本篇文章可能不是教你如何基于注解实现Spring,仅仅是本人手写实现Spring 注解注入的时候一点心得,如果发现有错误,还望告知,github链接:https://github.com/laowenruo/Spring-IOC
- @Retention:用于注解定义上,表示注解的生命周期,常见有RetentionPolicy.RUNTIME(运行时)
- @Target:用于注解定义上,常用于表示自定义的注解能用在哪个地方上,常见有ElementType.TYPE(类)
- @Component:用于类,表示为IOC容器托管的Bean
- @Scope:用于类,默认为单例,也可设置为原型
- @Autowired:用于属性,表示向属性自动注入容器中对应类型的 bean
- @Qualifier:用于属性,传递字符串,表示给这个属性注入对应名称的 bean,常与@Resource结合使用
- @Value:用于属性,表示向这个属性注入某个值(基本类型)
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
public @interface Component {
String name() default "";
}
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
public @interface Scope {
String value() default "singleton"; //默认为单例模式
}
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.FIELD)
public @interface Autowired{}
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.FIELD)
public @interface Qualifier {
String value();
}
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.FIELD)
public @interface Value {
String value();
}由于不是自动装配,故我们要在配置文件中引入自动扫描
<?xml version="1.0" encoding="UTF-8"?>
<beans>
<component-scan base-package="XXX.XXX"/>
</beans>由于我们之前定义的 XmlBeanDefinitionReader仅仅是通过dom解析到XML中的各种属性来装入工厂,这时候我们使用注解注入时,就应该修改方法,如果扫描包的时候发现有注解属性,就优先进行注解的调用,并且这个扫描是递归扫描的
protected void parseBeanDefinitions(Element root) {
...
for(int i = 0; i < nodeList.getLength(); i ++) {
if(nodeList.item(i) instanceof Element) {
Element ele = (Element)nodeList.item(i);
if(ele.getTagName().equals("component-scan")) {
basePackage = ele.getAttribute("base-package");
break;
}
}
}
if(basePackage != null) {
parseAnnotation(basePackage); //递归扫描方法
return;
}
...
}parseAnnotation() 方法获取到目标包下所有的类,并遍历解析:
protected void parseAnnotation(String basePackage) {
Set<Class<?>> classes = getClasses(basePackage); //表示获取包下所有的类
for(Class clazz : classes) {
processAnnotationBeanDefinition(clazz);
}
}我们在学习反射的时候,是知道由getAnnotation()方法来获取注解的,这也就是注解注入的一个重要方法了,获取注解来处理相应的操作,注入的时候就看注解的值了
protected void processAnnotationBeanDefinition(Class<?> clazz) {
if(clazz.isAnnotationPresent(Component.class)) {
String name = clazz.getAnnotation(Component.class).name();
if(name == null || name.length() == 0) {
name = clazz.getName();
}
String className = clazz.getName();
boolean singleton = true;
if(clazz.isAnnotationPresent(Scope.class) && "prototype".equals(clazz.getAnnotation(Scope.class).value())) {
singleton = false;
}
BeanDefinition beanDefinition = new BeanDefinition();
processAnnotationProperty(clazz, beanDefinition);
beanDefinition.setBeanClassName(className);
beanDefinition.setSingleton(singleton);
getRegistry().put(name, beanDefinition);
}
}processAnnotationProperty() 则是对类的每一个属性进行判断,来确定每个属性是否需要注入等:
protected void processAnnotationProperty(Class<?> clazz, BeanDefinition beanDefinition) {
Field[] fields = clazz.getDeclaredFields();
for(Field field : fields) {
String name = field.getName();
if(field.isAnnotationPresent(Value.class)) {
Value valueAnnotation = field.getAnnotation(Value.class);
String value = valueAnnotation.value();
if(value != null && value.length() > 0) {
// 优先进行值注入
beanDefinition.getPropertyValues().addPropertyValue(new PropertyValue(name, value));
}
} else if(field.isAnnotationPresent(Autowired.class)) {
if(field.isAnnotationPresent(Qualifier.class)) {
Qualifier qualifier = field.getAnnotation(Qualifier.class);
String ref = qualifier.value();
if(ref == null || ref.length() == 0) {
throw new IllegalArgumentException("the value of Qualifier should not be null!");
}
BeanReference beanReference = new BeanReference(ref);
beanDefinition.getPropertyValues().addPropertyValue(new PropertyValue(name, beanReference));
} else {
String ref = field.getType().getName();
BeanReference beanReference = new BeanReference(ref);
beanDefinition.getPropertyValues().addPropertyValue(new PropertyValue(name, beanReference));
}
}
}
}其实跟前篇文章的XML解析流程差不多,只是将XML的读取换成了注解的读取
- 定义Application对象传入配置文件,并且对配置文件中需要扫描的包进行扫描
- 遍历包下的所有类,并且提取出有注解的类
- 对类中有需要的属性等设置到工厂中
- 工厂对类中的属性依次判断并且运用反射注入值,设置填充完毕属性并且实例化的bean
-
-
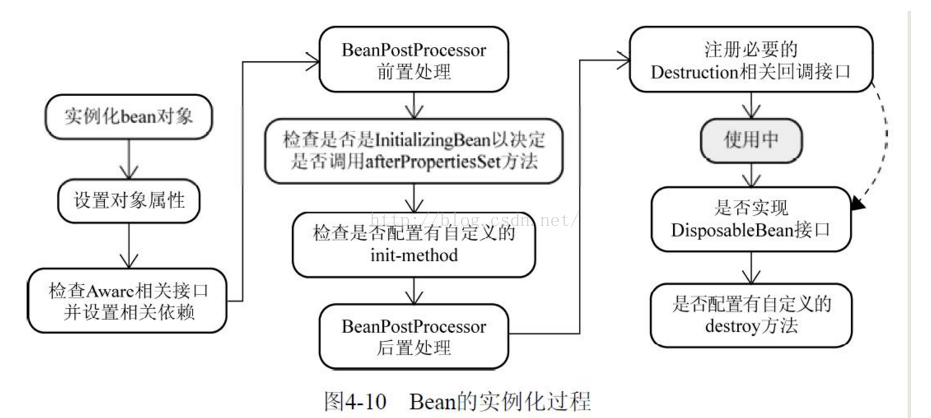
spring bean从创建到销毁大致过程:实例化、属性注入、初始化、使用、销毁,
-
实例化:调用构造函数为对象分配空间
-
属性设置:设置bean属性
-
如果通过Aware接口声明了依赖关系,则会注入Bean对容器基础设施层面的依赖,Aware接口是为了感知到自身的一些属性。如BeanNameAware接口,可以知道自己在容器中的名字。 如果这个Bean已经实现了BeanFactoryAware接口,可以用这个方式来获取其它Bean。
-
紧接着会调用BeanPostProcess的前置初始化方法postProcessBeforeInitialization,主要作用是在Spring完成实例化之后,初始化之前,对Spring容器实例化的Bean添加自定义的处理逻辑。有点类似于AOP。
-
如果实现了BeanFactoryPostProcessor接口的afterPropertiesSet方法,做一些属性被设定后的自定义的事情。
-
调用Bean自身定义的init方法,去做一些初始化相关的工作。(这个时候对象的bean才初始化)
-
调用BeanPostProcess的后置初始化方法,postProcessAfterInitialization去做一些bean初始化之后的自定义工作。
-
完成以上创建之后就可以在应用里使用这个Bean了。
-
当Bean不再用到,便要销毁 1,若实现了DisposableBean接口,则会调用destroy方法; 2,若自定义了销毁方法,则调用自定义的销毁方法
部分内容参考来自https://4m.cn/F26GP