The motivation here is to provide a reference implementation of an API Gateway that can failover to an alternate region automatically when the AWS Lambda (or API Gateway) service is degraded. There have been multiple occurrences of several hour AWS Lambda outages in the recent months. If you built a service on a single region of AWS Lambda, it would be hard to predict an appropriate SLA.
My goal is to provide a reference implementation that has the following properties:
- minimal cost
- automated
- serverless
- easy to understand or modify
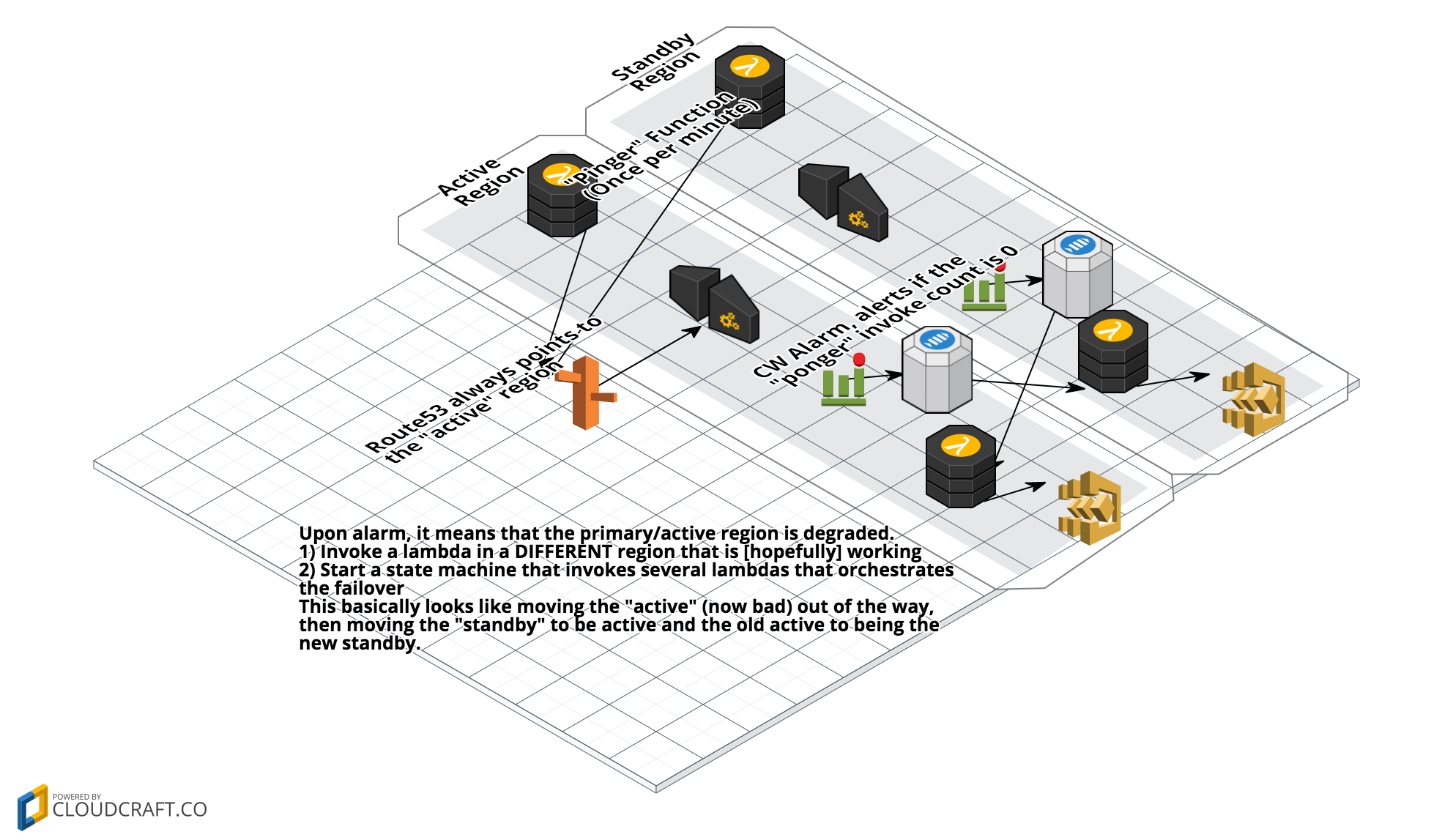
This solution deploys a rather simple ping/pong concept where lambda function in two regions are pinging the active route53 record. This ping endpoint will then invoke the pong lambda function. When the pong lambda function is no longer invoked once per minute, an alarm is triggered.
There are many components of this solution which make it slightly complex. I tried to wrap the complexity into a step function so that it was not a mono-lambda function (a large complex lambda function). The core feature is a cross region invoke that [hopefully] kicks off a process in a working lambda region. I admit, this is hard to test thoroughly and we do not fully know what will or will not be working if lambda is not working. Typically, many services are degraded if Lambda is degraded.
The Kicker Function is responsible for "kicking" off the Step Function (state machine). This will be in a different region than where the alarm is originating (by design). The state machine then invokes a series of lambda functions that will first move the "current active" API Gateway to a temp endpoint, then move the "current standby" to be the new active endpoint, finally move the now temp endpoint to the new standby. Therefore, it is ready for a switch in the opposite direction.
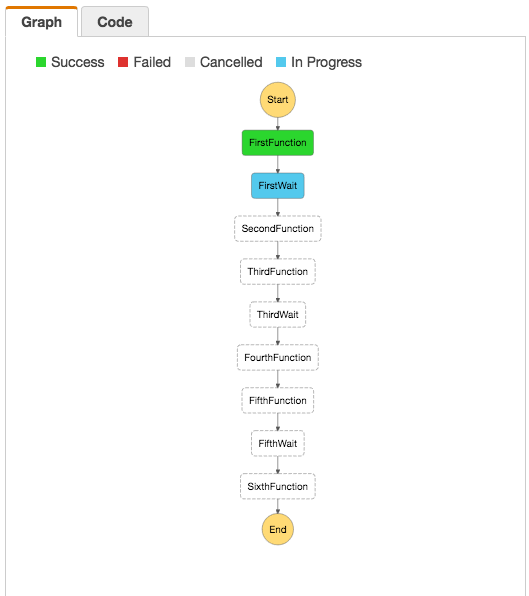
The step function is pretty simple, it doesn't utilize many of the features except retry. The reason for this is because the first implementation was a mono-lambda function and it was approaching the max timeout of 5 minutes. In addition, it was spending a large amount of time in idle, sleeping state.
The Makefile will deploy multiple CloudFormation stacks. Since this is a reference implementation, I included one of my existing projects to show how it would work. The relevant stacks are as follows:
- Ping Pong
Stack
This stack is the entire infrastructure sans the cross region alarm bits below.
The Step Function looks like this:
There are additional helpers in the Makefile to provision this website
I choose to manage the API GW/Lambda/SNS infrastructure inside of CloudFormation
because it represents the most manageable methods available as well as the least
possible way of interfering with existing infrastructure. I actually had a
pretty custom
script
to manage the custom domain in API Gateway, but AWS then released the
AWS::ApiGateway::DomainName which proves only one thing: Once you build
something missing from AWS, they will release it shortly thereafter
To be honest, I learned the most about Step Functions. The rest was just
figuring out the proper boto3 code.
- Step Functions are tricky to get proper syntax (json in yaml, tricky spec to understand, etc)
- Step Functions seem expensive because you are charged per transition. I
assumed that there was some point that a transition would be cheaper than
sleepingin Lambda. So check my math:
Step Functions $0.000025 per state transition
Lambda
$0.000000208 per 100ms
($0.0000002 per request)$0.000025 = $0.000000208 * x invocations x = 120
120 invocations = $0.000024 (lambda requests cost). This is almost the cost of 1 state transition.
120 * 100ms = 12000ms = 12 seconds
12 seconds of lambda runtime is equivalent to 1 state transition. Factor in the request costs, 12 seconds of lambda runtime & 120 invocations is equivalent to 2 state transitions. So, 6 seconds is equivalent to 1 state transition.
Conclusion. If you can get a State Machine to Wait for >6 seconds, it is advantageous to wait there instead of waiting in the lambda runtime.
- This is really hard to simulate! I don't know if it works for all edge cases. I only know that it works for the contrived/manual case.
In the below graph, I manually invoked the standby's region Kicker Function at 11:45. The state machine was running for 15 minutes and the other region was fully active at 12:15 with 2 minutes of 100% downtime. If this was a real lambda failure in the active region, the service would be down for about 30 minutes. I think this can be optimized further by leveraging some parallel jobs.
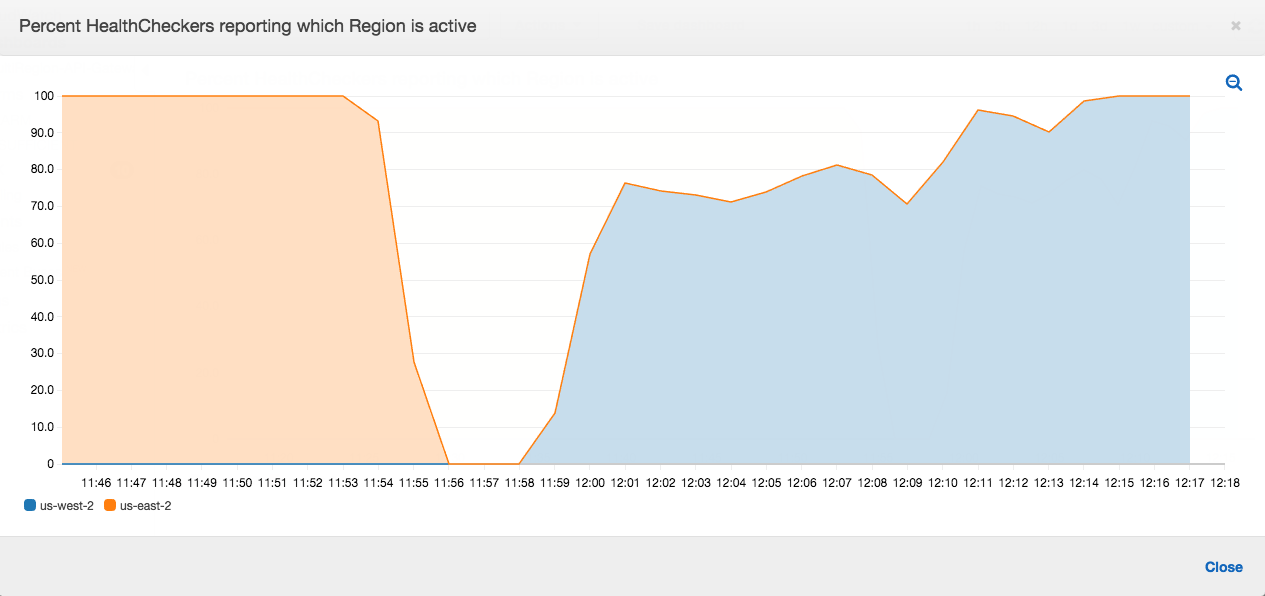
It is important to note that the jagged recovery is due to two factors, one being CloudFront propagation and the other DNS propagation throughout the world.
- The existing project [stack] is now in multiple regions and the standby region will not cost anything extra because it is not running.
- The "ping pong stack" does add some cost:
- Two lambda functions pinging the active endpoint once per minute. Avg: 500ms runtime = 5 * $.000000208 = $0.00000104 * 43800 minutes in a month = $0.045552/month for both functions. Plus 43800 requests, $0.00876/month in requests costs
- The ponger function has the same math (once per minute) but average billed for 100ms duration
- Both requests and duration still falls into the perpetual free tier so it may be negligible in your account.
- API Gateway: 43800 extra requests per month. $3.50/million requests = $0.1533/month for the ping/pong interaction
- State Machine: I'm not quite sure if the AWS console is showing every billed transition or every change. It is showing about 200 transitions to complete a failover. So, maybe $0.05
- There several other lambda functions that get ran for little time. Let's assume $0.005/failover (most time is spent waiting in cloudformation/step function, not lambda runtime)
So, in summary, something like an extra $0.26/month to have a failover on your API Gateway/Lambda based service. Assuming an error in my math, at most $1/month but you may also be in the perpetual free tier so the math is fuzzy.
I will be more than happy to answer any questions on GitHub Issues and review Pull Requests to make this reference even better. Feel free to reach me on Twitter as well.