forked from stephaniehicks/jhustatcomputing2022
-
Notifications
You must be signed in to change notification settings - Fork 4
/
index.qmd
812 lines (567 loc) · 38.2 KB
/
index.qmd
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
490
491
492
493
494
495
496
497
498
499
500
501
502
503
504
505
506
507
508
509
510
511
512
513
514
515
516
517
518
519
520
521
522
523
524
525
526
527
528
529
530
531
532
533
534
535
536
537
538
539
540
541
542
543
544
545
546
547
548
549
550
551
552
553
554
555
556
557
558
559
560
561
562
563
564
565
566
567
568
569
570
571
572
573
574
575
576
577
578
579
580
581
582
583
584
585
586
587
588
589
590
591
592
593
594
595
596
597
598
599
600
601
602
603
604
605
606
607
608
609
610
611
612
613
614
615
616
617
618
619
620
621
622
623
624
625
626
627
628
629
630
631
632
633
634
635
636
637
638
639
640
641
642
643
644
645
646
647
648
649
650
651
652
653
654
655
656
657
658
659
660
661
662
663
664
665
666
667
668
669
670
671
672
673
674
675
676
677
678
679
680
681
682
683
684
685
686
687
688
689
690
691
692
693
694
695
696
697
698
699
700
701
702
703
704
705
706
707
708
709
710
711
712
713
714
715
716
717
718
719
720
721
722
723
724
725
726
727
728
729
730
731
732
733
734
735
736
737
738
739
740
741
742
743
744
745
746
747
748
749
750
751
752
753
754
755
756
757
758
759
760
761
762
763
764
765
766
767
768
769
770
771
772
773
774
775
776
777
778
779
780
781
782
783
784
785
786
787
788
789
790
791
792
793
794
795
796
797
798
799
800
801
802
803
804
805
806
807
808
809
810
811
812
---
title: "24 - Best practices for data analyses"
author:
- name: Leonardo Collado Torres
url: http://lcolladotor.github.io/
affiliations:
- id: libd
name: Lieber Institute for Brain Development
url: https://libd.org/
- id: jhsph
name: Johns Hopkins Bloomberg School of Public Health Department of Biostatistics
url: https://publichealth.jhu.edu/departments/biostatistics
description: "A noncomprehensive set of best practices for building data analyses"
categories: [module 6, week 8, best practices]
---
*This lecture, as the rest of the course, is adapted from the version [Stephanie C. Hicks](https://www.stephaniehicks.com/) designed and maintained in 2021 and 2022. Check the recent changes to this file through the `r paste0("[GitHub history](https://github.com/lcolladotor/jhustatcomputing2023/commits/main/", basename(dirname(getwd())), "/", basename(getwd()), "/index.qmd)")`.*
# Pre-lecture materials
### Acknowledgements
Material for this lecture was borrowed and adopted from
- <https://teachdatascience.com/philosophy>
- <https://teachdatascience.com/closing2020>
- [Sharing biological data: why, when, and how](https://febs.onlinelibrary.wiley.com/doi/10.1002/1873-3468.14067)
- <https://github.com/genomicsclass/labs/blob/master/eda/plots_to_avoid.Rmd>
- <http://jtleek.com/advdatasci/09-expository-graphs.html>
# Learning objectives
::: callout-note
# Learning objectives
**At the end of this lesson you will:**
Be able to state best practices for:
- Considerations around building ethical data analyses
- Sharing data
- Creating data visualizations
:::
```{r}
#| message: false
#| echo: false
library(tidyverse)
```
# Best practices for data ethics
In philosophy departments, classes and modules centered around **data ethics** are widely discussed.
The ethical challenges around working with data are not fundamentally different from the ethical challenges philosophers have always faced.
However, putting an ethical framework around building data analyses in practice is indeed new for most data scientists, and for many of us, we are woefully under-prepared to teach so far outside our comfort zone.
That being said, we can provide some thoughts on how to approach a data science problem using a philosophical lens.
## Defining ethics
We start with a grounding in the definition of Ethics:
**Ethics**, also called moral philosophy, has three main branches:
1. [Applied ethics](https://www.oxfordbibliographies.com/view/document/obo-9780195396577/obo-9780195396577-0006.xml) "is a branch of ethics devoted to the treatment of moral problems, practices, and policies in personal life, professions, technology, and government."
2. [Ethical theory](https://academic.oup.com/edited-volume/35492/chapter-abstract/304418208?redirectedFrom=fulltext&login=false) "is concerned with the articulation and the justification of the fundamental principles that govern the issues of how we should live and what we morally ought to do. Its most general concerns are providing an account of moral evaluation and, possibly, articulating a decision procedure to guide moral action."
3. [Metaethics](https://plato.stanford.edu/entries/metaethics/) "is the attempt to understand the metaphysical, epistemological, semantic, and psychological, presuppositions and commitments of moral thought, talk, and practice."
While, unfortunately, there are myriad examples of **ethical data science problems** (see, for example, blog posts [bookclub](https://teachdatascience.com/bookclub/) and [data feminism](https://teachdatascience.com/datafem/)), here I aim to connect some of the broader data science ethics issues with the existing philosophical literature.
Note, I am only scratching the surface and a deeper dive might involve education in related philosophical fields (epistemology, metaphysics, or philosophy of science), philosophical methodologies, and ethical schools of thought, but you can peruse all of these through, for example, a course or readings introducing the discipline of philosophy.
Below we provide some thoughts on how to approach a data science problem using a philosophical lens.
## Case Study
We begin by considering a case study around ethical data analyses.
Many **ethics case studies** provided in a classroom setting **describe algorithms built on data which are meant to predict outcomes**.
::: callout-tip
### Note
Large scale algorithmic decision making presents particular ethical predicaments because of both the scale of impact and the "black-box" sense of how the algorithm is generating predictions.
:::
Consider the well-known issue of using [facial recognition software](https://en.wikipedia.org/wiki/Facial_recognition_system) in policing.
There are many questions surrounding the policing issue:
- What are the action options with respect to the outcome of the algorithm?
- What are the good and bad aspects of each action and how are these to be weighed against each other?
\[Source: [CNN](https://www.cnn.com/2019/09/12/tech/california-body-cam-facial-recognition-ban/index.html)\]
::: callout-tip
### Important questions
The two main ethical concerns surrounding facial recognition software break down into
- How the algorithms were developed?
- How the algorithm is used?
:::
When thinking about the questions below, reflect on the good aspects and the bad aspects and how one might weight the good versus the bad.
### Creating the algorithm
- What data should be used to train the algorithm?
- If the accuracy rates of the algorithm differ based on the demographics of the subgroups within the data, is more data and testing required?
- Who and what criteria should be used to tune the algorithm?
- Who should be involved in decisions on the tuning parameters of the algorithm?
- Which optimization criteria should be used (e.g., accuracy? false positive rate? false negative rate?)
- Issues of access:
- Who should own or have control of the facial image data?
- Do individuals have a right to keep their facial image private from being in databases?
- Do individuals have a right to be notified that their facial image is in the data base? For example, if I ring someone's doorbell and my face is captured in a database, do I need to be told? \[While traditional human subjects and IRB requirements necessitate consent to be included in any research project, in most cases it is legal to photograph a person without their consent.\]
- Should the data be accessible to researchers working to make the field more equitable? What if allowing accessibility thereby makes the data accessible to bad actors?
### Using the algorithm
- Issues of personal impact:
- The software might make it easier to accurately associate an individual with a crime, but it might also make it easier to mistakenly associate an individual with a crime. How should the pro vs con be weighed against each other?
- Do individuals have a right to know, correct, or delete personal information included in a database?
- Issues of societal impact:
- Is it permissible to use a facial recognition software which has been trained primarily on faces of European ancestry individual, given that this results in false positive and false negative rates that are not equally dispersed across racial lines?
- While the software might make it easier to protect against criminal activity, it also makes it easier to undermine specific communities when their members are mistakenly identified with criminal activity. How should the pro vs con of different communities be weighed against each other?
- Issues of money:
- Is it permissible for a software company to profit from an algorithm while having no financial responsibility for its misuse or negative impacts?
- Who should pay the court fees and missed work hours of those who were mistakenly accused of crimes?
To settle the questions above, we need to study various ethical theories, and it turns out that the different theories may lead us to different conclusions. As non-philosophers, we recognize that the suggested readings and ideas may come across as overwhelming. If you are overwhelmed, we suggest that you choose one ethical theory, think carefully about how it informs decision making, and help your students to connect the ethical framework to a data science case study.
## Final thoughts
This is a challenging topic, but as you analyze data, ask yourself the following broad questions to help you with ethical considerations around the data analysis.
::: callout-tip
### Questions to ask yourself when analyzing data?
1. Why are we producing this knowledge?
2. For whom are we producing this knowledge?
3. What communities do they serve?
4. Which stakeholders need to be involved in making decisions in and around the data analysis?
:::
# Best practices for sharing data
Data sharing is an essential element of the scientific method, imperative to ensure transparency and reproducibility.
Different areas of research collect fundamentally different types of data, such as tabular data, time series data, image data, or genomic data. These types of data differ greatly in size and require different approaches for sharing.
In this section, I outline broad best practices to make your data publicly accessible and usable, generally and for several specific kinds of data.
## FAIR principles
Sharing data proves more useful when others can easily find and access, interpret, and reuse the data. To maximize the benefit of sharing your data, follow the [findable, accessible, interoperable, and reusable (FAIR)](https://www.go-fair.org/fair-principles/) guiding principles of data sharing, which optimize reuse of generated data.
::: callout-tip
### FAIR data sharing principles
1. **Findable**. The first step in (re)using data is to find them. Metadata and data should be easy to find for both humans and computers. Machine-readable metadata are essential for automatic discovery of datasets and services, so this is an essential component of the FAIRification process.
2. **Accessible**. Once the user finds the required data, she/he needs to know how can they be accessed, possibly including authentication and authorization.
3. **Interoperable**. The data usually need to be integrated with other data. In addition, the data need to interoperate with applications or workflows for analysis, storage, and processing.
4. **Reusable**. The ultimate goal of FAIR is to optimize the reuse of data. To achieve this, metadata and data should be well-described so that they can be replicated and/or combined in different settings.
:::
<iframe class="speakerdeck-iframe" frameborder="0" src="https://speakerdeck.com/player/846fdf74c6ec440691521f9a42855ce4?slide=17" title="LCG20" allowfullscreen="true" style="border: 0px; background: padding-box padding-box rgba(0, 0, 0, 0.1); margin: 0px; padding: 0px; border-radius: 6px; box-shadow: rgba(0, 0, 0, 0.2) 0px 5px 40px; width: 100%; height: auto; aspect-ratio: 560 / 315;" data-ratio="1.7777777777777777"></iframe>
## Why share?
1. **Benefits of sharing data to science and society**. Sharing data allows for transparency in scientific studies and allows one to fully understand what occurred in an analysis and reproduce the results. Without complete data, metadata, and information about resources used to generate the data, reproducing a study proves impossible.
2. **Benefits of sharing data to individual researchers**. Sharing data increases the impact of a researcher's work and reputation for sound science. Awards for those with an excellent record of [data sharing](https://researchsymbionts.org/) or [data reuse](https://researchparasite.com/) can exemplify this reputation.
<iframe class="speakerdeck-iframe" frameborder="0" src="https://speakerdeck.com/player/434ae0541ae64731a95f35431acb754d?slide=18" title="HCA LA 2022" allowfullscreen="true" style="border: 0px; background: padding-box padding-box rgba(0, 0, 0, 0.1); margin: 0px; padding: 0px; border-radius: 6px; box-shadow: rgba(0, 0, 0, 0.2) 0px 5px 40px; width: 100%; height: auto; aspect-ratio: 560 / 420;" data-ratio="1.3333333333333333"></iframe>
<iframe class="speakerdeck-iframe" frameborder="0" src="https://speakerdeck.com/player/846fdf74c6ec440691521f9a42855ce4?slide=44" title="LCG20" allowfullscreen="true" style="border: 0px; background: padding-box padding-box rgba(0, 0, 0, 0.1); margin: 0px; padding: 0px; border-radius: 6px; box-shadow: rgba(0, 0, 0, 0.2) 0px 5px 40px; width: 100%; height: auto; aspect-ratio: 560 / 315;" data-ratio="1.7777777777777777"></iframe>
### Addressing common concerns about data sharing
Despite the clear benefits of sharing data, some researchers still have concerns about doing so.
- **Novelty**. Some worry that sharing data may decrease the novelty of their work and their chance to publish in prominent journals. You can address this concern by sharing your data only after publication. You can also choose to preprint your manuscript when you decide to share your data. Furthermore, you only need to share the data and metadata required to reproduce your published study.
- **Time spent on sharing data**. Some have concerns about the time it takes to organize and share data publicly. Many add 'data available upon request' to manuscripts instead of depositing the data in a public repository in hopes of getting the work out sooner. It does take time to organize data in preparation for sharing, but sharing data publicly may save you time. Sharing data in a public repository that guarantees archival persistence means that you will not have to worry about storing and backing up the data yourself.
- **Human subject data**. Sharing of data on human subjects requires special ethical, legal, and privacy considerations. Existing recommendations largely aim to balance the privacy of human participants with the benefits of data sharing by de-identifying human participants and obtaining consent for sharing. Sharing human data poses a variety of challenges for analysis, transparency, reproducibility, interoperability, and access.
::: callout-tip
### Human data
Sometimes you cannot publicly post all human data, even after de-identification. We suggest three strategies for making these data maximally accessible.
1. Deposit raw data files in a controlled-access repository. Controlled-access repositories allow only qualified researchers who apply to access the data.
* Example: the database of Genotypes and Phenotypes (dbGaP) <https://www.ncbi.nlm.nih.gov/gap/>
2. Even if you cannot make individual-level raw data available, you can make as much processed data available as possible. This may take the form of summary statistics such as means and standard deviations, rather than individual-level data.
* Example: GWAS summary data such as the one available from <https://www.ebi.ac.uk/gwas/docs/summary-statistics-format>
3. You may want to generate simulated data distinct from the original data but statistically similar to it. Simulated data would allow others to reproduce your analysis without disclosing the original data or requiring the security controls needed for controlled access.
:::
## What data to share?
Depending on the data type, you might be able to share the data itself, or a summarized version of it. Broadly thought, you want to share the following:
1. The **data** itself, or a summarized version, or a simulated data similar to the original.
2. Any **metadata** to describe the primary data and the resources used to generate it. Most disciplines have specific metadata standards to follow (e.g. [microarrays](http://fged.org/projects/minseqe/)).
3. **Data dictionary**. These have crucial role in organizing your data, especially explaining the variables and their representation. Data dictionaries should provide short names for each variable, a longer text label for the variable, a definition for each variable, data type (such as floating-point number, integer, or string), measurement units, and expected minimum and maximum values. Data dictionaries can make explicit what future users would otherwise have to guess about the representation of data.
* You have gotten used to seeing the _Tidy Tuesday_ data dictionaries <https://github.com/rfordatascience/tidytuesday> such as <https://github.com/rfordatascience/tidytuesday/blob/master/data/2023/2023-10-17/readme.md#data-dictionary>
4. **Source code**. Ideally, readers should have all materials needed to completely reproduce the study described in a publication, not just data. These materials include source code, preprocessing, and analysis scripts. Guidelines for organization of computational project can help you arrange your data and scripts in a way that will make it easier for you and other to access and reuse them.
* See <https://github.com/LieberInstitute/template_project> for how we organize code in my team.
* See also <https://docs.github.com/en/repositories/archiving-a-github-repository/referencing-and-citing-content> for how to deposit your GitHub repository on Zenodo and get a Digital Object Identifier (DOI) that others can cite. Example <https://zenodo.org/doi/10.5281/zenodo.10010510>
5. **Licensing**. Clear licensing information attached to your data avoids any questions of whether others may reuse it. Many data resources turn out not to be as reusable as the providers intended, due to lack of clarity in licensing or restrictive licensing choices.
* See <https://choosealicense.com/> for more on how to choose a license
::: callout-tip
### How should you document your data?
Document your data in three ways:
1. **With your manuscript**.
2. **With description fields** in the metadata collected by repositories
3. **With README files**. README files provide abbreviated information about a collection of files (e.g. explain organization, file locations, observations and variables present in each file, details on the experimental design, etc).
:::
# Best practices for data visualizations
## Motiviation
::: callout-tip
### Quote from one of Roger Peng's heroes
*"The greatest value of a picture is when it forces us to notice what we never expected to see."* -John W. Tukey
```{r}
#| fig-align: center
#| echo: false
#| fig-cap-location: "top"
#| fig-width: 4
knitr::include_graphics("http://upload.wikimedia.org/wikipedia/en/e/e9/John_Tukey.jpg")
```
:::
Mistakes, biases, systematic errors and unexpected variability are commonly found in data regardless of applications. Failure to discover these problems often leads to **flawed analyses and false discoveries**.
As an example, consider that measurement devices sometimes fail and not all summarization procedures, such as the `mean()` function in R, are designed to detect these. Yet, these functions will still give you an answer.
Furthermore, it may be hard or impossible to notice an error was made just from the reported summaries.
**Data visualization is a powerful approach to detecting these problems**. We refer to this particular task as exploratory data analysis (EDA), coined by John Tukey.
On a more positive note, data visualization can also lead to discoveries which would otherwise be missed if we simply subject the data to a battery of statistical summaries or procedures.
When analyzing data, we often **make use of exploratory plots to motivate the analyses** we choose.
In this section, we will discuss some types of plots to avoid, better ways to visualize data, some principles to create good plots, and ways to use `ggplot2` to create **expository** (intended to explain or describe something) graphs.
::: callout-tip
### Example
The following figure is from [Lippmann et al. 2006](https://www.ncbi.nlm.nih.gov/pmc/articles/PMC1665439/):
{width="70%"}
The following figure is from [Dominici et al. 2007](https://www.ncbi.nlm.nih.gov/pmc/articles/PMC2137127/), in response to the work by Lippmann et al. above.
{width="70%"}
Elevated levels of Ni and V PM2.5 chemical components in New York are likely attributed to oil-fired power plants and emissions from ships burning oil, as noted by Lippmann et al. (2006).
:::
### Generating data visualizations
In order to determine the effectiveness or quality of a visualization, we need to first understand three things:
::: callout-tip
### Questions to ask yourself when building data visualizations
1. What is the question we are trying to answer?
2. Why are we building this visualization?
3. For whom are we producing this data visualization for? Who is the intended audience to consume this visualization?
:::
No plot (or any statistical tool, really) can be judged without knowing the answers to those questions. No plot or graphic exists in a vacuum. There is always context and other surrounding factors that play a role in determining a plot's effectiveness.
Conversely, **high-quality, well-made visualizations** usually allow one to properly deduce what question is being asked and who the audience is meant to be. A good visualization **tells a complete story in a single frame**.
::: callout-tip
## Broad steps for creating data visualizations
The act of visualizing data typically proceeds in two broad steps:
1. Given the question and the audience, **what type of plot should I make?**
2. Given the plot I intend to make, **how can I optimize it for clarity and effectiveness?**
:::
## Data viz principles
### Developing plots
Initially, one must decide what information should be presented. The following principles for developing analytic graphics come from Edward Tufte's book [*Beautiful Evidence*](https://www.edwardtufte.com/tufte/books_be).
1. Show comparisons
2. Show causality, mechanism, explanation
3. Show multivariate data
4. Integrate multiple modes of evidence
5. Describe and document the evidence
6. Content is king - good plots start with good questions
### Optimizing plots
1. Maximize the data/ink ratio -- if "ink" can be removed without reducing the information being communicated, then it should be removed.
2. Maximize the range of perceptual conditions -- your audience's perceptual abilities may not be fully known, so it's best to allow for a wide range, to the extent possible (or knowable).
3. Show variation in the **data**, not variation in the **design**.
What's sub-optimal about this plot?
```{r}
#| warning: false
d <- airquality %>%
mutate(Summer = ifelse(Month %in% c(7, 8, 9), 2, 3))
with(d, {
plot(Temp, Ozone, col = unclass(Summer), pch = 19, frame.plot = FALSE)
legend("topleft",
col = 2:3, pch = 19, bty = "n",
legend = c("Summer", "Non-Summer")
)
})
```
What's sub-optimal about this plot?
```{r}
#| warning: false
airquality %>%
mutate(Summer = ifelse(Month %in% c(7, 8, 9),
"Summer", "Non-Summer"
)) %>%
ggplot(aes(Temp, Ozone)) +
geom_point(aes(color = Summer), size = 2) +
theme_minimal()
```
Some of these principles are taken from Edward Tufte's *Visual Display of Quantitative Information*:
## Plots to Avoid
This section is based on a talk by [Karl W. Broman](http://kbroman.org/) titled ["How to Display Data Badly"](https://www.biostat.wisc.edu/~kbroman/presentations/graphs_cmp2014.pdf), in which he described how the default plots offered by Microsoft Excel "obscure your data and annoy your readers" ([here](https://kbroman.org/talks.html) is a link to a collection of Karl Broman's talks).
::: callout-tip
### FYI
Karl's lecture was inspired by the 1984 paper by H. Wainer: How to display data badly. American Statistician 38(2): 137--147.
Dr. Wainer was the first to elucidate the principles of the bad display of data.
However, according to Karl Broman, "The now widespread use of Microsoft Excel has resulted in remarkable advances in the field."
Here we show examples of "bad plots" and how to improve them in R.
:::
::: callout-tip
### Some general principles of *bad* plots
- Display as little information as possible.
- Obscure what you do show (with chart junk).
- Use pseudo-3D and color gratuitously.
- Make a pie chart (preferably in color and 3D).
- Use a poorly chosen scale.
- Ignore significant figures.
:::
## Examples
Here are some examples of bad plots and suggestions on how to improve
### Pie charts
Let's say we are interested in the most commonly used browsers. Wikipedia has a [table](https://en.wikipedia.org/wiki/Usage_share_of_web_browsers) with the "usage share of web browsers" or the proportion of visitors to a group of web sites that use a particular web browser from July 2017.
```{r}
browsers <- c(
Chrome = 60, Safari = 14, UCBrowser = 7,
Firefox = 5, Opera = 3, IE = 3, Noinfo = 8
)
browsers.df <- gather(
data.frame(t(browsers)),
"browser", "proportion"
)
```
Let's say we want to report the results of the usage. The standard way of displaying these is with a pie chart:
```{r}
pie(browsers, main = "Browser Usage (July 2022)")
```
If we look at the help file for `pie()`:
```{r}
#| eval: false
?pie
```
It states:
> "Pie charts are a very bad way of displaying information. The eye is good at judging linear measures and bad at judging relative areas. A bar chart or dot chart is a preferable way of displaying this type of data."
To see this, look at the figure above and try to determine the percentages just from looking at the plot. Unless the percentages are close to 25%, 50% or 75%, this is not so easy. Simply showing the numbers is not only clear, but also saves on printing costs.
Having said that, see how we used a pie chart in a [recent pre-print](https://doi.org/10.1101/2023.02.15.528722) <https://www.biorxiv.org/content/biorxiv/early/2023/02/15/2023.02.15.528722/F5.large.jpg>.
#### Instead of pie charts, try bar plots
If you do want to plot them, then a barplot is appropriate. Here we use the `geom_bar()` function in `ggplot2`. Note, there are also horizontal lines at every multiple of 10, which helps the eye quickly make comparisons across:
```{r}
p <- browsers.df %>%
ggplot(aes(
x = reorder(browser, -proportion),
y = proportion
)) +
geom_bar(stat = "identity")
p
```
Notice that we can now pretty easily determine the percentages by following a horizontal line to the x-axis.
#### Polish your plots
While this figure is already a big improvement over a pie chart, we can do even better. When you create figures, you want your figures to be self-sufficient, meaning someone looking at the plot can understand everything about it.
Some possible critiques are:
1. make the axes bigger
2. make the labels bigger
3. make the labels be full names (e.g. "Browser" and "Proportion of users", ideally with units when appropriate)
4. add a title
Let's explore how to do these things to make an even better figure.
To start, go to the help file for `theme()`
```{r}
#| eval: false
?ggplot2::theme
```
We see there are arguments with text that control all the text sizes in the plot. If you scroll down, you see the text argument in the theme command requires class `element_text`. Let's try it out.
To change the x-axis and y-axis labels to be full names, use `xlab()` and `ylab()`
```{r}
p <- p + xlab("Browser") +
ylab("Proportion of Users")
p
```
Maybe a title
```{r}
p + ggtitle("Browser Usage (July 2022)")
```
Next, we can also use the `theme()` function in `ggplot2` to control the justifications and sizes of the axes, labels and titles.
To center the title
```{r}
p + ggtitle("Browser Usage (July 2022)") +
theme(plot.title = element_text(hjust = 0.5))
```
To create bigger text/labels/titles:
```{r}
p <- p + ggtitle("Browser Usage (July 2022)") +
theme(
plot.title = element_text(hjust = 0.5),
text = element_text(size = 15)
)
p
```
#### "I don't like that theme"
```{r}
p + theme_bw()
```
```{r}
p + theme_dark()
```
```{r}
p + theme_classic() # axis lines!
```
```{r}
p + ggthemes::theme_base()
```
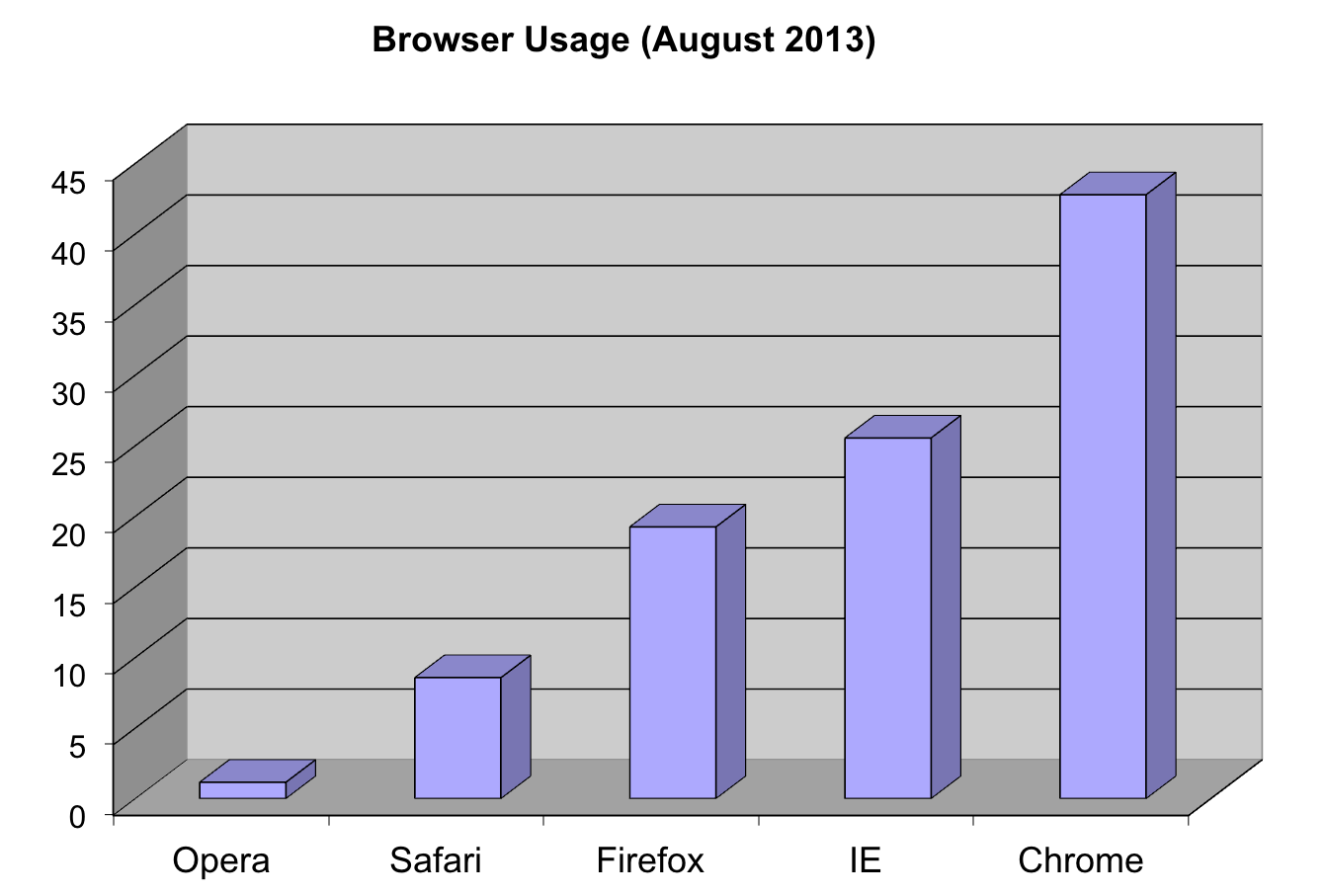
### 3D barplots
Please, avoid a 3D version because it obfuscates the plot, making it more difficult to find the percentages by eye.
### Donut plots
Even worse than pie charts are donut plots.

The reason is that by removing the center, we remove one of the visual cues for determining the different areas: the angles. **There is no reason to ever use a donut plot to display data**.
::: callout-note
### Question
Why are pie/donut charts [so common](https://blog.usejournal.com/why-humans-love-pie-charts-9cd346000bdc)?
<https://blog.usejournal.com/why-humans-love-pie-charts-9cd346000bdc>
:::
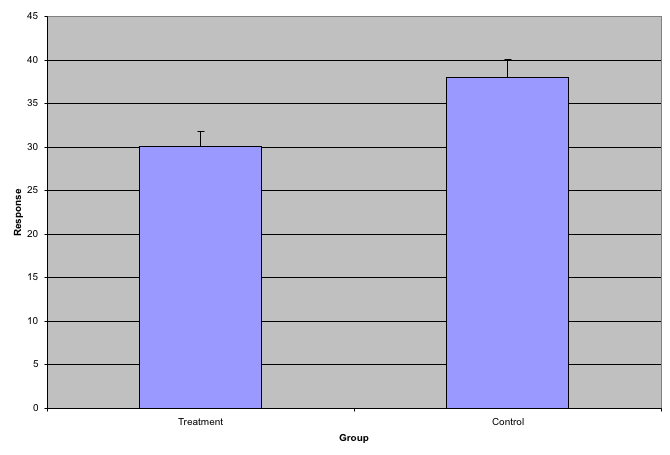
### Barplots as data summaries
While barplots are useful for showing percentages, they are incorrectly used to display data from two groups being compared. Specifically, barplots are created with height equal to the group means; an antenna is added at the top to represent standard errors. This plot is simply showing two numbers per group and the plot adds nothing:
#### Instead of bar plots for summaries, try box plots
If the number of points is small enough, we might as well add them to the plot. When the number of points is too large for us to see them, just showing a boxplot is preferable.
Let's recreate these barplots as boxplots and overlay the points. We will simulate similar data to demonstrate one way to improve the graphic above.
```{r}
set.seed(1000)
dat <- data.frame(
"Treatment" = rnorm(10, 30, sd = 4),
"Control" = rnorm(10, 36, sd = 4)
)
gather(dat, "type", "response") %>%
ggplot(aes(type, response)) +
geom_boxplot() +
geom_point(position = "jitter") +
ggtitle("Response to drug treatment")
```
Notice how much more we see here: the center, spread, range, and the points themselves. In the barplot, we only see the mean and the standard error (SE), and the SE has more to do with sample size than with the spread of the data.
This problem is magnified when our data has outliers or very large tails. For example, in the plot below, there appears to be very large and consistent differences between the two groups:
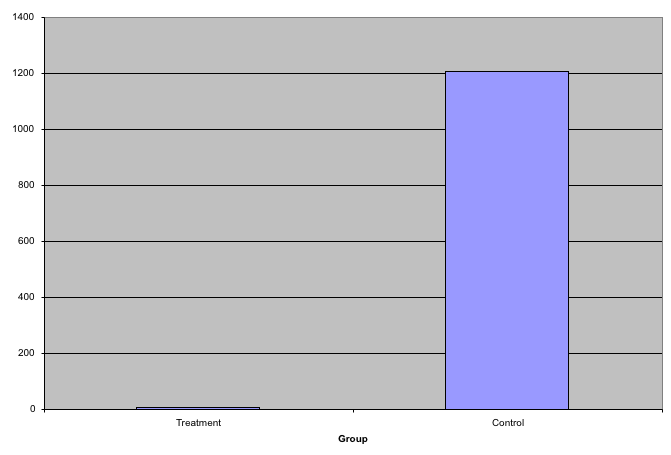
However, a quick look at the data demonstrates that this difference is mostly driven by just two points.
```{r}
set.seed(1000)
dat <- data.frame(
"Treatment" = rgamma(10, 10, 1),
"Control" = rgamma(10, 1, .01)
)
gather(dat, "type", "response") %>%
ggplot(aes(type, response)) +
geom_boxplot() +
geom_point(position = "jitter")
```
#### Use log scale if data includes outliers
A version showing the data in the log-scale is much more informative.
```{r}
gather(dat, "type", "response") %>%
ggplot(aes(type, response)) +
geom_boxplot() +
geom_point(position = "jitter") +
scale_y_log10()
```
### Barplots for paired data
A common task in data analysis is the comparison of two groups. When the dataset is small and data are paired, such as the outcomes before and after a treatment, two-color barplots are unfortunately often used to display the results.
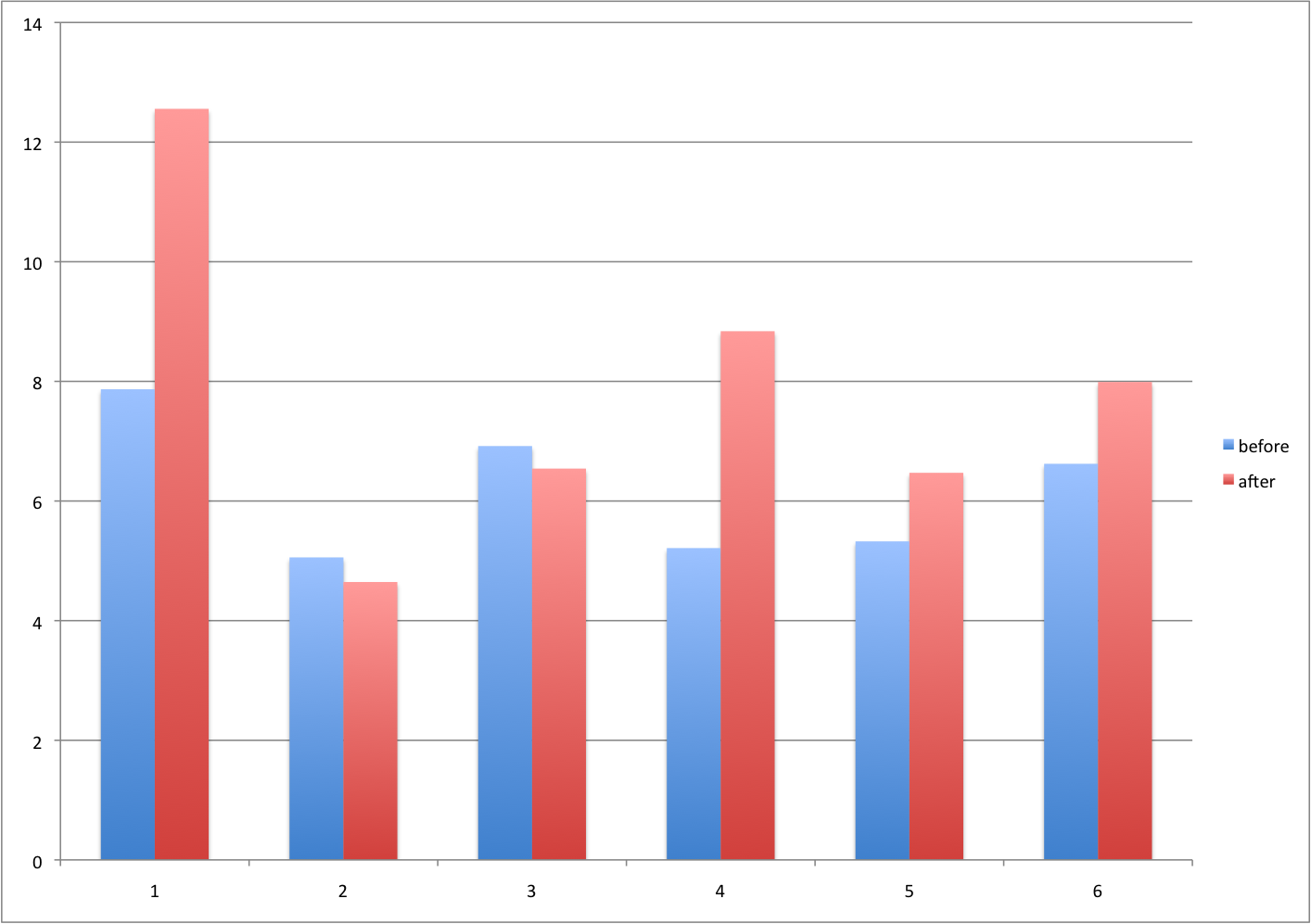
#### Instead of paired bar plots, try scatter plots
There are better ways of showing these data to illustrate that there is an increase after treatment. One is to simply make a scatter plot, which shows that most points are above the identity line. Another alternative is to plot the differences against the before values.
```{r}
set.seed(1000)
before <- runif(6, 5, 8)
after <- rnorm(6, before * 1.15, 2)
li <- range(c(before, after))
ymx <- max(abs(after - before))
par(mfrow = c(1, 2))
plot(before, after,
xlab = "Before", ylab = "After",
ylim = li, xlim = li
)
abline(0, 1, lty = 2, col = 1)
plot(before, after - before,
xlab = "Before", ylim = c(-ymx, ymx),
ylab = "Change (After - Before)", lwd = 2
)
abline(h = 0, lty = 2, col = 1)
```
#### or line plots
Line plots are not a bad choice, although they can be harder to follow than the previous two. Boxplots show you the increase, but lose the paired information.
```{r}
z <- rep(c(0, 1), rep(6, 2))
par(mfrow = c(1, 2))
plot(z, c(before, after),
xaxt = "n", ylab = "Response",
xlab = "", xlim = c(-0.5, 1.5)
)
axis(side = 1, at = c(0, 1), c("Before", "After"))
segments(rep(0, 6), before, rep(1, 6), after, col = 1)
boxplot(before, after,
names = c("Before", "After"),
ylab = "Response"
)
```
<iframe class="speakerdeck-iframe" frameborder="0" src="https://speakerdeck.com/player/2c3377401c934bb9abd859b644bb9455?slide=17" title="2023-10-03-FOGBoston" allowfullscreen="true" style="border: 0px; background: padding-box padding-box rgba(0, 0, 0, 0.1); margin: 0px; padding: 0px; border-radius: 6px; box-shadow: rgba(0, 0, 0, 0.2) 0px 5px 40px; width: 100%; height: auto; aspect-ratio: 560 / 315;" data-ratio="1.7777777777777777"></iframe>
The above plot was made using [`ggpubr::ggpaired()`](https://rpkgs.datanovia.com/ggpubr/reference/ggpaired.html). Note that the title of the package is:
> ggpubr: ‘ggplot2’ Based Publication Ready Plots
### Gratuitous 3D
The figure below shows three curves. Pseudo 3D is used, but it is not clear why. Maybe to separate the three curves? Notice how difficult it is to determine the values of the curves at any given point:
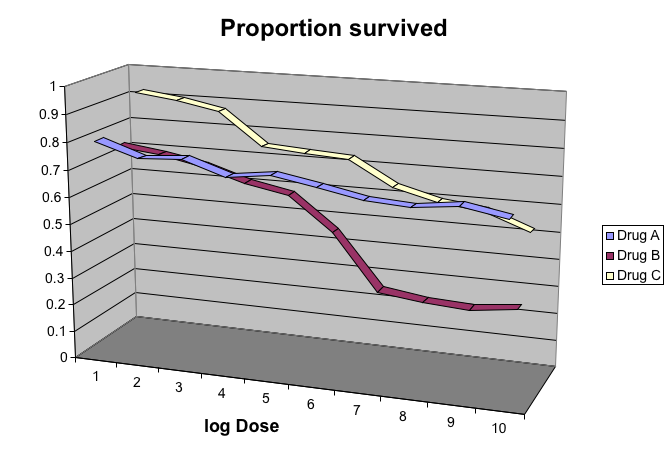
This plot can be made better by simply using color to distinguish the three lines:
```{r,message=FALSE}
x <- read_csv("https://github.com/kbroman/Talk_Graphs/raw/master/R/fig8dat.csv") %>%
as_tibble(.name_repair = make.names)
p <- x %>%
gather("drug", "proportion", -log.dose) %>%
ggplot(aes(
x = log.dose, y = proportion,
color = drug
)) +
geom_line()
p
```
This plot demonstrates that using color is more than enough to distinguish the three lines.
We can make this plot better using the functions we learned above
```{r}
p + ggtitle("Survival proportion") +
theme(
plot.title = element_text(hjust = 0.5),
text = element_text(size = 15)
)
```
#### Legends
We can also move the legend inside the plot
```{r}
p + ggtitle("Survival proportion") +
theme(
plot.title = element_text(hjust = 0.5),
text = element_text(size = 15),
legend.position = c(0.2, 0.3)
)
```
We can also make the legend transparent
```{r}
transparent_legend <- theme(
legend.background = element_rect(fill = "transparent"),
legend.key = element_rect(
fill = "transparent",
color = "transparent"
)
)
p + ggtitle("Survival proportion") +
theme(
plot.title = element_text(hjust = 0.5),
text = element_text(size = 15),
legend.position = c(0.2, 0.3)
) +
transparent_legend
```
### Too many significant digits
By default, statistical software like R returns many significant digits. This does not mean we should report them. Cutting and pasting directly from R is a bad idea since you might end up showing a table, such as the one below, comparing the heights of basketball players:
```{r}
heights <- cbind(
rnorm(8, 73, 3), rnorm(8, 73, 3), rnorm(8, 80, 3),
rnorm(8, 78, 3), rnorm(8, 78, 3)
)
colnames(heights) <- c("SG", "PG", "C", "PF", "SF")
rownames(heights) <- paste("team", 1:8)
heights
```
We are reporting precision up to 0.00001 inches. Do you know of a tape measure with that much precision? This can be easily remedied:
```{r}
round(heights, 1)
```
### Minimal figure captions
Recall the plot we had before:
```{r, fig.cap=""}
transparent_legend <- theme(
legend.background = element_rect(fill = "transparent"),
legend.key = element_rect(
fill = "transparent",
color = "transparent"
)
)
p + ggtitle("Survival proportion") +
theme(
plot.title = element_text(hjust = 0.5),
text = element_text(size = 15),
legend.position = c(0.2, 0.3)
) +
xlab("dose (mg)") +
transparent_legend
```
What type of caption would be good here?
When creating figure captions, think about the following:
1. Be specific
> A plot of the proportion of patients who survived after three drug treatments.
2. Label the caption
> Figure 1. A plot of the proportion of patients who survived after three drug treatments.
3. Tell a story
> Figure 1. Drug treatment survival. A plot of the proportion of patients who survived after three drug treatments.
4. Include units
> Figure 1. Drug treatment survival. A plot of the proportion of patients who survived after three drug treatments (milligram).
5. Explain aesthetics
> Figure 1. Drug treatment survival. A plot of the proportion of patients who survived after three drug treatments (milligram). Three colors represent three drug treatments. Drug A results in largest survival proportion for the larger drug doses.
## Final thoughts data viz
In general, you should follow these principles:
- Create expository graphs to tell a story (figure and caption should be self-sufficient; it's the first thing people look at)
- Be accurate and clear
- Let the data speak
- Make axes, labels and titles big
- Make labels full names (ideally with units when appropriate)
- Add informative legends; use space effectively
- Show as much information as possible, taking care not to obscure the message
- Science not sales: avoid unnecessary frills (especially gratuitous 3D)
- In tables, every digit should be meaningful
### Some further reading
- N Cross (2011). Design Thinking: Understanding How Designers Think and Work. Bloomsbury Publishing.
- J Tukey (1977). Exploratory Data Analysis.
- ER Tufte (1983) The visual display of quantitative information. Graphics Press.
- ER Tufte (1990) Envisioning information. Graphics Press.
- ER Tufte (1997) Visual explanations. Graphics Press.
- ER Tufte (2006) Beautiful Evidence. Graphics Press.
- WS Cleveland (1993) Visualizing data. Hobart Press.
- WS Cleveland (1994) The elements of graphing data. CRC Press.
- A Gelman, C Pasarica, R Dodhia (2002) Let's practice what we preach: Turning tables into graphs. The American Statistician 56:121-130.
- NB Robbins (2004) Creating more effective graphs. Wiley.
- [Nature Methods columns](http://bang.clearscience.info/?p=546)
# R session information
```{r}
options(width = 120)
sessioninfo::session_info()
```