We read every piece of feedback, and take your input very seriously.
To see all available qualifiers, see our documentation.
Have a question about this project? Sign up for a free GitHub account to open an issue and contact its maintainers and the community.
By clicking “Sign up for GitHub”, you agree to our terms of service and privacy statement. We’ll occasionally send you account related emails.
Already on GitHub? Sign in to your account
Word Embedding based Edit Distance Yilin Niu, Chao Qiao, Hang Li, Minlie Huang https://arxiv.org/abs/1810.10752
教師なし学習によるテキスト類似度計算方法の提案.単語埋め込みを編集距離に取り込んだ,Word Embedding based Edit Distance (WED)と呼ぶ.3つのデータセットで,SOTAな教師なし学習手法よりも良い結果になった
これまで教師なしの文類似度計算は,編集距離,ジャッカードインデックス,cosine類似度ベースのembedding,などが利用された.外部知識としてWordNetを使う手法もある. 本論ではWEDを提案.シンボル表現とベクター表現の両方を取り込んだ手法になる.
シンボルベース,ニューラルベース,知識ベースの関連手法を提案
編集距離(edit distance)は,テキスト類似度の手法に広く使われている手法.2つの文字列を同じにするために,必要な操作(挿入 insertion,削除 deletion,置換 substituion)の最小回数のことを指す. TF-IDFも同様に広く使われている.TF-IDFは,単語の登場頻度と文書間での単語のレア度をかけ合わせたもの.これをBoWベースで計算して,cosine 類似度を取って,文類似度を計算. 同様にジャッカードインデックスも利用される.
ただしTF-IDFとジャッカードは文の順序を考慮しない
単語埋め込みスタイルとして,Word2VecやGloVeが有名.文ベクトルとして,その文を構成する単語の和などで表す.そして,2つの文ベクトルのcosine類似度を計算とることで,それを距離として定義. Autoencoderも利用される,圧縮された中間層のベクトル表現を利用して,2文の類似度を測る
語彙知識として,WordNetのような知識を利用して文類似度を計算する手法もある.単語間の類似度を利用する.// 具体的にどう計算するかは参照されている論文を読まないとよくわからない
編集距離(ED)と単語埋め込みベースの編集距離(WED)の手法を紹介.
先述の通り,insertion,deletion, substituionを行って,ある単語列(文)からある単語列(文)に変形を行ったときの,最小編集回数となる. EDは下記のように計算する.具体的には,2つの文SAとSBが与えられ,文頭の単語から順に編集動作を行うことで得られる.その際に,insertion/deletion/substitutionの操作で最小となる編集を繰り返していくことで目的単語列に到達する,帰納的な考え.// 言葉で説明すると難しそうに聞こえるが,巻末にアルゴが視覚的に分かるリンクを貼ったのでぜひ腕を動かして見てみてください.
EDの弱点として,意味的な情報を捉えないため,下記のようにlargest/biggestとかhow large/how bigのような類義語が捉えることができない問題がある.
WEDでは,文Aのi番目の単語wAと文Bのj番目の単語wBの類似度を下記のように定義する.
wとbはハイパーパラメタで0から1の値.eA,eBはそれぞれの単語のembedding,σはsigmoid関数(これにより値は0から1の値に収まる).これにより,単語が違っても類義語である場合,高いことが見込まれる.
WEDのアルゴリズムは,コストの計算方法以外同じで下記のようになる λとμは0から1のハイパパラメタで,デフォルト1.simは式3. max...のとのところが,分かりにくいが,w_B^jとSA内の単語(w_A^iは除く)でもっとも高いスコアを示す.
直感的に説明しよう
insertion 文Aのある単語w_A^kが,w_B^jと類義語である場合,文Bへのw_B^jのinsertionコストは通常時より小さい.deletionも同様の考え.
deletion 文Bのある単語w_B^kが,w_A^iと類義語である場合,文Aからw_A^iのdeletionコストは通常時より小さい.
substituion あるwAとwBが類義語である場合,substitutionコストは小さくなる.
また,1 inertion + 1 deletion != 1 substituionとは限らないので注意. // 類義語を探すときにw_A^iとw_B^jを除いている理由は正直良くわからない
EDのときと同じ文を下記に示す.同じ色は類似単語を示す.EDよりうまくいきそうな雰囲気になっているのが分かる.
3つのデータセットを利用.Quora,MSRP,CPC.すべて正解率で評価. Quoraは質問サイトQuoraからリリースされたもので,400kの質問ペアのデータセット.2つの質問文が与えられて,それが重複した質問かどうかの2値がでる MSRPはMS Reserachからリリースされたもので,オンラインニュースの記事から抽出された,5.8kの文ペアである.これも同様に,2つの文が同じかどうかのラベル付がされている. CPCは,2.6kの手作業で作られた,パラフレーズペアである.クラウドワーカーが,与えられた文のパラフレーズを尋ねられるスタイルで作られた.
なお,embeddingは下記の学習済みの辞書を使ったら良い // 著者に問い合わせて確認しました https://arxiv.org/abs/1702.03814
関連研究のところで紹介した教師なし型の,ED,TF-IDF,Embedding(単語embeddingのcos類似度),ジャッカードインデックス,AEをベースラインに利用. さらに教師ありも,QuoraとMSRPで実験した.ここでは2手法試しており,bowのembeddingを加算して文ベクトルを作り,2つの文ベクトルをconcat,これをMLPに流して,似ているかどうかの二値分類を行う(これをBOWと呼ぶ).2つめはLSTMベースで,LSTM+MLPの手法で同様に二値分類(これをLSTMと呼ぶ)
メインの結果をTable 3に示す.WEDがすべての教師なし手法を上回った.更にMSRPでは,教師あり学習の手法も含めて一番良かった.Quoraと比べてMSRPはデータ数が少なく,教師なし学習の強みが生かされる結果となった. 更にMSRPの既存のSOTAは,WordNetなどの外部知識を利用して0.72-0.74である.WEDはそのような外部知識を使わずに,均衡しているのがわかった.
T-testも行い,統計的にWEDがベースラインを上回っていることも確認した.
WEDの分析をした.embeddingを除いて式3の類似度関数を0か1に(-Embedding).式5のコスト関数のλを0にして単語マッチベースのもの(-Context) // μはどうしたんだろうか 結果をTable 5に示す.Embeddingが特によく効いていることが分かる
またラベルありデータ数に応じた正解率を比較した.30kぐらいまで教師なし学習の方が強い.更に通常30kをラベル付するのはかなり大変であることは留意したい.// WEDの正解率が微妙に変化しているように見えるが,一定値である.著者らに確認済み
またエラー分析もQuoraで行った.エラーの50%は,キーワードとノンキーワードの曖昧性によるものだった(??).18%は単語embeddingの不正確さに起因するものだった,例えばwhatとhowは違う意味なので,類似度は小さくなくなるべき.文の構造は無知の状態なので,これに起因するものは16%.残り16%は,ラベルミス,関連のない単語の扱いミス,外部知識の未使用,などのエラーが含まれた
教師なしで単語埋め込みを利用した編集距離を提案.2つの文の類似度を計算する手法を提案した.実験では,既存の教師なし学習より良いパフォーマンスを得,教師あり学習相当のスコアを得た(教師あり学習は,データセットが限定されることに留意).
future workとして
編集距離
ジャッカード・インデックス: |A∩B| / |A∪B| https://mieruca-ai.com/ai/jaccard_dice_simpson/
WordNet: 単語間の概念を示したもの.類義語とか対義語とか.
The text was updated successfully, but these errors were encountered:
Podcastでも解説しました.https://anchor.fm/lnlp-ninja/episodes/ep12-Word-Embedding-based-Edit-Distance-e2g6s1
Sorry, something went wrong.
No branches or pull requests
Word Embedding based Edit Distance
Yilin Niu, Chao Qiao, Hang Li, Minlie Huang
https://arxiv.org/abs/1810.10752
概要
教師なし学習によるテキスト類似度計算方法の提案.単語埋め込みを編集距離に取り込んだ,Word Embedding based Edit Distance (WED)と呼ぶ.3つのデータセットで,SOTAな教師なし学習手法よりも良い結果になった
Introduction
これまで教師なしの文類似度計算は,編集距離,ジャッカードインデックス,cosine類似度ベースのembedding,などが利用された.外部知識としてWordNetを使う手法もある.
本論ではWEDを提案.シンボル表現とベクター表現の両方を取り込んだ手法になる.
Related Work
シンボルベース,ニューラルベース,知識ベースの関連手法を提案
Symbolic Methods
編集距離(edit distance)は,テキスト類似度の手法に広く使われている手法.2つの文字列を同じにするために,必要な操作(挿入 insertion,削除 deletion,置換 substituion)の最小回数のことを指す.
TF-IDFも同様に広く使われている.TF-IDFは,単語の登場頻度と文書間での単語のレア度をかけ合わせたもの.これをBoWベースで計算して,cosine 類似度を取って,文類似度を計算.
同様にジャッカードインデックスも利用される.
ただしTF-IDFとジャッカードは文の順序を考慮しない
Neural Methods
単語埋め込みスタイルとして,Word2VecやGloVeが有名.文ベクトルとして,その文を構成する単語の和などで表す.そして,2つの文ベクトルのcosine類似度を計算とることで,それを距離として定義.
Autoencoderも利用される,圧縮された中間層のベクトル表現を利用して,2文の類似度を測る
Knowledge based Methods
語彙知識として,WordNetのような知識を利用して文類似度を計算する手法もある.単語間の類似度を利用する.// 具体的にどう計算するかは参照されている論文を読まないとよくわからない
手法
編集距離(ED)と単語埋め込みベースの編集距離(WED)の手法を紹介.
編集距離(ED)
先述の通り,insertion,deletion, substituionを行って,ある単語列(文)からある単語列(文)に変形を行ったときの,最小編集回数となる.

