Implementation of Image Super Resolution CNN in Keras from the paper Image Super-Resolution Using Deep Convolutional Networks.
Also contains models that outperforms the above mentioned model, termed Expanded Super Resolution, Denoiseing Auto Encoder SRCNN which outperforms both of the above models and Deep Denoise SR, which with certain limitations, outperforms all of the above.
Supports Keras with Theano and Tensorflow backend. Due to recent report that Theano will no longer be updated, Tensorflow is the default backend for this project now.
Note: The project is going to be reworked. Therefore please refer to Framework-Updates.md to see the changes which will affect performance.
The model weights are already provided in the weights folder, therefore simply running :
python main.py "imgpath", where imgpath is a full path to the image.
The default model is DDSRCNN (dsr), which outperforms the other three models. To switch models,
python main.py "imgpath" --model="type", where type = sr, esr, dsr, ddsr
If the scaling factor needs to be altered then :
python main.py "imgpath" --scale=s, where s can be any number. Default s = 2
If the intermediate step (bilinear scaled image) is needed, then:
python main.py "imgpath" --scale=s --save_intermediate="True"
The windows_helper script contains a C# program for Windows to easily use the Super Resolution script using any of the available models.
--model : Can be one of "sr" (Image Super Resolution), "esr" (Expanded SR), "dsr" (Denoiseing Auto Encoder SR), "ddsr" (Deep Denoise SR), "rnsr" (ResNet SR) or "distilled_rnsr" (Distilled ResNet SR)
--scale : Scaling factor can be any integer number. Default is 2x scaling.
--save_intermediate= : Save the intermediate results before applying the Super Resolution algorithm.
--mode : "fast" or "patch". Patch mode can be useful for memory constrained GPU upscaling, whereas fast mode submits whole image for upscaling in one pass.
--suffix : Suffix of the scaled image filename
--patch_size : Used only when patch mode is used. Sets the size of each patch
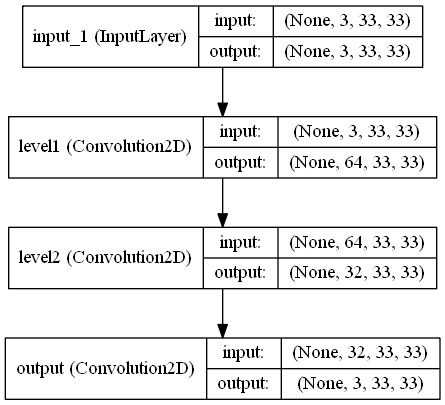
The model above is the simplest model of the ones described in the paper above, consisting of the 9-1-5 model. Larger architectures can be easily made, but come at the cost of execution time, especially on CPU.
However there are some differences from the original paper:
[1] Used the Adam optimizer instead of RMSProp.
[2] This model contains some 21,000 parameters, more than the 8,400 of the original paper.
It is to be noted that the original models underperform compared to the results posted in the paper. This may be due to the only 91 images being the training set compared to the entire ILSVR 2013 image set. It still performs well, however images are slightly noisy.
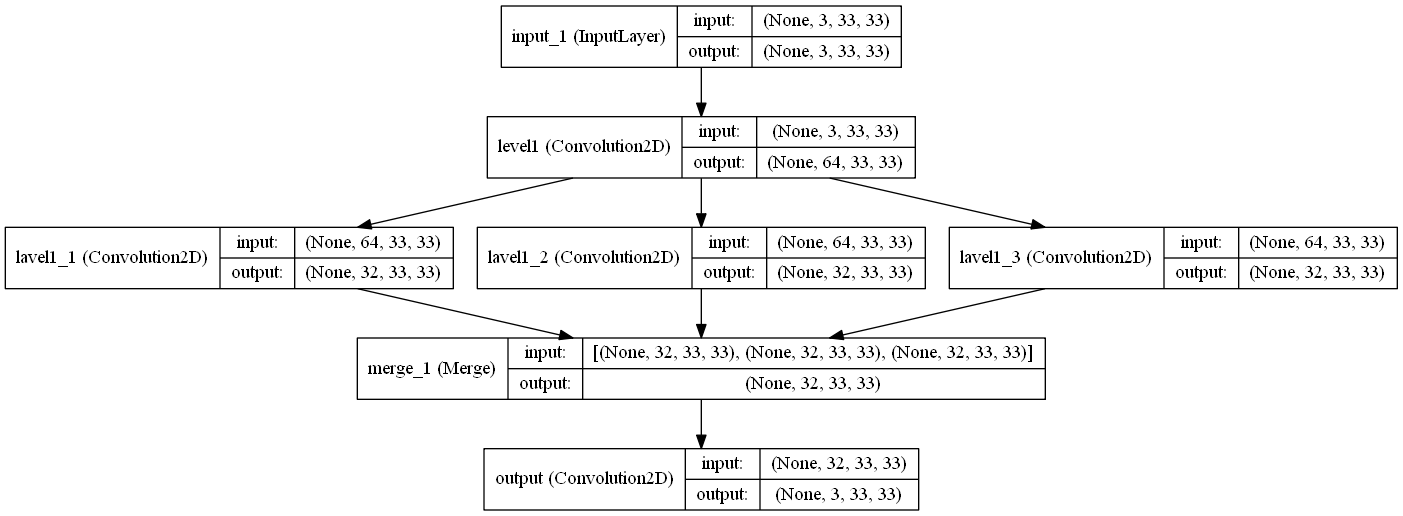
The above is called "Expanded SRCNN", which performs slightly worse than the default SRCNN model on Set5 (PSNR 31.78 dB vs 32.4 dB).
The "Expansion" occurs in the intermediate hidden layer, in which instead of just 1x1 kernels, we also use 3x3 and 5x5 kernels in order to maximize information learned from the layer. The outputs of this layer are then averaged, in order to construct more robust upscaled images.

The above is the "Denoiseing Auto Encoder SRCNN", which performs even better than SRCNN on Set5 (PSNR 32.57 dB vs 32.4 dB).
This model uses bridge connections between the convolutional layers of the same level in order to speed up convergence and improve output results. The bridge connections are averaged to be more robust.
Since the training images are passed through a gausian filter (sigma = 0.5), then downscaled to 1/3rd the size, then upscaled to the original 33x33 size images, the images can be considered "noisy". Thus, this auto encoder quickly improves on the earlier results, and reduces the noisy output image problem faced by the simpler SRCNN model.
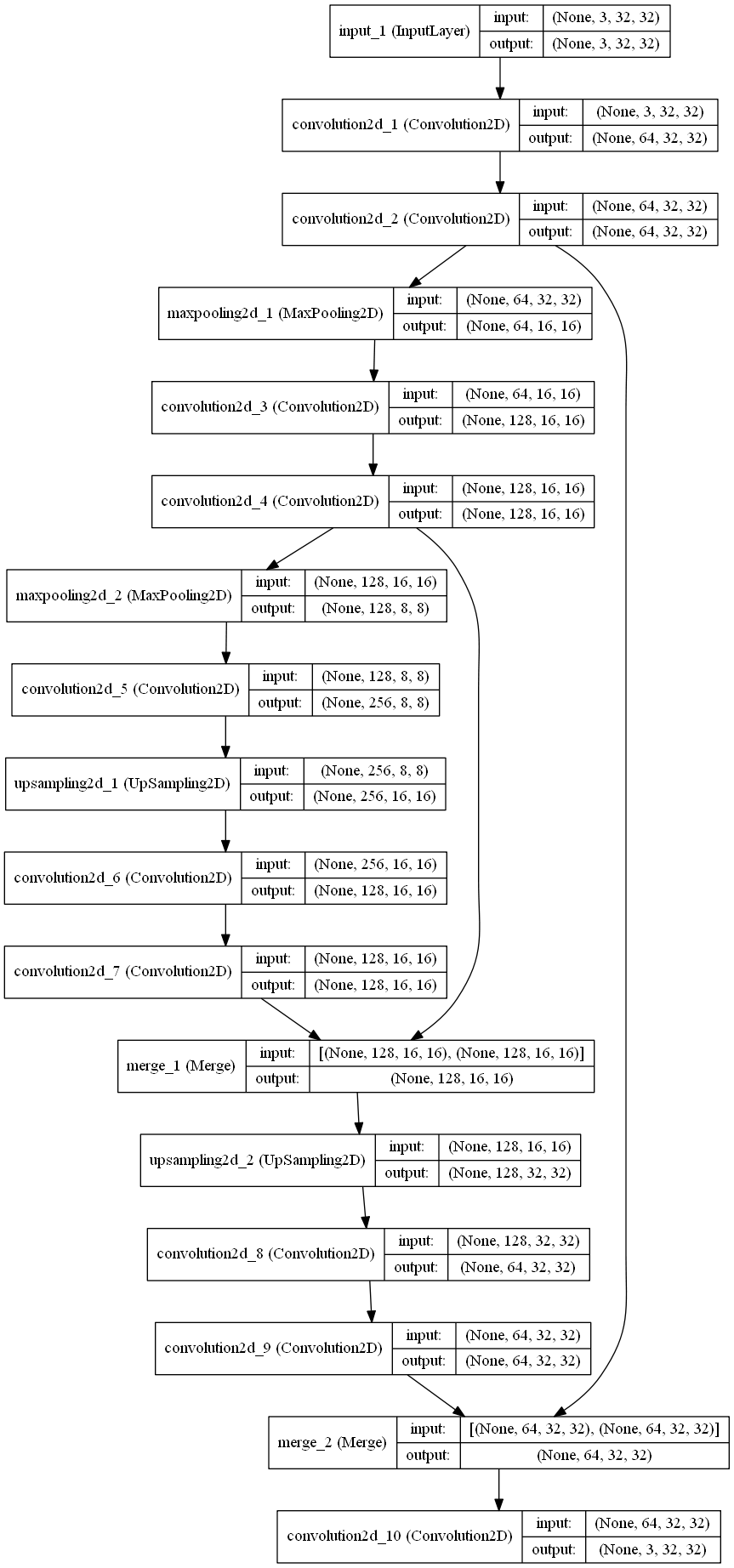
The above is the "Deep Denoiseing SRCNN", which is a modified form of the architecture described in the paper "Image Restoration Using Convolutional Auto-encoders with Symmetric Skip Connections" applied to image super-resolution. It can perform far better than even the Denoiseing SRCNN, but is currently not working properly.
Similar to the paper Image Restoration Using Convolutional Auto-encoders with Symmetric Skip Connections, this can be considered a highly simplified and shallow model compared to the 30 layer architecture used in the above paper.

Currently uses only 6 residual blocks and 2x upscaling rather than the 15 residual blocks and the 4x upscaling from the paper.
The above model is the Efficient Subpixel Convolution Neural Network which uses the Subpixel Convolution layers to upscale rather than UpSampling or Deconvolution. Currently has not been trained properly.
Note : Does not work properly right now.

The model was trained via the distill_network.py script which can be used to perform distilation training from any teacher network onto a smaller 'student' network.

Various issues :
- They break the fully convolutional behaviour of the network. Due to the flatten and reshape parts of this module, you need to have a set size for the image when building it.
Therefore you cannot construct one model and then pass random size input images to evaluate.
- The non local blocks require vast amount of memory as their intermediate products. I think this is the reason they suggested to use this at the end of the network where the spatial dimension is just 14x14 or 7x7.
I had consistent ooms when trying it on multiple positions of a super resolution network, and could only successfully place it at the last ResNet block without oom (on just 4 GB 980M).
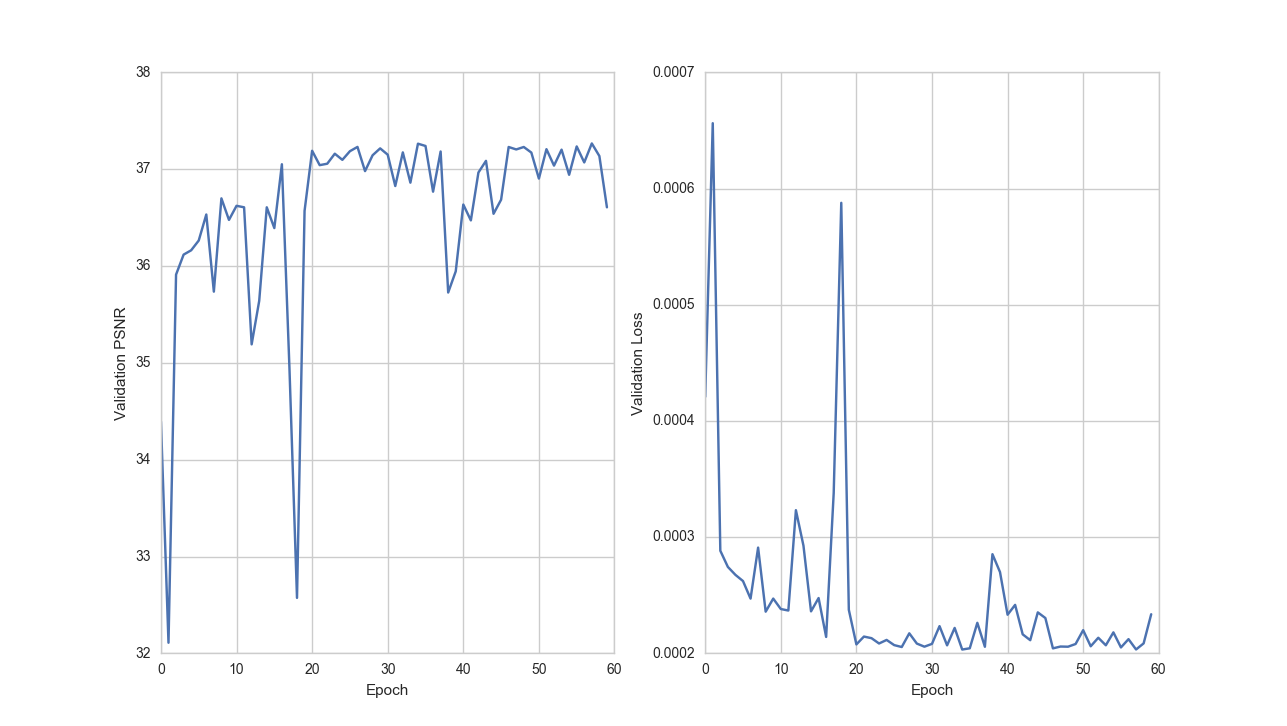
Finally, I was able to train a model anyway and it got pretty high psnr scores. I wasn't able to evaluate that, and was able to distill the model into ordinary ResNet. It got exactly same psnr score as the original non local model. Evaluating that, all the images were a little smoothed out. This is worse than a distilled ResNet which obtains a lower psnr score but sharper images.
If you wish to train the network on your own data set, follow these steps (Performance may vary) :
[1] Save all of your input images of any size in the "input_images" folder
[2] Run img_utils.py function, transform_images(input_path, scale_factor). By default, input_path is "input_images" path.
Note: Unless you are training ESPCNN, set the variable true_upsampling to False and then run the img_utils.py script to generate the dataset. Only for ESPCNN training do you need to set true_upsampling to True.
[3] Open tests.py and un-comment the lines at model.fit(...), where model can be sr, esr or dsr, ddsr.
Note: It may be useful to save the original weights in some other location.
[4] Execute tests.py to begin training. GPU is recommended, although if small number of images are provided then GPU may not be required.
Very large images may not work with the GPU. Therefore,
[1] If using Theano, set device="cpu" and cnmem=0.0 in theanorc.txt
[2] If using Tensorflow, set it to cpu mode
On the CPU, extremely high resolution images of the size upto 6000 x 6000 pixels can be handled if 16 GB RAM is provided.
There are 14 extra images provided in results, 2 of which (Monarch Butterfly and Zebra) have been scaled using both bilinear, SRCNN, ESRCNN and DSRCNN.
Bilinear
 SRCNN
SRCNN
.jpg)
ESRCNN
.jpg) DDSRCNN
DDSRCNN
.png)
Bilinear
 SRCNN
SRCNN
.jpg)
ESRCNN
.jpg) DDSRCNN
DDSRCNN
.png)