Batch Normalization layer gives significant difference between train and validation loss on the exact same data #7265
Comments
|
I too am facing a similar issue, the distribution of activations of the same Conv layer is very different during training and inference on the same data.
The value of |

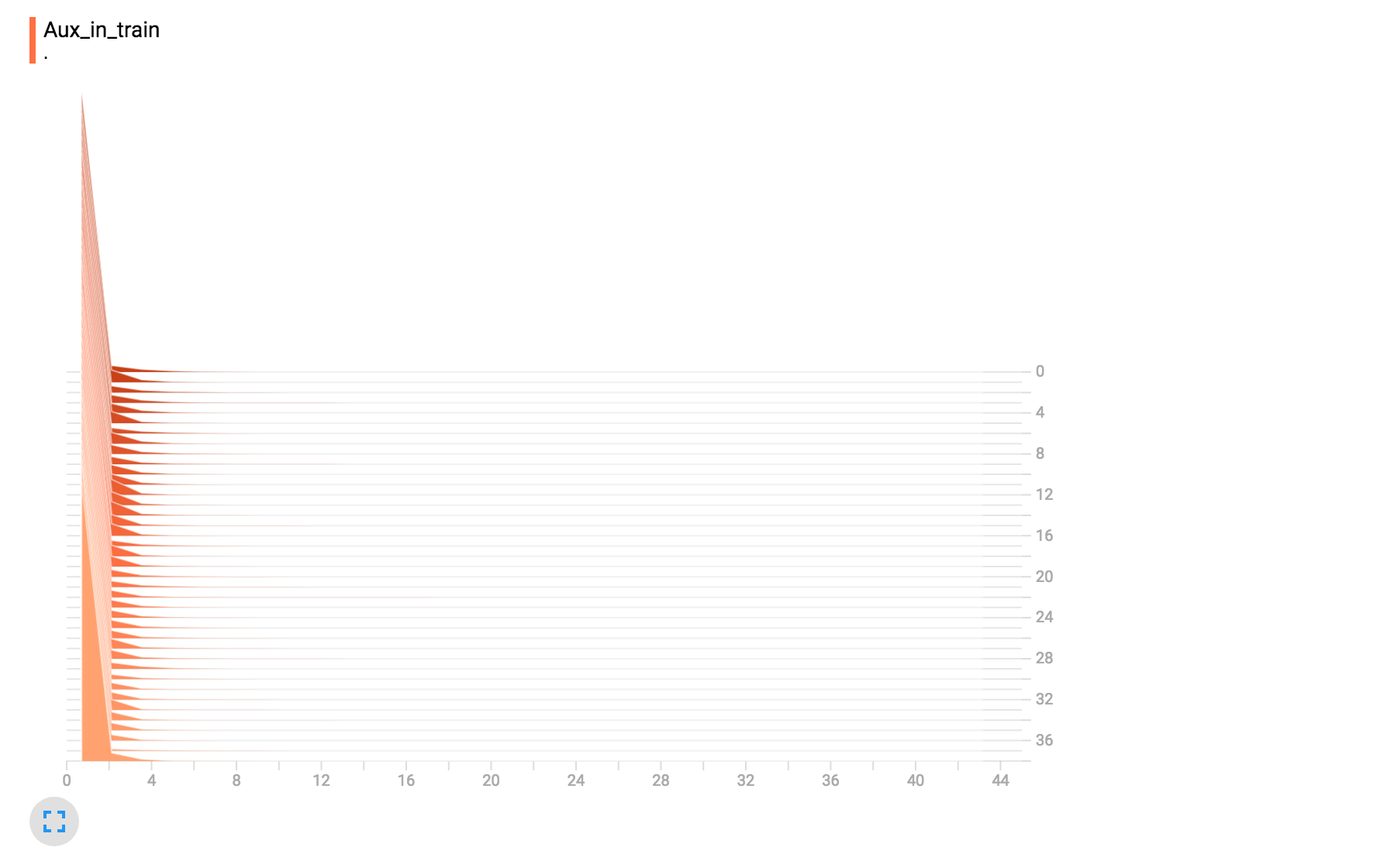
|
After reading the code I understand why I'm getting these results. In training time there are two moving averages that are updated based on each batch - the mean and the variance. These values are supposed to approximate the population statistics. They are initialized to zero and one respectively, and then and each step multiplied by the momentum value (default is 0.99) and added the new value*0.01. At inference (test) time, the normalization uses these statistics. For this reason, it takes these values a little while to arrive at the "real" mean and variance of the data. If I lower the momentum for my specific example, the results makes much more sense... |
|
Hi @izikgo , would you mind share what value you set for momentum? I also came across this issue. |
|
@izikgo Thank you so much for you hint!!! I tried to reduce the momentum and solve it! I guess I need to read the paper to see the meaning of the momentum to understand the reason. |
Hi,
I have a pretty simple gist reproducing the problem: https://gist.github.com/izikgo/2579b8c26231d5c9a5a2c7d313860d33
In short, I get VERY different results between test and validation in a CNN with BN layers, even when I cancel
scaleandcenter, on the exact same data. The data is only a single batch of size 128 from the MNIST dataset.Anyone knows if this is an acceptable behavior? I know that BN acts differently in train and inference, but the difference looks too big to me.
Thanks,
Izik
The text was updated successfully, but these errors were encountered: