Graph Scope #7
Comments
|
I tried the following code import torch
import torch.nn as nn
from torch.autograd.variable import Variable
import torch.nn.functional as F
from collections import OrderedDict
from tensorboard import SummaryWriter
class M(nn.Module):
def __init__(self):
super().__init__()
self.conv_0 = nn.Conv2d(1,1,3)
self.conv_1 = nn.Conv2d(1,1,3)
self.conv_r1 = nn.Conv2d(1,1,5)
self.fc1 = nn.Linear(2,1)
self.fc2 = nn.Linear(1,1)
def forward(self,i):
# i stand as the input
# conv_j is a module
x = self.conv_0(i)
x = self.conv_1(x)
y = self.conv_r1(i)
z = torch.cat((y,x),1)
z = z.view(len(z),-1)
z = self.fc1(z)
z = F.relu(z)
z = self.fc2(z)
z = F.log_softmax(z)
return z
writer = SummaryWriter('runbug')
m = M()
z = m(Variable(torch.Tensor(1,1,5,5), requires_grad=True))
writer.add_graph(m, z)
writer.close()The result seems correct, can you provide a runnable code to reproduce the first graph?
As for defining scope for modules, it needs to retrieve the module name associated with certain function object. I will look into it in the future. |
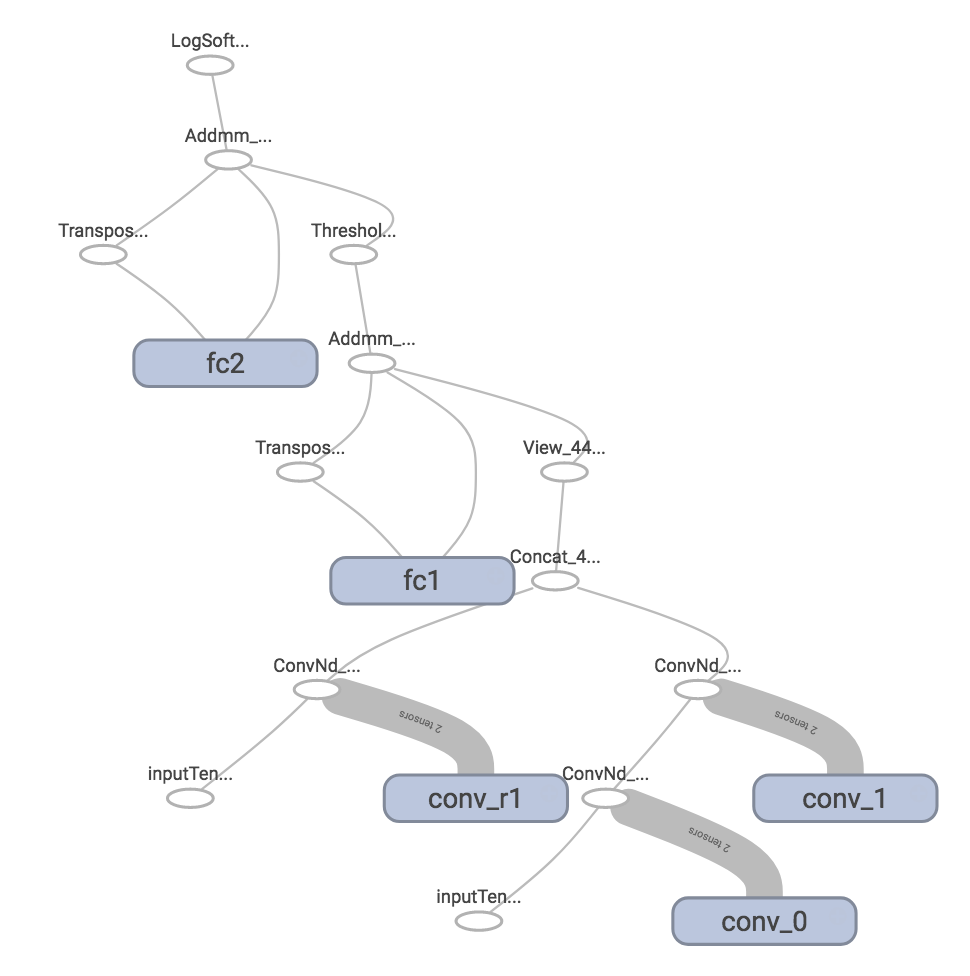
|
Using your code everything works fine, but if you introduce ReLU and MaxPooling you get this:
|
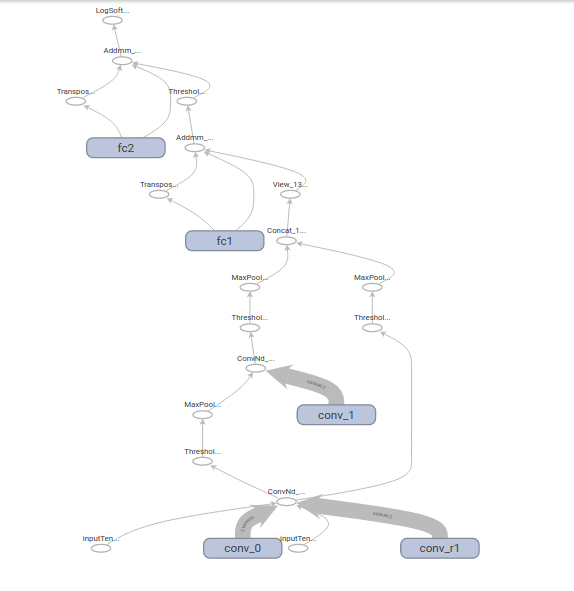
|
OK, I just found a more compact network to reproduce strange output: class M(nn.Module):
def __init__(self):
super(M,self).__init__()
self.conv_x1 = nn.Conv2d(1,1,3)
self.conv_x2 = nn.Conv2d(1,1,4)
self.conv_y = nn.Conv2d(1,1,6)
def forward(self,i):
x = self.conv_x1(i)
x = self.conv_x2(x)
x = F.relu(x)
y = self.conv_y(i)
y = F.relu(y)
z = torch.cat((x,y),1)
return z |
|
As far as i can see your network seems fine to me. Leads to strange behaviours.
P.S. I'm a bit puzzled about the input tensors, sometimes I can't get them rendered (as in this last figure). |
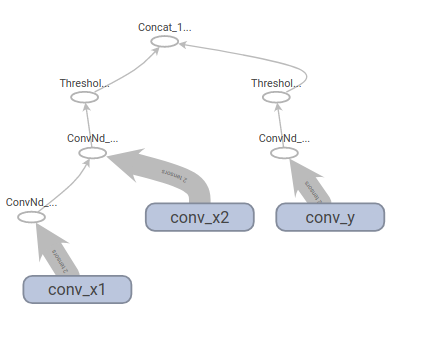

|
Did you set |
|
I completely forgot it, that makes a lot of sense :) Yeah that could explains it all...unfortunately autograd is used only in Pytorch as far as i know, so we can't just compile the same network under TF to check if the graphs match. Thank you in advance anyway, I'll try to look at the code behind in my spare time :) |
|
is it possible to keep the module operations inside the layer block (scope)? Right now it only seems to associate weights with the scope, but it would be nice to assign the module's forward operations to the scope as well |
|
You mean to have every layers inside a user-defined module inside a single block with the name od the module? |
|
no, I meant the operations related to a given nn.Module being inside that module's scope. If you add a graph for 2 linear layers you get 2 scopes one for each, containing only the weight and bias variables while the operations over theses variables are shown outside the scope. It would be nice to have operations like the |
|
For the ```addmul`` case it should be easy to implement, because in fact the operation lies in the same module (the Linear one), while for the the threshold (AKA ReLU , Sigmoid, etc) I'm not quite sure since it has its own module (which you usually add in forward using F.relu() as example), so I think we need the equivalent of the scope from TF. |
|
I think the activations should be outside if you define them outside, anyway! By doing that the graph would be much cleaner |
|
The name of variable comes from |
Hi,
I'm a Pytorch beginner (previously working on th and tf) using your tensorboard-pytorch bridge to get some info during neural net training. It works like a charm for everything i've needed since now :). However i'm having some troubles with the graph visualization for some ConvNet and i've a few questions:
Btw great work :)
The text was updated successfully, but these errors were encountered: