业务,实际运行中发现流量峰值时Kafka集群IO压力会很大,扩容也只能暂时解决问题。理论上集群的读压力不应该这么大,因为大部分的读压力应该命中Page Cache,不应该再从磁盘里面读取。但因为客户存在多个业务消费同一份消息的业务场景,冷读与热读并发消费同一个集群,就会使得落盘数据和实时数据会频繁的换入换出内存,增加实时业务的响应时延;同时磁盘IO的高触发也会使得集群不稳定.为了缓解传统业务集群的IO压力占比最大的磁盘读压力,还需要做冷热数据连接方案,即加入Connector集群.其将离线业务消息按照主题维度从实时集群同步到离线集群中,和实时消费者保持一致,在流量高峰时也保证冷读尽可能与热读分离,冷读主要依靠冷读集群完成.
不过作为时序数据库与Metis之间的中间件,Metis的业务暂时未涉及到冷热数据并发处理情况,只是分为分钟持续与每天定时拉取数据,目前并不需要
Connector集群.
这篇How companies integrate Kafka with InfluxDB to create tolerant, scalable, fast and simplified data streams提到Hulu 和Wayfair团队的实践.
Hulu声称它们可以做到每秒导入100万条指标数据9,并且通过全新的重定向技术保证可以处理任何有问题的InfluxDB集群.Hulu官方给了一个架构图:

而Wayfair在2017年经过波士顿,西雅图和爱尔兰跨球集群之间海量时间序列数据连接的复杂探索:

最终选择了在InfluxDB和Kafka基础上重构以Kafka为中心的管道来集成来自三个不同数据中心(包括每个安全区域和非安全区域)的指标数据:

InfluxData’s Telegraf service made it relatively easy to configure a multi-layered pipeline by which applications could send data to Telegraf and allow Telegraf to pipe it into Kafka for later consumption. In practice we are using Telegraf twice: One layer to receive raw InfluxDB line protocol from applications via UDP and forward it on to Kafka, and an additional layer to consume metrics from the Kafka buffer and write to InfluxDB.
于是发现InfluxData团队已经开发了Telegraf服务来帮助在Kafka和InfluxDB之间导出和导入数据.
事实上Telegraf能连接各种数据源比如 MongoDB, MySQL, Redis,还有包括Kafka这样的消息队列然后进行收集和再次发送数据.官方称Telegraf可以扮演Agent和Collector和Ingest Pipeline来减少对于大量数据来源情况下写操作的请求数量,而其本身是 plugin-driven驱动的服务器.

2019年5月7日–InfluxDat发布了InfluxDB Cloud 2.0.InfluxDB Cloud 2.0集成了Kafka10,实现高效稳健容忍度高.当客户将一批指标点写入Kafka层时,数据将分配给拥有分区的Kafka生产者,在此处被短暂保存,而不是立即写入Kafka分区。 Kafka生产者保留数据,直到生产者有足够大的批量来写。 Kafka生产者可以保留不断增长的批次,同时将其他批次的数据写入Kafka分区,从而使存储引擎可以有效地处理大量数据,而不必处理来自单个客户端的少量数据。同样,当客户端写入WAL11时,不会阻塞它们在存储层中。事实上,预先写入日志或WAL是几乎每个性能数据库(包括时间序列数据库)的通用做法,而kafka作为WAL工具维护了数据库系统中的写持久性和原子性,也保证了高效.

The InfluxDB Connector is used to copy data between Kafka and InfluxDB Server.
- The InfluxDB source connector is used to export data from InfluxDB Server to Kafka topics.
- The InfluxDB sink connector is used to import data from Kafka topics to InfluxDB Server.
但是好像是个收费产品,具体封装已经做的挺好了,不过还需要Confluent Hub Client的支持,直接
confluent-hub install confluentinc/kafka-connect-influxdb:latest
就可以,也可以直接下载安装包
对于目前的异常检测而言,重要的不是在各个数据源集群之间获得数据,最后导入InfluxDB,更重要的是一开始提到的导入异常数据的实时性,即通过对热数据的实时判断实现系统异常的快速报警.于是之前有考虑过InfluxDB->(Kafka)->Metis,Kafka的实时/离线消费者的区别与冷读/热读的思想也较为契合.
但是这样工程上实现技术难度较大,因为没有办法用InfluxDB的类sql语法了.而对监控数据流的特征提取计算,可以用flink来搞.
总思路:(Kafka)->flink->InfluxDB->Metis
4.14.1. Definition
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams.

framwork:统一的流和批处理框架distributed:分布式处理引擎data streams:基本数据模型是数据流(如事件Event的序列)stateful:设计中贯穿的观点:批是流的特例,通过有状态的计算(incremental processing),数据的处理和之前处理过的数据或者事件将会有关联。比如,在做聚合操作的时候,一个批次的数据聚合的结果依赖于之前处理过的批次。类似于循环神经网络模型LSTM中忘记门/记忆门/输出门的设计unbounded:,数据流只有起点而没有确定的结束点,但每一条数据都可以出发计算逻辑12bounded:time-window内到达的所有数据做一批处

4.14.1.2. Time
时间标签在Flink中比关系型数据库中的key更重要,因为它必然是key.因此对Flink中的key做一介绍:
Event time: the time when an event created. It is uaually described by a timestamp in the eventsIngestion time: the time when an event enters the Flink dataflow at the source operatorProcessing Time: the local time at each operator that performs a time-based operation

生态支持

层次化的API在表达能力和易用性方面各有权衡。表达能力由强到弱(易用性由弱到强)依次是:ProcessFunction、DataStream API、SQL/Table API。

Flink API提供
- 通用的流操作原语(如窗口划分和异步操作)以及精确控制时间和状态的接口
- 详细、可自由定制的系统及应用指标(
metrics)集合,用于提前定位和响应问题 - 嵌入式执行模式可将应用自身连同整个Flink系统在单个JVM进程内启动,方便在IDE里运行和调试Flink作业
双方都想构建包含 AI 的统一大数据计算平台 Flink之于Spark的优点
StatefulMulti-level APIunbounded data stream
Flink的未来发力点
- 支持对机器学习和深度学习的集成
- 提高易用性
- 继续完善生态(如支持更多语言),提高社区知名度和活跃度
当5G解决网络传输这个瓶颈之时,IOT和实时计算将会迎来爆发时发展,届时Flink在流式计算中的天然优势也将在线上学习等领域大放异彩.
查鑫池:准备用 fastjson转换一下格式 ,然后用influxdb 的Java客户端转到库 张之逸:在Omni的数据中添加属性名以及每分钟的时间戳,构成一个csv文件,然后利用这个工具把数据导入到influxdb中 再把metis里数据读取的接口都改成从influxDB里读,最后对metis的=已有的算法打个补丁,最终也算是有成果了。
- OmniAnomaly提供数据集,38维
- csv->本地->k-v(
timestamp)->influxDB - 做成Spring Boot项目,启动服务监听指定端口
- InfluxDB->Metis
- 前端放入docker容器,上述服务放入docker容器,InfluxDB放入docker容器
负责将csv2influxDB做成一个API或者服务.

- Token:
export INFLUX_TOKEN=ZAiCu6Os2vOak5q9Ky3bcPdHWPGZHOqcgvBI52YhatD3FOjyxS05wAaDx8QPj_145Y6wnX-olAjsvPTFRO-9Qw== - Organization:
sspku;ID:87e2941a63ad495d - Bucket:
Metis;ID:05d50679c9497000 - Start Telegraf:
telegraf --config https://us-central1-1.gcp.cloud2.influxdata.com/api/v2/telegrafs/05d0726a72a9f000

4.16.2. Write Data to InfluxDB
- Do one of the following:
- InfluxDB 2.0 OSS: In your terminal, run influxd and then in your browser, go to the location where you’re hosting the UI (by default,
localhost:9999). - InfluxDB 2.0 Cloud: In your browser, go to
https://cloud2.influxdata.com/.
- In the navigation menu on the left, select **Data (Load Data) **> Buckets.
- Under the bucket you want to write data to, click $+$Add Data.
- Select from the following options:
- Configure Telegraf Agent
- Line Protocol
- Client Library
Telegraf Agent支持从不同的buckets导入到InfluxDB,不过本地没有在运行的集群/容器或者数据库,主要介绍Line Protocol和Client Library.
measurementName,tagKey=tagValue fieldKey="fieldValue" 1465839830100400200
--------------- --------------- --------------------- -------------------
| | | |
Measurement Tag set Field set Timestamp
mem,host=host1 used_percent=23.43234543 1556892576842902000
cpu,host=host1 usage_user=3.8234,usage_system=4.23874 1556892726597397000
mem,host=host1 used_percent=21.83599203 1556892777007291000
每一行代表一个数据点,每个数据点需要指明表名(measurement)和key-value对(field set)
- Select Upload File or Enter Manually.
- Upload File: Select the time precision of your data. Drag and drop the line protocol file into the UI or click to select the file from your file manager.
- Enter Manually: Select the time precision of your data. Manually enter line protocol.
- Upload File: Select the time precision of your data. Drag and drop the line protocol file into the UI or click to select the file from your file manager.
- Click Write Data. A message indicates whether data is successfully written to InfluxDB. To add more data or correct line protocol, click Previous.
- Click Finish.


{kind=link}
{kind=link}
{kind=link}
支持主流语言客户端:

<dependency>
<groupId>com.influxdb</groupId>
<artifactId>influxdb-client-java</artifactId>
<version>1.8.0</version>
</dependency>package example;
import java.time.Instant;
import java.util.List;
import com.influxdb.annotations.Column;
import com.influxdb.annotations.Measurement;
import com.influxdb.client.InfluxDBClient;
import com.influxdb.client.InfluxDBClientFactory;
import com.influxdb.client.WriteApi;
import com.influxdb.client.domain.WritePrecision;
import com.influxdb.client.write.Point;
import com.influxdb.query.FluxTable;
public class InfluxDB2Example {
public static void main(final String[] args) {
// You can generate a Token from the "Tokens Tab" in the UI
String token = "token";
String bucket = "bucketID";
String org = "87e2941a63ad495d";
InfluxDBClient client = InfluxDBClientFactory.create("https://us-central1-1.gcp.cloud2.influxdata.com", token.toCharArray());
}
}主要有三种方式:
- 使用
Line Protocol
String data = "mem,host=host1 used_percent=23.43234543";
try (WriteApi writeApi = client.getWriteApi()) {
writeApi.writeRecord(bucket, org, WritePrecision.NS, data);
}- 自己构造
Data Point
Point point = Point
.measurement("mem")
.addTag("host", "host1")
.addField("used_percent", 23.43234543)
.time(Instant.now(), WritePrecision.NS);
try (WriteApi writeApi = client.getWriteApi()) {
writeApi.writePoint(bucket, org, point);
}- 使用注解与IndluxDB约定好指定格式的Java对象
Mem mem = new Mem();
mem.host = "host1";
mem.used_percent = 23.43234543;
mem.time = Instant.now();
try (WriteApi writeApi = client.getWriteApi()) {
writeApi.writeMeasurement(bucket, org, WritePrecision.NS, mem);
}
------
@Measurement(name = "mem")
public static class Mem {
@Column(tag = true)
String host;
@Column
Double used_percent;
@Column(timestamp = true)
Instant time;
}a service for transferring csv to InfluxDB
In application.properties:
#HOST为系统环境变量需要配置,另注意如果使用本地InfluxDB2.0以下,默认端口8086,2.0以上9999
spring.influx.url=${HOST:http://47.101.146.76:8086}
spring.influx.database=metis
spring.influx.retentionPolicy=autogen
spring.influx.user=root
spring.influx.password=root
spring.influx.token=u2Xonr9XRJliwwsURBCRju4EZeWmToO5hBAwzBryCekmIhQueNKRFwAsaYKdbKLMxwi0QaViG8AHHmBSBTsAyA==
spring.influx.org=87e2941a63ad495d
spring.influx.bucket=05d5f0d32448f000
spring.influx.cloudUrl=https://us-central1-1.gcp.cloud2.influxdata.com
filePath=./repository/test.csvThis can be imported by Postman:
{
"info": {
"_postman_id": "afe618aa-78a8-4fc9-aac4-c14527a60e1a",
"name": "csv2InfluxDB",
"schema": "https://schema.getpostman.com/json/collection/v2.1.0/collection.json"
},
"item": [
{
"name": "greeting",
"request": {
"method": "GET",
"header": [],
"url": {
"raw": "http://127.0.0.1:8080/operator/greeting",
"protocol": "http",
"host": [
"127",
"0",
"0",
"1"
],
"port": "8080",
"path": [
"operator",
"greeting"
]
}
},
"response": []
},
{
"name": "root",
"request": {
"method": "GET",
"header": [],
"url": {
"raw": "http://127.0.0.1:8081/",
"protocol": "http",
"host": [
"127",
"0",
"0",
"1"
],
"port": "8081",
"path": [
""
]
}
},
"response": []
},
{
"name": "queryAllUser",
"request": {
"method": "GET",
"header": [],
"url": {
"raw": "http://127.0.0.1:8081/",
"protocol": "http",
"host": [
"127",
"0",
"0",
"1"
],
"port": "8081",
"path": [
""
]
}
},
"response": []
},
{
"name": "monitor insert",
"request": {
"method": "POST",
"header": [],
"body": {
"mode": "raw",
"raw": "{\r\n \"traceId\":\"\",\r\n \"spanId\":\"3\"\r\n}",
"options": {
"raw": {
"language": "json"
}
}
},
"url": {
"raw": "http://127.0.0.1:8081/monitor/insert",
"protocol": "http",
"host": [
"127",
"0",
"0",
"1"
],
"port": "8081",
"path": [
"monitor",
"insert"
]
}
},
"response": []
},
{
"name": "业务异常",
"request": {
"method": "GET",
"header": [],
"url": {
"raw": "http://127.0.0.1:8081/operator/business",
"protocol": "http",
"host": [
"127",
"0",
"0",
"1"
],
"port": "8081",
"path": [
"operator",
"business"
]
}
},
"response": []
},
{
"name": "一个实验,其实是我们取代了系统自己的错误处理器",
"request": {
"method": "GET",
"header": [],
"url": {
"raw": "http://127.0.0.1:8081/operator/500",
"protocol": "http",
"host": [
"127",
"0",
"0",
"1"
],
"port": "8081",
"path": [
"operator",
"500"
]
}
},
"response": []
},
{
"name": "monitor monitor",
"request": {
"method": "GET",
"header": [],
"url": {
"raw": "http://127.0.0.1:8081/monitor/add",
"protocol": "http",
"host": [
"127",
"0",
"0",
"1"
],
"port": "8081",
"path": [
"monitor",
"add"
]
}
},
"response": []
}
]
}