

Organize site, sample, and sensor data all in one place!
The goal of rodm2 is to make it easy to use the ODM2 data model in R, in order to promote collaboration between ecologists, hydrologists, and soil scientists. It is intended to help manage complex field data using a sophisticated relational data model without requiring prior knowledge of advanced database principles.
How does it work?
Package functions create parameterized SQL statements to populate and query a flat file (sqlite) database using inputs such as site names, variables, and date ranges. Interactive features (shiny gadgets) are included to facilitate the use of a controlled vocabulary and represent complex hierarchical site and sampling designs within the database structure.
You can install this package from GitHub with:
# install.packages("devtools")
devtools::install_github("khondula/rodm2")- Set up or connect to an ODM2 database file on your computer with
create_sqlite()orconnect_sqlite() - Insert metadata about sites, methods, measured variables using
db_describe_%METADATA TYPE%()functions - Optionally, label sites with annotations and describe hierarchical site designs as related features using
db_annotate()anddb_add_relations() - Insert data from time series, in situ point or profile measurements, or ex situ data from samples collected in the field using
db_insert_results_%RESULT TYPE%() - Query results based on site, variable, and data type (e.g. time series, samples) using
db_get_results()
The basic steps of using rodm2 are:
Load rodm2 and create a connection to your database. If you don't have an existing database, create an empty ODM2 sqlite database and connection using create_sqlite(connect = TRUE) or if you are starting from an existing database use connect_sqlite(). You can view and edit this database using DB Browser for SQLite outside of R.
library(rodm2)
db <- rodm2::create_sqlite(connect = TRUE)Add information about sites, methods, measured variables, etc. using db_describe_%TABLE% functions.
db_describe_site(db,
site_code = "501R1",
sitetypecv = "Site")
#> Site 501R1 has been entered into the samplingfeatures table.
db_describe_method(db,
methodname = "Sonic anemometer",
methodcode = "SA",
methodtypecv = "dataRetrieval")
#> Sonic anemometer has been added to the Methods table.Optionally, use annotations and relationships with db_annotate() and db_add_relations() to label site groups and represent sampling designs.
Data are uploaded using "insert" functions for specific types of results such as time series, samples, measurements, or a vertical profile. For time series data, the data to upload should have data values for one or more variables collected at one site using the same instrument. It needs at least 2 timepoints, and a "Timestamp column" formatted as YYYY-MM-DD HH:MM:SS. For example:
| Timestamp | wd | ws | gustspeed |
|---|---|---|---|
| 2018-06-27 13:45:00 | 180 | 1.0 | 2.0 |
| 2018-06-27 13:55:00 | 170 | 1.5 | 2.5 |
The type of data in each column needs to be described in a "variables list" with terms and units from a controlled vocabulary. Create this list for a dataset using a shiny gadget (opens in the Viewer pane of RStudio) with the function make_vars_list().
vars_list <- make_vars_list(ts_data)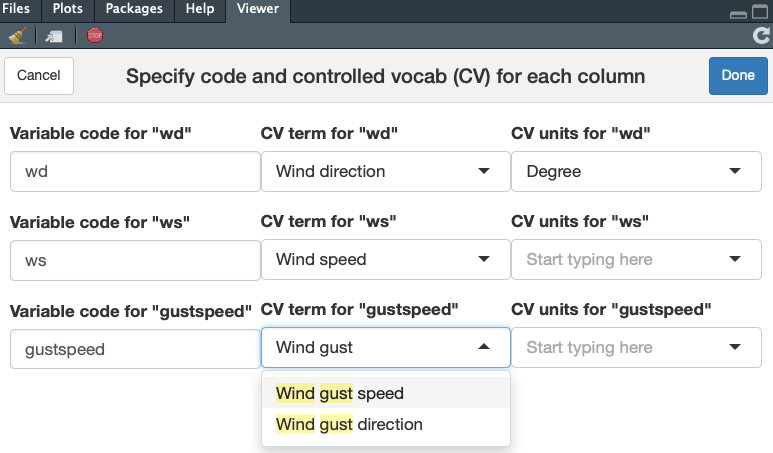
Once the vars_list is created, use it in the db_insert_results_ts() function to upload data along with its associated metadata
db_insert_results_ts(db,
datavalues = ts_data,
methodcode = "SA",
site_code = "501R1",
variables = vars_list,
sampledmedium = "air")
#> Warning: Closing open result set, pending rowsData associated with samples taken in the field and a property measured in the lab needs to have at least 4 columns corresponding to Timestamp, Site ID, Sample ID, and data value.
| Timestamp | Site | Sample | DOC |
|---|---|---|---|
| 2018-06-27 13:45:00 | 501R1 | DOC001 | 10.0 |
| 2018-07-27 13:55:00 | 501R1 | DOC002 | 12.3 |
Sample data are inserted with db_insert_results_samples() which requires metadata about both the method used to collect samples as well as the method used to analyze the sample. Provide details using db_describe_%METADATA%() functions.
db_describe_method(db, methodname = "Shimadzu",
methodtypecv = "specimenAnalysis",
methodcode = "Shimadzu")
#> Warning: Closing open result set, pending rows
#> Shimadzu has been added to the Methods table.
db_describe_method(db, methodname = "Water sample",
methodtypecv = "specimenCollection",
methodcode = "watersamp")
#> Water sample has been added to the Methods table.vars_list <- make_vars_list(sample_data)db_insert_results_samples(db,
sample_data,
field_method = "watersamp",
lab_method = "Shimadzu",
variables = vars_list,
sampledmedium = "liquidAqueous")
#> DOC has been added to the Variables table.
#> Sample DOC001 and associated data have been entered.
#> Sample DOC002 and associated data have been entered.The insert function assumes that Site IDs are in a column called "Site" and Sample IDs are in a column called "Sample" but you can specify otherwise with the arguments site_code_col and sample_code_col. See more options for specifying metadata in the documentation for db_insert_results_samples()
db_get_results() returns a list of dataframes with each type of result requested. By default retrieves data associated with all site codes and variables.
results_data <- db_get_results(db, result_type = c("ts", "sample"))
str(results_data)
#> List of 3
#> $ Time_series_data:'data.frame': 6 obs. of 6 variables:
#> ..$ ValueDateTime : chr [1:6] "2018-06-27 13:55:00" "2018-06-27 13:45:00" "2018-06-27 13:45:00" "2018-06-27 13:55:00" ...
#> ..$ DataValue : num [1:6] 170 180 1 1.5 2 2.5
#> ..$ UnitsName : chr [1:6] "Degree" "Degree" "Meter per Second" "Meter per Second" ...
#> ..$ VariableNameCV : chr [1:6] "Wind direction" "Wind direction" "Wind speed" "Wind speed" ...
#> ..$ SamplingFeatureCode: chr [1:6] "501R1" "501R1" "501R1" "501R1" ...
#> ..$ ProcessingLevelCode: chr [1:6] "Raw data" "Raw data" "Raw data" "Raw data" ...
#> $ Sample_data :'data.frame': 2 obs. of 7 variables:
#> ..$ ValueDateTime : chr [1:2] "2018-06-27 13:45:00" "2018-07-27 13:55:00"
#> ..$ DataValue : num [1:2] 10 12.3
#> ..$ UnitsName : chr [1:2] "Milligram per Liter" "Milligram per Liter"
#> ..$ VariableNameCV : chr [1:2] "Carbon, dissolved organic" "Carbon, dissolved organic"
#> ..$ SamplingFeatureCode: chr [1:2] "DOC001" "DOC002"
#> ..$ ProcessingLevelCode: chr [1:2] "Raw data" "Raw data"
#> ..$ Site : chr [1:2] "501R1" "501R1"
#> $ Measurement_data: NULLUse list subsetting to get a data frame with time series (ts) results.
ts_data <- results_data[["Time_series_data"]]
# OR
ts_data <- results_data$Time_series_data
head(ts_data)
#> ValueDateTime DataValue UnitsName VariableNameCV
#> 1 2018-06-27 13:55:00 170.0 Degree Wind direction
#> 2 2018-06-27 13:45:00 180.0 Degree Wind direction
#> 3 2018-06-27 13:45:00 1.0 Meter per Second Wind speed
#> 4 2018-06-27 13:55:00 1.5 Meter per Second Wind speed
#> 5 2018-06-27 13:45:00 2.0 Meter per Second Wind gust speed
#> 6 2018-06-27 13:55:00 2.5 Meter per Second Wind gust speed
#> SamplingFeatureCode ProcessingLevelCode
#> 1 501R1 Raw data
#> 2 501R1 Raw data
#> 3 501R1 Raw data
#> 4 501R1 Raw data
#> 5 501R1 Raw data
#> 6 501R1 Raw datarodm2 is being designed to work either with an existing ODM2 database on a server (e.g. PostgreSQL), or with spreadsheet files that aren't (yet!) in a relational database. This package is intended to help populate, query, and visualize data that is organized with the ODM2 structure. It should not be necessary to understand ODM2 or SQL but it may help! See here for an overview of the data structure.
This project is made possible through support from rOpenSci and SESYNC.
Read about the details and development of ODM2 in the open access paper in Environmental Modelling & Software:
Horsburgh, J. S., Aufdenkampe, A. K., Mayorga, E., Lehnert, K. A., Hsu, L., Song, L., Spackman Jones, A., Damiano, S. G., Tarboton, D. G., Valentine, D., Zaslavsky, I., Whitenack, T. (2016). Observations Data Model 2: A community information model for spatially discrete Earth observations, Environmental Modelling & Software, 79, 55-74, http://dx.doi.org/10.1016/j.envsoft.2016.01.010