Object detection, a critical task in computer vision, has seen significant advancements with models like the YOLO (original paper, latest code version). However, traditional models like YOLO have limitations in detecting objects outside their training datasets. To address this, the AI community has shifted towards developing models that can identify a wider range of objects, leading to the creation of models akin to CLIP but for object detection.
OWL-ViT represents a leap forward in open-vocabulary object detection. It starts with a training stage similar to CLIP, focusing on a vision and language encoder using a contrastive loss. This foundational stage enables the model to learn a shared representation space for both visual and textual data.
The innovation in OWL-ViT comes during its fine-tuning stage for object detection. Here, instead of the token pooling and final projection layer used in CLIP, OWL-VIT employs a linear projection of each output token to obtain per-object image embeddings. These embeddings are then used for classification, while box coordinates are derived from token representations through a small MLP. This approach allows OWL-ViT to detect objects and their spatial locations within images, a significant advancement over traditional object detection models.
Below is a diagram of the Pre-training and Fine-tuning stages of OWL-ViT:
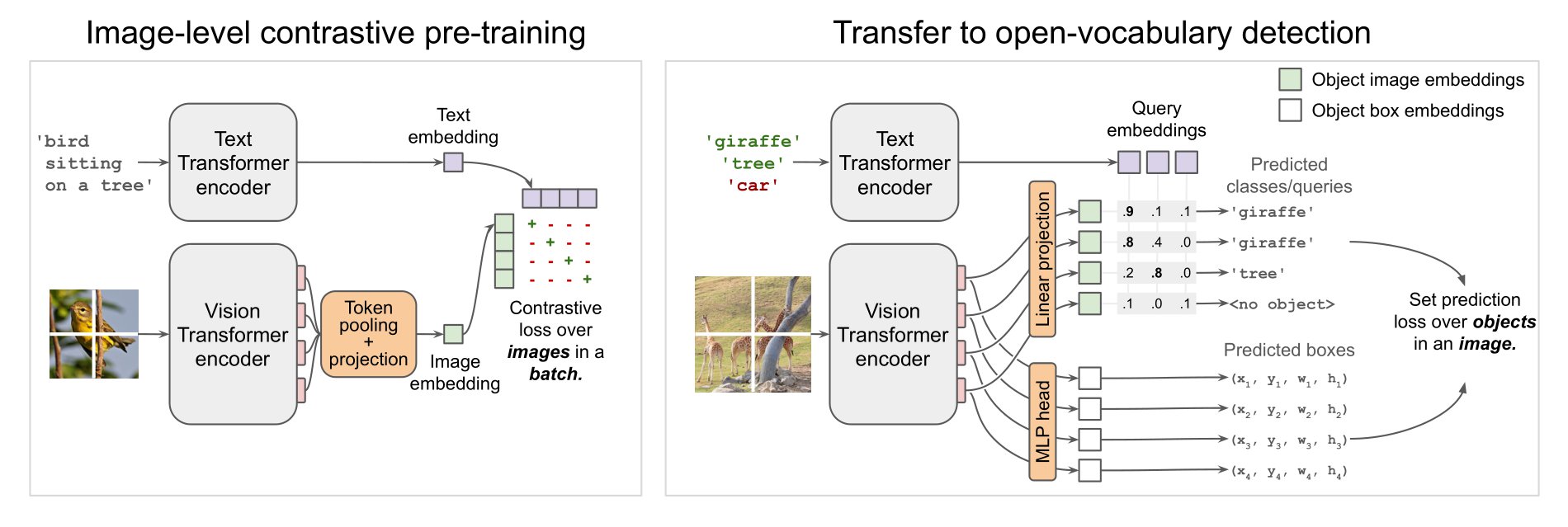
After fine-tuning, OWL-ViT excels in open-vocabulary object detection. It can identify objects not explicitly present in the training dataset, thanks to the shared embedding space of the vision and text encoders. This capability makes it possible to use both images and textual queries for object detection, enhancing its versatility.
For practical applications, one typically uses text as the query and the image as context. The provided Python example demonstrates how to use the transformers library for running inference with OWL-ViT.
import requests
from PIL import Image, ImageDraw
import torch
from transformers import OwlViTProcessor, OwlViTForObjectDetection
processor = OwlViTProcessor.from_pretrained("google/owlvit-base-patch32")
model = OwlViTForObjectDetection.from_pretrained("google/owlvit-base-patch32")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
texts = [["a photo of a cat", "a photo of a dog", "remote control", "cat tail"]]
inputs = processor(text=texts, images=image, return_tensors="pt")
outputs = model(**inputs)
target_sizes = torch.Tensor([image.size[::-1]])
results = processor.post_process_object_detection(
outputs=outputs, target_sizes=target_sizes, threshold=0.1
)
i = 0 # Retrieve predictions for the first image for the corresponding text queries
text = texts[i]
boxes, scores, labels = results[i]["boxes"], results[i]["scores"], results[i]["labels"]
# Create a draw object
draw = ImageDraw.Draw(image)
# Draw each bounding box
for box, score, label in zip(boxes, scores, labels):
box = [round(i, 2) for i in box.tolist()]
print(
f"Detected {text[label]} with confidence {round(score.item(), 3)} at location {box}"
)
# Draw the bounding box on the image
draw.rectangle(box, outline="red")
# Display the image
imageThe image should look like this:

Feel free to use the code to try more complex examples or this Gradio app:
<iframe src="https://johko-OWL-ViT.hf.space" frameborder="0" width="850" height="450"> </iframe>OWL-ViT's approach to object detection represents a notable shift in how AI models understand and interact with the visual world. By integrating language understanding with visual perception, it pushes the boundaries of object detection, enabling more accurate and versatile models capable of identifying a broader range of objects. This evolution in model capabilities is crucial for applications requiring nuanced understanding of visual scenes, particularly in dynamic, real-world environments.
For more in-depth information and technical details, refer to the OWL-VIT paper. You can also find information about OWL-ViT 2 model in the Hugging face documentation.