EDは下記のように計算する.具体的には,2つの文SAとSBが与えられ,文頭の単語から順に編集動作を行うことで得られる.その際に,insertion/deletion/substitutionの操作で最小となる編集を繰り返していくことで目的単語列に到達する,帰納的な考え.// 言葉で説明すると難しそうに聞こえるが,巻末にアルゴが視覚的に分かるリンクを貼ったのでぜひ腕を動かして見てみてください.
EDの弱点として,意味的な情報を捉えないため,下記のようにlargest/biggestとかhow large/how bigのような類義語が捉えることができない問題がある.

単語埋め込みベースの編集距離(WED)
WEDでは,文Aのi番目の単語wAと文Bのj番目の単語wBの類似度を下記のように定義する.

wとbはハイパーパラメタで0から1の値.eA,eBはそれぞれの単語のembedding,σはsigmoid関数(これにより値は0から1の値に収まる).これにより,単語が違っても類義語である場合,高いことが見込まれる.
WEDのアルゴリズムは,コストの計算方法以外同じで下記のようになる

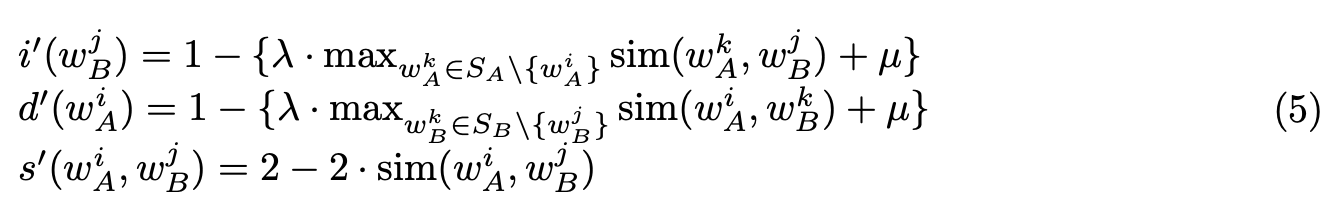

λとμは0から1のハイパパラメタで,デフォルト1.simは式3.
max...のとのところが,分かりにくいが,w_B^jとSA内の単語(w_A^iは除く)でもっとも高いスコアを示す.
直感的に説明しよう
insertion
文Aのある単語w_A^kが,w_B^jと類義語である場合,文Bへのw_B^jのinsertionコストは通常時より小さい.deletionも同様の考え.
deletion
文Bのある単語w_B^kが,w_A^iと類義語である場合,文Aからw_A^iのdeletionコストは通常時より小さい.
substituion
あるwAとwBが類義語である場合,substitutionコストは小さくなる.
また,1 inertion + 1 deletion != 1 substituionとは限らないので注意.
// 類義語を探すときにw_A^iとw_B^jを除いている理由は正直良くわからない
EDのときと同じ文を下記に示す.同じ色は類似単語を示す.EDよりうまくいきそうな雰囲気になっているのが分かる.

実験
データセット
3つのデータセットを利用.Quora,MSRP,CPC.すべて正解率で評価.
Quoraは質問サイトQuoraからリリースされたもので,400kの質問ペアのデータセット.2つの質問文が与えられて,それが重複した質問かどうかの2値がでる
MSRPはMS Reserachからリリースされたもので,オンラインニュースの記事から抽出された,5.8kの文ペアである.これも同様に,2つの文が同じかどうかのラベル付がされている.
CPCは,2.6kの手作業で作られた,パラフレーズペアである.クラウドワーカーが,与えられた文のパラフレーズを尋ねられるスタイルで作られた.
なお,embeddingは下記の学習済みの辞書を使ったら良い // 著者に問い合わせて確認しました
https://arxiv.org/abs/1702.03814
実験設定
関連研究のところで紹介した教師なし型の,ED,TF-IDF,Embedding(単語embeddingのcos類似度),ジャッカードインデックス,AEをベースラインに利用.
さらに教師ありも,QuoraとMSRPで実験した.ここでは2手法試しており,bowのembeddingを加算して文ベクトルを作り,2つの文ベクトルをconcat,これをMLPに流して,似ているかどうかの二値分類を行う(これをBOWと呼ぶ).2つめはLSTMベースで,LSTM+MLPの手法で同様に二値分類(これをLSTMと呼ぶ)
実験結果
メインの結果をTable 3に示す.WEDがすべての教師なし手法を上回った.更にMSRPでは,教師あり学習の手法も含めて一番良かった.Quoraと比べてMSRPはデータ数が少なく,教師なし学習の強みが生かされる結果となった.

更にMSRPの既存のSOTAは,WordNetなどの外部知識を利用して0.72-0.74である.WEDはそのような外部知識を使わずに,均衡しているのがわかった.
T-testも行い,統計的にWEDがベースラインを上回っていることも確認した.

議論
WEDの分析をした.embeddingを除いて式3の類似度関数を0か1に(-Embedding).式5のコスト関数のλを0にして単語マッチベースのもの(-Context) // μはどうしたんだろうか
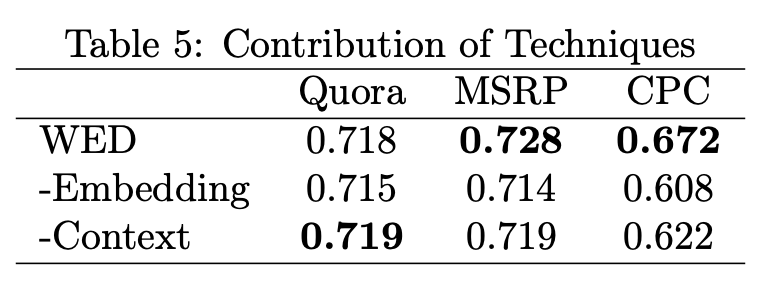
結果をTable 5に示す.Embeddingが特によく効いていることが分かる
またラベルありデータ数に応じた正解率を比較した.30kぐらいまで教師なし学習の方が強い.更に通常30kをラベル付するのはかなり大変であることは留意したい.// WEDの正解率が微妙に変化しているように見えるが,一定値である.著者らに確認済み

またエラー分析もQuoraで行った.エラーの50%は,キーワードとノンキーワードの曖昧性によるものだった(??).18%は単語embeddingの不正確さに起因するものだった,例えばwhatとhowは違う意味なので,類似度は小さくなくなるべき.文の構造は無知の状態なので,これに起因するものは16%.残り16%は,ラベルミス,関連のない単語の扱いミス,外部知識の未使用,などのエラーが含まれた
まとめ
教師なしで単語埋め込みを利用した編集距離を提案.2つの文の類似度を計算する手法を提案した.実験では,既存の教師なし学習より良いパフォーマンスを得,教師あり学習相当のスコアを得た(教師あり学習は,データセットが限定されることに留意).
future workとして
コメント
用語
編集距離
ジャッカード・インデックス: |A∩B| / |A∪B| https://mieruca-ai.com/ai/jaccard_dice_simpson/
WordNet: 単語間の概念を示したもの.類義語とか対義語とか.
The text was updated successfully, but these errors were encountered: