2018: Bag of Experts Architectures for Model Reuse in Conversational Language Understanding #129
Labels
Comments
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Bag of Experts Architectures for Model Reuse in Conversational Language Understanding
Rahul Jha, Alex Marin, Suvamsh Shivaprasad, and Imed Zitouni. Microsoft. 2018 NAACL-HLT (Human Language Technologies)
http://aclweb.org/anthology/N18-3019
概要
スロットタギングのモデル.モデルの再利用性のために,Bag of Experts (BoE)というアーキテクチャを提案.これをLSTMとCRFをそれぞれベースに持つモデルの計4モデルで実験した.コルタナ(とは明記していないがまず間違いない)に関連する10ドメインの新しいデータセットで実験し,BoEによる性能改善を確認できた.
スロットタギングとは
時系列データ(ユーザー発話)に対して,スロットの位置をタグ付けすること.

背景にある問題
各ドメインによってアノテーションは大きく異なるので,各ドメイン毎にスロットタギングは学習しないといけないが,ドメインが増えるに連れて多くのシナリオが必要になり,高コストとなってしまう.
またスロットによってはドメイン共通で使われる物がある.Figure 1の例だとtravelとflight statusのドメインでは,dateとtimeというのが使われている,また3つのドメインすべてにlocationというスロットが使われている.共通スロットに対しては,アノテーションデータの再利用が有効かもしれないが,発話の分布とラベルの分布はドメイン間で異なるかもしれないので,ドメイン適用の技術が必要になる.
データドリブン適用(左a)とモデルドリブン適用(右b,本手法)
データドリブン
まずdate, time, location,及び他の再利用スロットを含むデータのリポジトリを作る.そしてモデル学習時に,再利用可能な関連データとドメイン依存のデータを結合し,利用する.欠点としては,再利用スロットのデータが増えてきたときに,ドメイン依存のデータよりも相対的に多くなり,学習時間を増やしてしまうことが考えられる.これは新モデルをさっと開発したいときに足かせとなってしまう.
モデルドリブン
再利用スロットのデータを学習データに利用するのではなく,そのデータを利用してexpertモデルをこれらのスロットに対して学習させる.そしてそれらのモデルの出力を新しいドメインの学習の際に直接利用する.
これにより,モデルの学習時間は新しいドメインのデータサイズに比例し,再利用スロットのデータサイズが大きければ学習を早くすることができる.本手法はこっち.
アプローチ
LSTMとCRFをベースに実験するので,これらをスロットタギングに使ったモデルをまず紹介する(BoEなし).そしてBoEも利用するLSTM-BoEとCRF-BoEを説明する.合計4モデル.
LSTM
各単語毎に,charレベルのBiLSTMと単語embeddingをしてconcatする.


このgをBiLSTMにまたかけ,双方向の最後の出力(文頭と文末の単語がWに相当)concatしてhを作る
このhをフィードフォワードのレイヤに入力としていれ,softmaxを取る.これにより各単語におけるラベルの確率を得る.
LSTM-BoE
先程のLSTMのBoE拡張版.まず再利用可能なエキスパートドメインのセットをe1..ek∈Eとする.各ejは,先程のLSTMと同様の構造でエンコードし,hi^{ej}を得る.これはある単語wi,あるエキスパートejのエンコード結果を意味する.エキスパートドメイン毎にLSTMは用意する.
エキスパートドメインをエンコードしたものは,それぞれ足し合わせてhEとして後ほど利用する
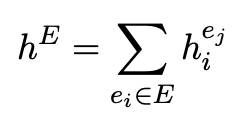
先程のLSTMの構造と同様に,単語,文字レベルのエンコードした結果をBiLSTMに入力するgiを単語毎に作成する.それは下記となり,先ほどと似ているが,hEが追加でconcatされている点で異なる

そしてgiを入力に受け取ったLSTMはhiを同様に得る.
CRF
標準的な,Linear-chain CRFを利用.unigram, bigram, trigramを利用(前後トークンも含めて).
CRF-BoE
LSTM-BoEと似ている.まず各再利用可能なエキスパートドメインej∈Eに対して,CRFモデルcjを鍛える.ターゲットドメインの学習時には,各単語wiについて,CRFモデルcjから出力されたl_i^jベクトル(one-hot)が利用される.l_i^jはエキスパートドメインにおけるラベルの数の長さのベクトルになるが,各単語で予測されたラベルには1をセットし,他は0にする.そして,各単語枚にすべてのエキスパートCRFモデルからのラベルベクトルはconcatされ,ターゲットドメインのCRF学習時にn-gram特徴量と一緒に提供される.
データ
ターゲットドメイン
ターゲットドメイン(新たに学習されることを前提として鍛えられるドメイン)は10ドメインで下記のリストになる.これは新しいデータであるため,学習データはクラウドソーシングで,下記の2ステップで集めた.
再利用ドメイン
再利用スロットを含む2つのドメイン(timexとlocation)で実験(ドメインという名前がややこしいが,再利用スロットを含む発話セットを,仮想のアプリ(ドメイン)のような形でデータセットを構築している).timexはdate, time, durationスロットから成る.locationはlocation,location_type, place_nameスロットから成る.これらは40ドメインのうち,20ドメイン以上に出てきており(MSのCortanaにおいて),再利用目的において理想的なものである.
これらのデータはCortanaからサンプリングされ,各再利用ドメインは100万発話(!!).また再利用ドメインにおいて,ターゲットドメインの発話と再利用ドメインの発話に重複はない.
ちなみに,このような方法により,timexとlocationを利用したい他プロダクトにおいても使えて便利.F1スコアでそれぞれ,96%, 89%を得た. 📓
実験
BoEがスロットタギングを再利用ドメインの情報を利用して向上できるか,実験.新ドメインのデータが少ないときもシミュレーションしたいので,各ドメインからのサンプル数は2000, 1000, 500と3パターン用意した.
LSTMの事前実験 (devセット)
LSTMモデルの単語embeddingの際の辞書の選定をdevセットで行った.Gloveの100, 200, 300次元とCortanaの実データで鍛えた500次元を利用.Cortanaのデータでのembeddingが改善率が一番高くこれを採用. 📓
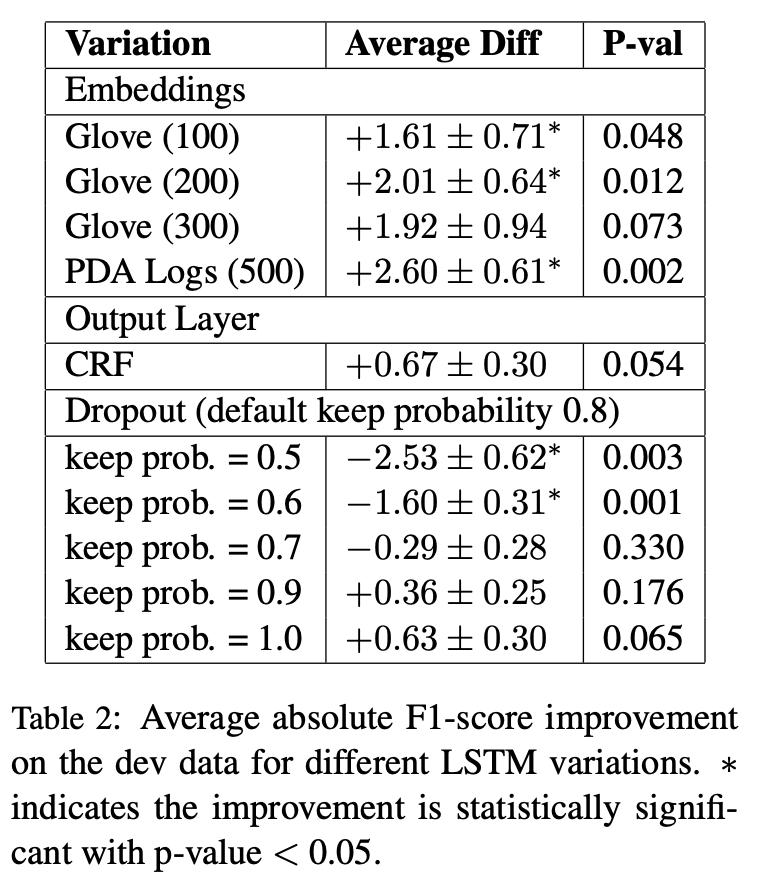
またdropoutの確率もいくつか試したが,特に有意な違いは得られなかった.(のでデフォルト?)
結果考察
a, bでサンプリング数2000, 1000, 500のF値.CRFモデルよりLSTMモデルの方が性能が良かった.CRFが前後3単語しか見れないのに対して,LSTMは長いコンテキストを捉えることができたのが原因と説明できる.
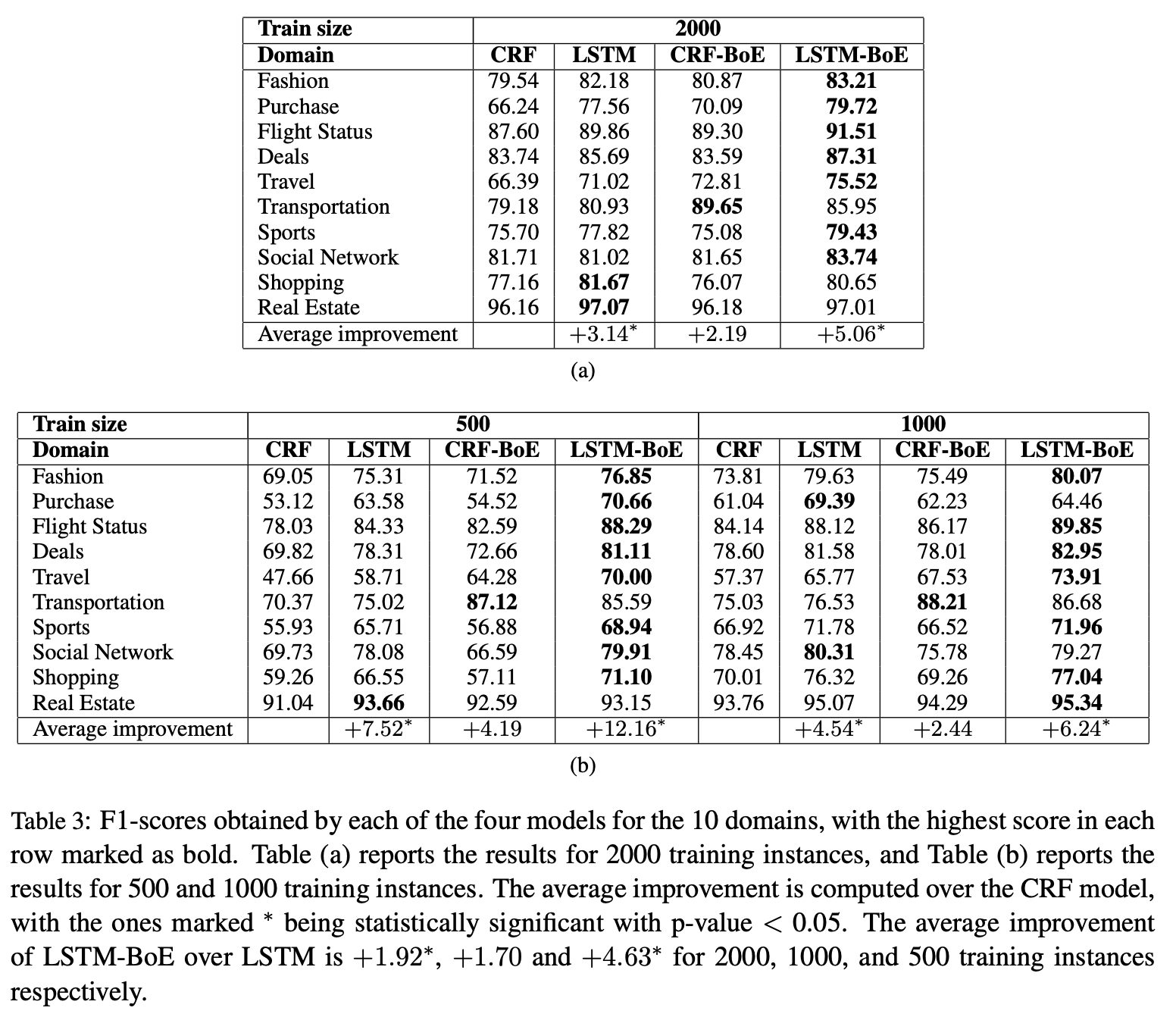

また,CRF,LSTMモデルよりも,CRF-BoE,LSTM-BoEモデルの方が良くなっていた.10ドメインの中ではtransportationとtravelドメインで大きく改善されており,これら2つのドメインはtimexとlocationスロットを大きく含んでいることが改善の理由と考えられる(Table 4)
また悪化したドメインもあり,shoppingモデルがそれに当たる.ただし,shopping同様timexとlocationをあまり含まないpurchaseドメインでは改善したので,常にエキスパートスロットの不足が性能低下を意味するとは限らない.
sports, sns, dealsではLSTM-BoEで改善する一方,CRF-BoEでは改善しなかった.おそらく,LSTM-BoEの全結合の出力レイヤが,何らかの情報を転移させることが出来たのではないかと思う.逆にCRFではそれは出来ない.(// やや歯切れが悪い)
またデータを減らしたときの結果,bを見てみる.興味深いことに,データ数が少ないときのほうがBoEの改善率が高い. 📔
例えば,purchaseドメイン,LSTM-BoEはデータ数500で70.66%なのに対して,データ数2000のCRFでは,66.24%なのでBoEすごい.同様にflight status, travel transportationドメインでも同様の結果.
これにより,LSTM-BoEは,新規ドメインのアノテーションデータが少ないときに有効であることが分かった.一方,ターゲットドメインのデータが増えるにつれて,改善具合は下がっていった.どの辺りでエキスパートが不要になるかはfuture workにとっておく.
関連研究
割愛
まとめ
Bag-of-Expertsを提案,再利用可能なエキスパートモデルを利用することにより,CRF,LSTMベースのモデルを改善することができた.特に長いコンテキストを扱うことのできるLSTMベースのものが改善率が一番良かった.実験では10ドメインをターゲットドメインとし,少ないデータも想定して実験を行い,少ないデータしか得られない状況においては,エキスパー度モデルの利用により大きな改善率を生み出すことが分かった.
コメント 📓
The text was updated successfully, but these errors were encountered: