K-Means is an unsupervised machine learning algorithm where the goal is to determine the inherent patterns in the given unlabeled data i.e. find out if the data can be divided into groups or clusters which share similar characteristics. It is a very powerful technique and is widely used for data mining.
The K-Means clustering algorithm can be summarized in two main steps which get executed iteratively for a given data set with a pre-determined number of clusters as described below:
- Cluster assignment: In this step each data point gets assigned to a cluster depending on which cluster it is closest to. It therefore involves computing the distance of the given data point w.r.t each cluster. The cluster for which the distance comes out minimum is the cluster which gets assigned to the data point.
- Cluster centroid update: Once the data points gets assigned to their respective clusters, this steps inolves updating the cluster centroid based on the data points which are associated with it. The cluster centroid is updated based on the mean value of the location of all points in that cluster.
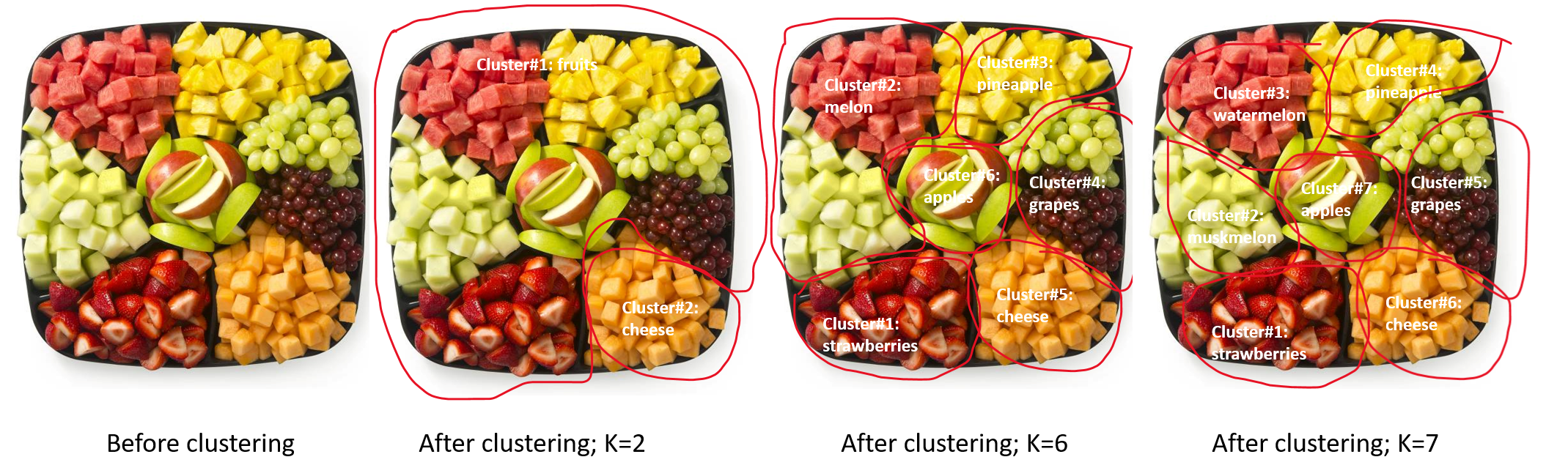 As you can see in the image above, there are various ways by which we could partition the given tray of mixed fruits and cheese. With two clusters, there will be one cluster of fruits and second cluster of cheese. Further, if we choose the number of clusters=6, we will have one cluster of strawberries, second cluster of melons, third cluster of pineapples, fourth cluster of grapes, fifth cluster of cheese and sixth cluster of apples. Similarly, if we pick number of clusters=7, we will have an additional cluster due to dividing the melons cluster in two.
Thus, it is evident from this very simple intutive example that there could be several choices for the number of clusters. How do we then pick the number of clusters?
As you can see in the image above, there are various ways by which we could partition the given tray of mixed fruits and cheese. With two clusters, there will be one cluster of fruits and second cluster of cheese. Further, if we choose the number of clusters=6, we will have one cluster of strawberries, second cluster of melons, third cluster of pineapples, fourth cluster of grapes, fifth cluster of cheese and sixth cluster of apples. Similarly, if we pick number of clusters=7, we will have an additional cluster due to dividing the melons cluster in two.
Thus, it is evident from this very simple intutive example that there could be several choices for the number of clusters. How do we then pick the number of clusters?
The objective function of K-Means serves two main purposes:
- It helps in debugging for us to determine if the algorithm is working as desired i.e. it is converging.
- It helps to determine the optimum number of clusters.
The objective function of K-Means also referred to as Distortion function is given as follows:
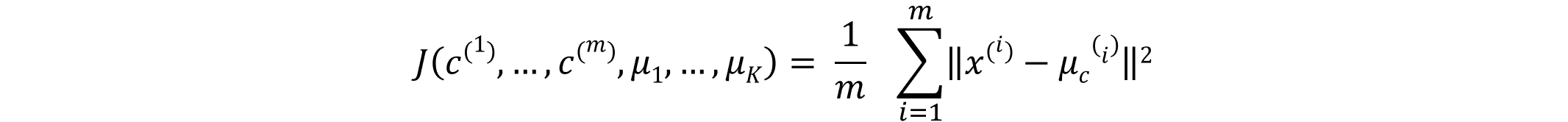 where
where 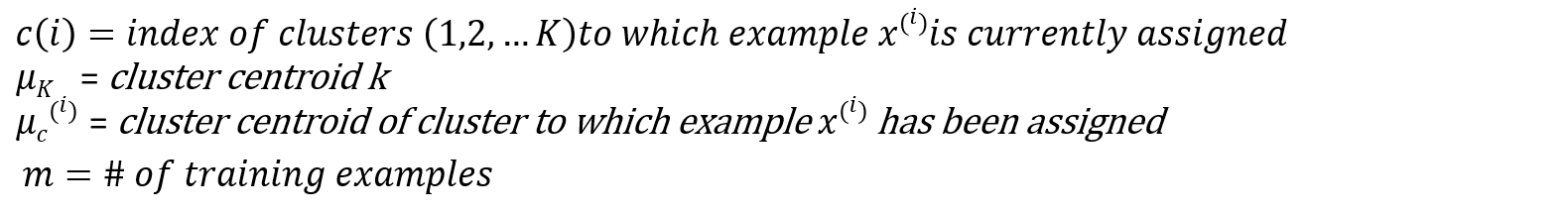 The objective function thus, involves determining the distance between the given data point and the assigned cluster centroid.The K-means algorithm is determined to converge when there is no further decrement in the objective function with changing number of clusters i.e. it has reached its minimum value.
The convergence of K-Means is therefore, highly dependent on the number of clusters chosen and how these clusters were initialized.Thus, it is understood that this algorithm may give different solutions based on the starting point. As per Andrew Ng, the best way is to manually pick the number of clusters and randomly initialize their cluster centroids. Further, fine tune the number of clusters by studying the objective function behavior as the number of clusters are varied. The 'Elbow method' of determining the optimum number of clusters does the same where the objective function is plotted agains the corresponding number of clusters. The number of clusters at which the objective function's value is lowest and is not changing further (appears like an elbow) is the optimum cluster number. However, there are cases when there will no clear elbow may be observed. In such cases, we need to then evaluate the choice of number of clusters based on a metric for its application in later purpose.
The objective function thus, involves determining the distance between the given data point and the assigned cluster centroid.The K-means algorithm is determined to converge when there is no further decrement in the objective function with changing number of clusters i.e. it has reached its minimum value.
The convergence of K-Means is therefore, highly dependent on the number of clusters chosen and how these clusters were initialized.Thus, it is understood that this algorithm may give different solutions based on the starting point. As per Andrew Ng, the best way is to manually pick the number of clusters and randomly initialize their cluster centroids. Further, fine tune the number of clusters by studying the objective function behavior as the number of clusters are varied. The 'Elbow method' of determining the optimum number of clusters does the same where the objective function is plotted agains the corresponding number of clusters. The number of clusters at which the objective function's value is lowest and is not changing further (appears like an elbow) is the optimum cluster number. However, there are cases when there will no clear elbow may be observed. In such cases, we need to then evaluate the choice of number of clusters based on a metric for its application in later purpose.
- The globally optimum result may not be achieved: As discussed earlier, clustering achieved through the K-Means algorithm is dependent on the initial starting point i.e. the cluster centroids are randomly initialized. It can very well happen that for the chosen cluster centroids, the objective function can get stuck in local minima. Therefore, even though it may seem that the algorithm has converged but it may not be the global optimum configuration.
- The number of clusters need to be know beforehand: The algorithm will try to fit the chosen number of clusters which may not lead to meaningful results. In such a case, more complicated clustering algorithms that have better quantitative measure of the fitness per number of clusters for ex. Gaussian mixture models or which can choose suitable number of clusters for ex. DBSCAN, mean-shift, etc. can be used.
- K-Means is limited to linear cluster boundaries: K-Means algorithm works really well with data that has linear boundaries between clusters. However, for more complicated boundaries K-Means would not work. The workaround would be to project such data into a higher dimensional space where the linear separation is possible. This will help the K-Means to discover those non-linear boundaries. This method of clustering is the Spectral Clustering which uses graph of nearest neighbors to compute the higher dimensional data and assigns label using the K-Means algorithm.
- K-Means can be slower for large number of samples: The workaround is this shortcoming is to use subset of the data instead of the whole dataset to update the cluster centers at each step. This method is the Minibatch K-Means.