embetter: better embeddings #15
Assignees

Comments
Embetter: making better embeddings.So how might we go about making our embeddings a bit more "specific"? I think the main thing to do is to have a human steer it by labeling.
But how do we connect the two? By training an embedding on top of the encoder!
|

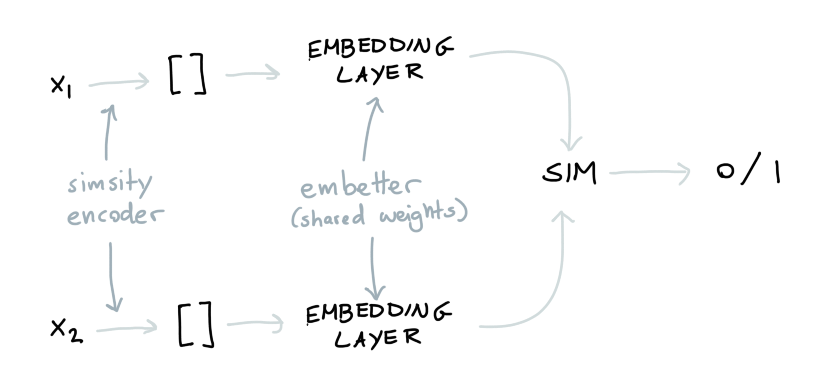
|
The idea is that this will allow us to "fine-tune" what similarity actually means in our embedded space.
I'm not sure if this is best done by having another package out there called |

|
Aaaaand it's going in a seperate repo. https://github.com/koaning/embetter |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
This is conceptual work in progress. The maintainer is actively researching this, please do not work on it.
Problem Statement
When you submit
where is my phooneand you get similarities you may get things like:where is my phonewhere is my credit cardDepending on your task, either the "where is" part of the sentence is more important or the "phone" part is more important. The encoder, however, may be very brittle when it comes to spelling errors. So to put it more generally;
The similarity in an embedded space in our case is very much "general". I'm using "general" here, as opposed to "specific" to indicate that these similarities have been constructed without having a task in mind.
Similar Issue
Suppose that we are deduplicating and we have a zipcode, city, first-, and last-name. How would our encoding be able to understand that having the same city is not a strong signal while having the first name certainly is? Can we really expect a standard encoding to understand this? Without labels ... I think not.
The text was updated successfully, but these errors were encountered: