You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
一般的なアテンション付seq2seq型のモデルを採用 (Sutskever et al., 2014; Bahdanau et al.2015).
モデルとしては,コンテキスト(対話履歴+現在のユーザー発話)をX=x1,x2,...Xmとして表し,デコーダーでY=y1,y2,...,ynを生成するモデルになる.アテンションでは,デコーダーの各タイプステップtでコンテキストに対してアテンションを計算する.
今回のSpekakerモデルとPersonalityモデルでは,1024次元の隠れ層を持つ4レイヤのLSTMになっている.
アメリカのコメディ番組である,フレンズとビッグバンセオリーを利用した.最低2000ターン以上持つキャラを利用したため,結果的に13キャラになった(6人がフレンズ,7人がビッグバン).各話者にはユニークIDを振る.そして,下記の手順で各キャラの個性を見積もった:
1.各キャラ500発話の内,50サンプルをランダムで得る
2.Mairesseら(2007)の個性認識器を利用する.この認識器は,"Linguistic Inquiry and Word Count (pennebaker and King, 1999)とMRC心理言語データベース(Coltheart, 1981)の,言語的特徴からスカラ値を出力する.
3.50サンプルで計算した個性スコアの平均値を,各キャラのOCEANスコアとして割り当てた 📔
テストでは再びOpenSubtitlesを利用.学習時には利用しなかった2.5Mの発話をcontextとして入力し,学習されたSpeakerとPersonalityモデルが13キャラの応答を,Stochastic Greedy Sampling (Li et al., 2017)で生成する.またニューラル対話生成モデルはdullレスポンスしがちなので,100の頻出応答は評価から取り除いた.これにより各キャラ(個性)で~700Kの応答を得た.これを評価セットとする.
スタイルを適用した応答生成は流行り.(Sennrich et al., 2016; Hu et al.,2017; Ficler and Goldberg, 2017; Niu and Bansal,2018).
Yang (2017)では,ドメイン適用の手法を利用して,話者の年齢や性別といった個人情報を利用して条件付けしている.Luan (2017)では,話者のブログ投稿などを利用している.
もっと最近だと,Oraby (2018)では,PERSONAGEという統計型のルールベースの生成器を利用して,レストランドメインの,個性のバリエーションを持つ,人工データコーパスを作った.
jojonki
changed the title
🚧 2018: Automatic Evaluation of Neural Personality-based Chatbots
2018: Automatic Evaluation of Neural Personality-based Chatbots
Oct 6, 2018
Automatic Evaluation of Neural Personality-based Chatbots
Yujie Xing, Raquel Fernández. INLG 2018
https://arxiv.org/abs/1810.00472
概要
Open domainにおけるseq2seq型の応答生成モデルにおいて、そのモデルが生成する応答が個性の特徴を反映できているか、自動評価(人手不要)できる手法を提案
イントロ
Seq2seq型のモデルでは大量のアノテートされていないデータを利用してモデルを学習するが、異なる個性の特徴を持つ応答を生成できるか評価した。そこで本論では2つの既存の応答生成モデルを評価した
生成される応答は話者で条件付けされる
生成される応答は個性タイプで条件される
今回の評価では,個性のBig Five心理モデル(Norman, 1963),を採用した.最下部の参考項目も参考に.
性格を表す5つの尺度.頭文字を取ってOCEAN.各特性はスカラで1から7の値を取る.
Openness(開放性),Conscientiousness(勤勉性),Extraversion(外向性),Agreeableness(協調性),Neuroticism(情緒不安定性)
対話生成モデル
一般的なアテンション付seq2seq型のモデルを採用 (Sutskever et al., 2014; Bahdanau et al.2015).
モデルとしては,コンテキスト(対話履歴+現在のユーザー発話)をX=x1,x2,...Xmとして表し,デコーダーでY=y1,y2,...,ynを生成するモデルになる.アテンションでは,デコーダーの各タイプステップtでコンテキストに対してアテンションを計算する.
今回のSpekakerモデルとPersonalityモデルでは,1024次元の隠れ層を持つ4レイヤのLSTMになっている.
Speaker,Personalityモデルについて説明していく.
Speakerモデル
各話者sは,それぞれembeddingベクトルvsを関連付けられる.このvsは,デコーダーのLSTMの最初の隠れ層に,毎時刻挿入される.vsは学習中に更新される.// vsの初期化など謎だが,スピーカー毎にランダマイズされた何らかのベクトルという認識
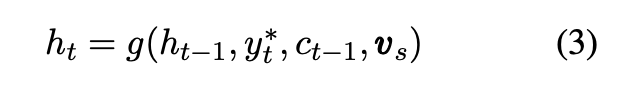
このモデルを提案したLiらは,各実際の(factualな)コンテンツに対して,一貫しているか,という点でモデルを評価した.我々は,このモデルがそれぞれが独立した個性を反映したスタイルになっているのか評価した
Personalityモデル
Speakerモデルが利用した話者embedding vsの代わりに,personality embedding voを利用する.OCEANスコアは5次元ベクトルoであり,各次元は1から7の値を取る(実際はこれを[-1, 1]でノーマライズする).そして線形変換を行い,vo=Wo * (o-4)/3 という式でvoを得る.Woは学習パラメタで,5xd次元.// この式をどう出したのかは謎
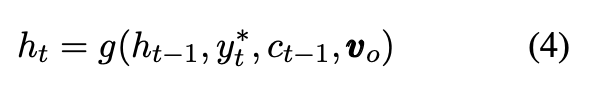
式は先程の(3)式のvsをvoに置き換える.
ちなみにこの手法は,Herzigら(2017)のモデルがある.彼らはカスタマーサービスドメインに注力しており,人評価によるたった2つの個性特徴量を使っている.これに対して我々はopen-domainの雑談対話を扱っており,OCEANという一般的に広く使われている特徴量を,自動評価手法によって利用している.
実験セットアップ
データセット
アメリカのコメディ番組である,フレンズとビッグバンセオリーを利用した.最低2000ターン以上持つキャラを利用したため,結果的に13キャラになった(6人がフレンズ,7人がビッグバン).各話者にはユニークIDを振る.そして,下記の手順で各キャラの個性を見積もった:
1.各キャラ500発話の内,50サンプルをランダムで得る
2.Mairesseら(2007)の個性認識器を利用する.この認識器は,"Linguistic Inquiry and Word Count (pennebaker and King, 1999)とMRC心理言語データベース(Coltheart, 1981)の,言語的特徴からスカラ値を出力する.
3.50サンプルで計算した個性スコアの平均値を,各キャラのOCEANスコアとして割り当てた 📔
また連続するターンをcontext-responseペアとして利用し,各応答には話者IDか話者のOCEANスコアをアノテートした.結果的に86K以下のcontext-responseペア,そのうち,2Kペアはランダムに選ばれバリデーションセットとして利用.
データセット
学習
TVシリーズのデータセットは比較的小さいため,Li (2016b)らの方法に則り,OpenSubtitlesデータセット(Tiedemann, 2009)を事前学習データとして利用.これは巨大なデータセットであり,映画字幕から50M行ものデータから成る.このデータは特に話者情報はないため,連続するラインをctx-respペアとして選ぶ.またマシンパワーの制約上,1.8Mペアを学習データに利用し,75Kをバリデーションセットとして利用.
まず,OpenSubtitlesの学習セットで15イテレーション(==epoch)回した(バリデーションセットのパープレキシティが安定するまで).その後,このモデルを利用して,SpeakerとPersonalityモデルを初期化し,TVシリーズでそれぞれ30以上のイテレーション(こちらもバリデーションで安定するまで).設定はLiらと同じ.Vocabサイズは25Kで,最大入力文字列は50.// 他パラメタは論文3.2参考
テスト
テストでは再びOpenSubtitlesを利用.学習時には利用しなかった2.5Mの発話をcontextとして入力し,学習されたSpeakerとPersonalityモデルが13キャラの応答を,Stochastic Greedy Sampling (Li et al., 2017)で生成する.またニューラル対話生成モデルはdullレスポンスしがちなので,100の頻出応答は評価から取り除いた.これにより各キャラ(個性)で~700Kの応答を得た.これを評価セットとする.
評価手法
異なる個性を持つ対話生成ができるか評価できる手法を提案.各キャラ500応答の内,250サンプルをランダムに選び,OCEANスコア(5次元)をそれぞれ計算.この250サンプルには対応するキャラがアノテートされている.これにより,それぞれ250のデータポイントを持つ,13のゴールドクラスを得る.// この応答は生成されたものでなく,実際にデータセットにある応答発話であるため,この応答を利用して得られるOCEANスコアが,得うる最大のスコアとなるはずなのでゴールドクラスと呼んでいるっぽい(オラクル値と同義な気もする)
そして,SVMを利用して,生成された応答から見積もられたOCEANスコアが,どの程度ゴールドクラスを回復できるか調べた.5-foldクロスバリデーションを利用し,これを10回行いその平均を報告する(5×10で50の平均).
またベースラインとして,生成された応答のゴールドラベルを,ランダマイズして得る,これは偶然得られた際のパフォーマンスを知るために行った.
また今回利用したMairesseの個性認識器はTV原稿の対話に最適化されているわけではない.そのため,ゴールド発話(オリジナル発話)をBoWアプローチによって,パフォーマンス比較した.これにより認識器が,平易な単語利用によるものしか検知できないかどうか,ということをテストできる.そのため,それら(BoW)は個性を表すものになっている可能性があるため,オリジナル発話から,ストップワードを除く,200の頻出単語を特徴量として選んだ.そして,BoW表現を利用して,同様の分類手順を踏んだ.
結果
各モデルの結果は下記.
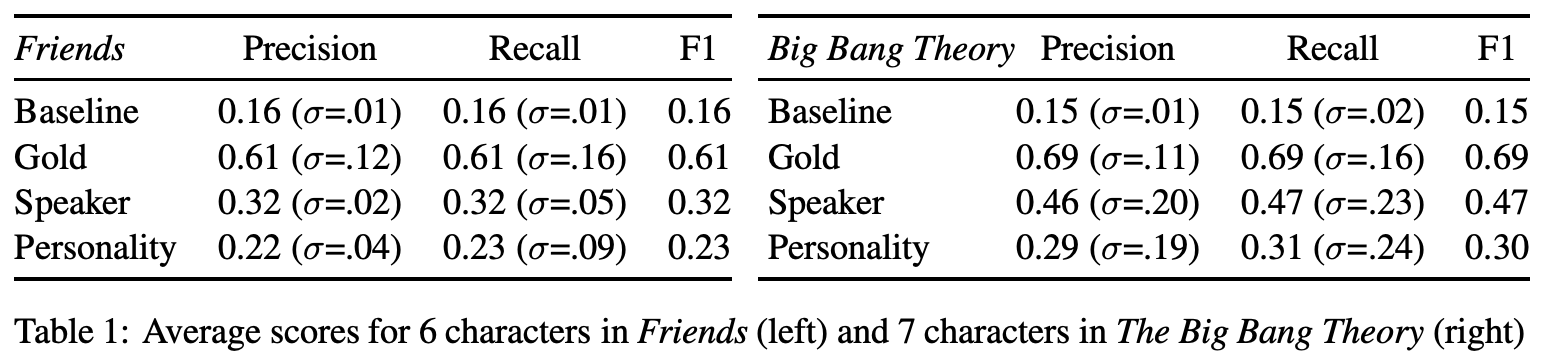
上限と下限
baselineよりもgoldの方が十分に高い.これは今回の評価手法が,データの異なる個性を十分に区別できているということを指し示す.またフレンズよりもビッグバンの方がスコアが高い(個性を明白に区別できている)
個性認識機の代わりに,BoWを使った時は,フレンズで23%のF1,ビッグバンで19%のF1となった // この結果が論文には載っていない...
これにより個性認識器はBoW表現よりも,個性の特徴を遥かに強く捉えられることがわかった.
SpeakerモデルとPersonalityモデル
両モデルともbaselineよりも高い性能を出しているが,goldよりもだいぶ低い.またSpeakerモデルの方がPersonalityモデルよりも良い結果になった.これは,Personalityモデルは個性タイプに応じた応答を生成しており,より変化に富んだと思われる(そのため識別しにくい)
ただPersonalityモデルのメリットとしては,学習には現れなかった事前定義済みの個性の応答を生成できるという点である.この潜在的特性のテストのため,極端なOCEANスコアを持つモデルで実験した.OCEANスコアの内,1つを6.5と高くして残りを3.5にした(エキストリーム設定.OCEAN5つ分すべてのパターンで実験).そして,それぞれの設定で評価セットすべてを利用して応答を生成し,それを評価した結果が下記.
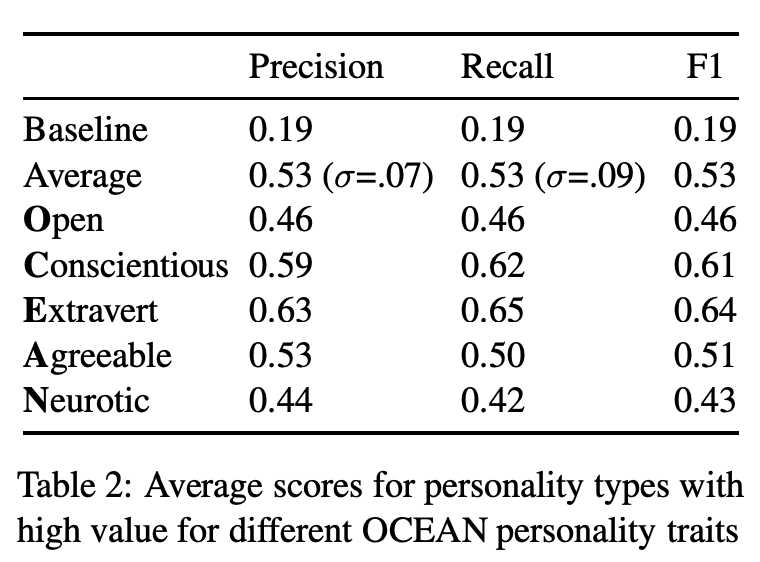
平均して53%のF1スコアを得ることが出来,学習データの範囲を超えてモデルが個性を一般化して捉えている事がわかる 👍
生成した実キャラとエキストリーム設定キャラの応答.// 正確を反映してるっぽいのが面白い

関連研究と結論
スタイルを適用した応答生成は流行り.(Sennrich et al., 2016; Hu et al.,2017; Ficler and Goldberg, 2017; Niu and Bansal,2018).
Yang (2017)では,ドメイン適用の手法を利用して,話者の年齢や性別といった個人情報を利用して条件付けしている.Luan (2017)では,話者のブログ投稿などを利用している.
もっと最近だと,Oraby (2018)では,PERSONAGEという統計型のルールベースの生成器を利用して,レストランドメインの,個性のバリエーションを持つ,人工データコーパスを作った.
今回の自動評価手法は,人を使った定性評価と比べてもだいぶ便利だと思う.今回の研究で,モデルが個性に関連したスタイル情報を保持していることを示し,更に学習データを超えてサーフェイス(見出し)のパターンを学習できていることを示した.
コメント 📔
参考
The text was updated successfully, but these errors were encountered: