Cuando trabajamos en soluciones de big data, a menudo es necesario acceder a datos de múltiples fuentes (una base de datos transaccional, un flujo de datos en vivo o contenido web no estructurado almazenado en Amazon S3). Con Amazon Athena es posible agregar los archivos en Amazon S3 y reestructurar los datos para su posterior análisis. Athena es un servicio serverless, por lo que no es necesario configurar ni administrar ninguna infraestructura.
Athena puede usarse para consultar datos estructurados, no estructurados y semiestructurados. Además, Athena se integra con AWS Glue.

- Familiarizarse con Athena en la consola de administración de AWS
- Crear una base de datos
- Crear tablas a partir de datos importados de S3
- Definir columnas y tipos de datos
- Ejecutar consultas simples y complejas
- Un bucket de S3 para almacenar los resultados
- Otro bucket (puede ser el mismo) con este archivo
.csv - El archivo
.csvdebe estar dentro de un directório cualquiera en el bucket y no en la raíz del mismo (por ejemplodata):
-
Acceder al servicio Athena:

-
Lanzar el editor de consultas:

-
Agregar un bucket para almacenar los resultados de las consultas:
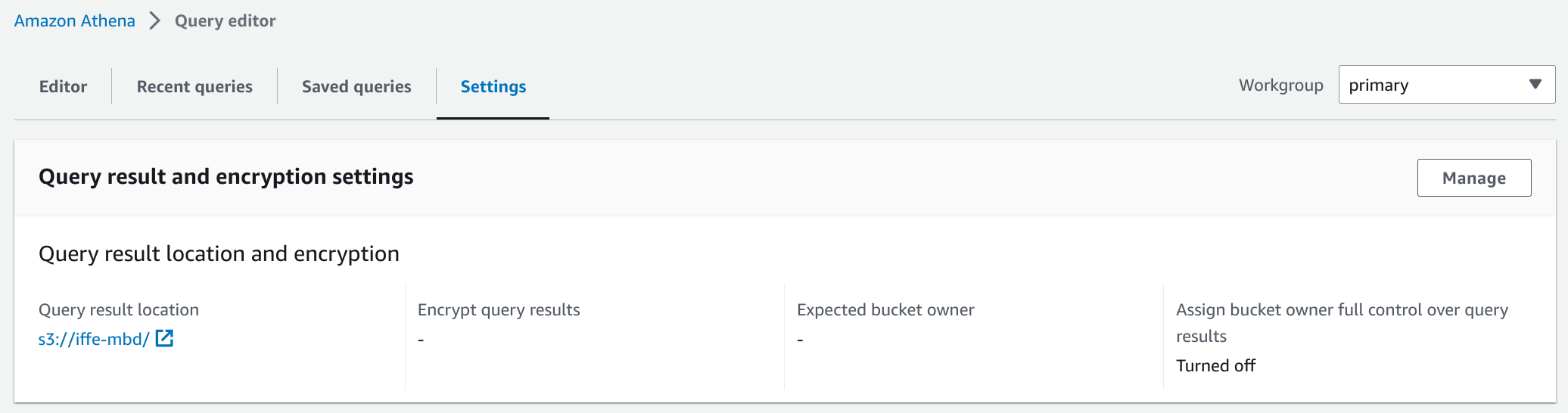
-
Ejecutar la siguiente query para crear una nueva base de datos
customers:CREATE DATABASE customers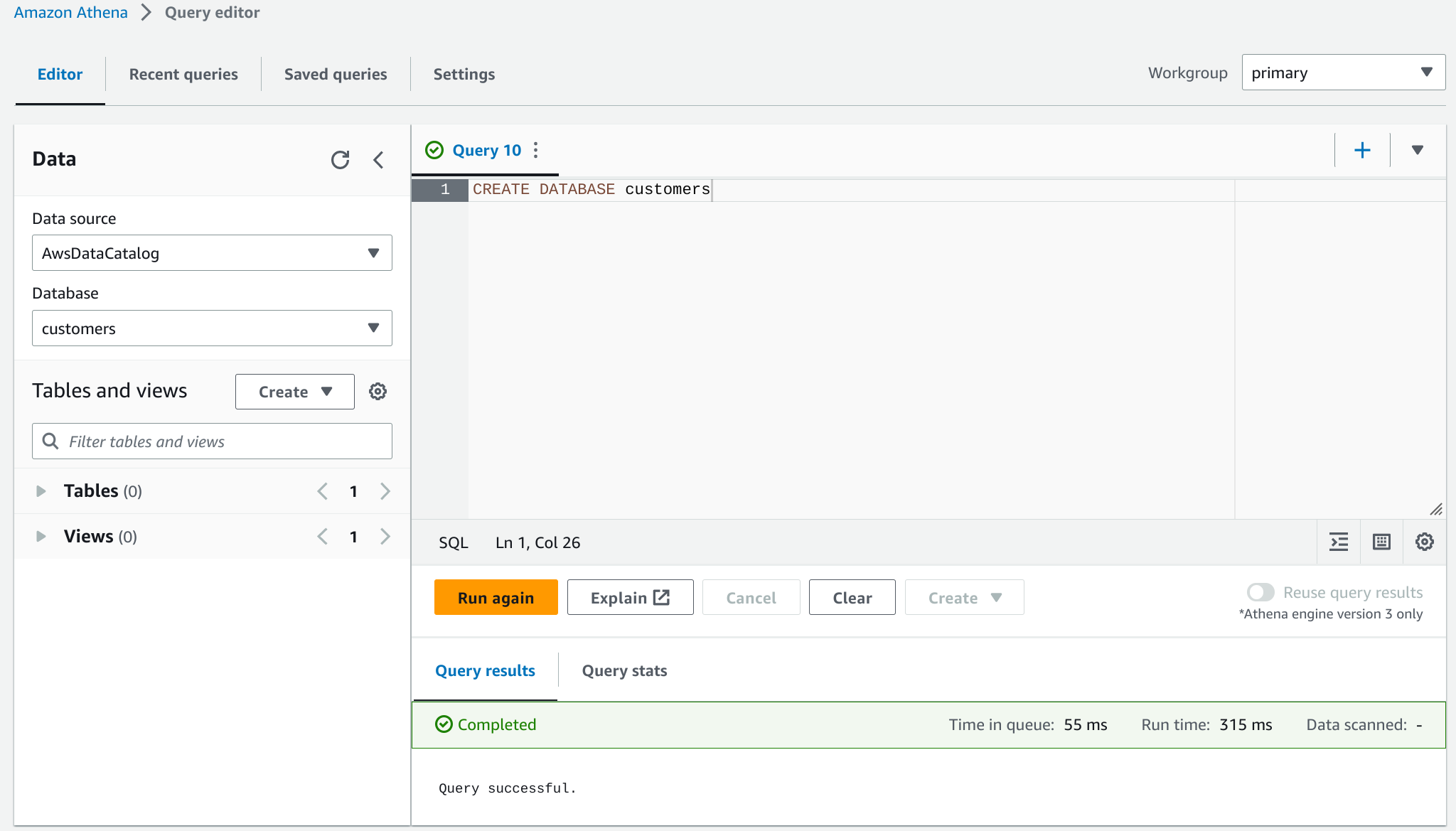
-
Ejecutar la siguiente query para importar los datos del bucket de S3 a una nueva tabla
american_customers:CREATE EXTERNAL TABLE american_customers ( customerID int, first_name string, last_name string, join_date string, street_address string, city string, state string, phone string ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE LOCATION 's3://iffe-mbd/data/' TBLPROPERTIES ('skip.header.line.count'='1')
-
Ejecutar un preview de la tabla recién creada para comprobar que los dados fueron correctamente importados:

- Lista de Customer IDs y Last Names
- Número de clientes de NY
- Crear una nueva tabla
american_customers_normconvirtiendojoin_datede tipo de datostringadate - Número de clientes registrados desde 2014
- Borrar la base de datos y las tablas creadas