Chungpa Lee, Joonhwan Chang, Jy-yong Sohn
Proceedings of the 27th International Conference on Artificial Intelligence and Statistics (AISTATS) 2024, Valencia, Spain. PMLR: Volume 238.
Contrastive learning has emerged as a prominent branch of self-supervised learning for several years. Especially, CLIP, which applies contrastive learning to large sets of captioned images, has garnered significant attention. Recently, SigLIP, a variant of CLIP, has been proposed, which uses the sigmoid loss instead of the standard InfoNCE loss. SigLIP achieves the performance comparable to CLIP in a more efficient manner by eliminating the need for a global view. However, theoretical understanding of using the sigmoid loss in contrastive learning is underexplored. In this paper, we provide a theoretical analysis of using the sigmoid loss in contrastive learning, in the perspective of the geometric structure of learned embeddings. First, we propose the double-Constant Embedding Model (CCEM), a framework for parameterizing various well-known embedding structures by a single variable. Interestingly, the proposed CCEM is proven to contain the optimal embedding with respect to the sigmoid loss. Second, we mathematically analyze the optimal embedding minimizing the sigmoid loss for contrastive learning. The optimal embedding ranges from simplex equiangular-tight-frame to antipodal structure, depending on the temperature parameter used in the sigmoid loss. Third, our experimental results on synthetic datasets coincide with the theoretical results on the optimal embedding structures.
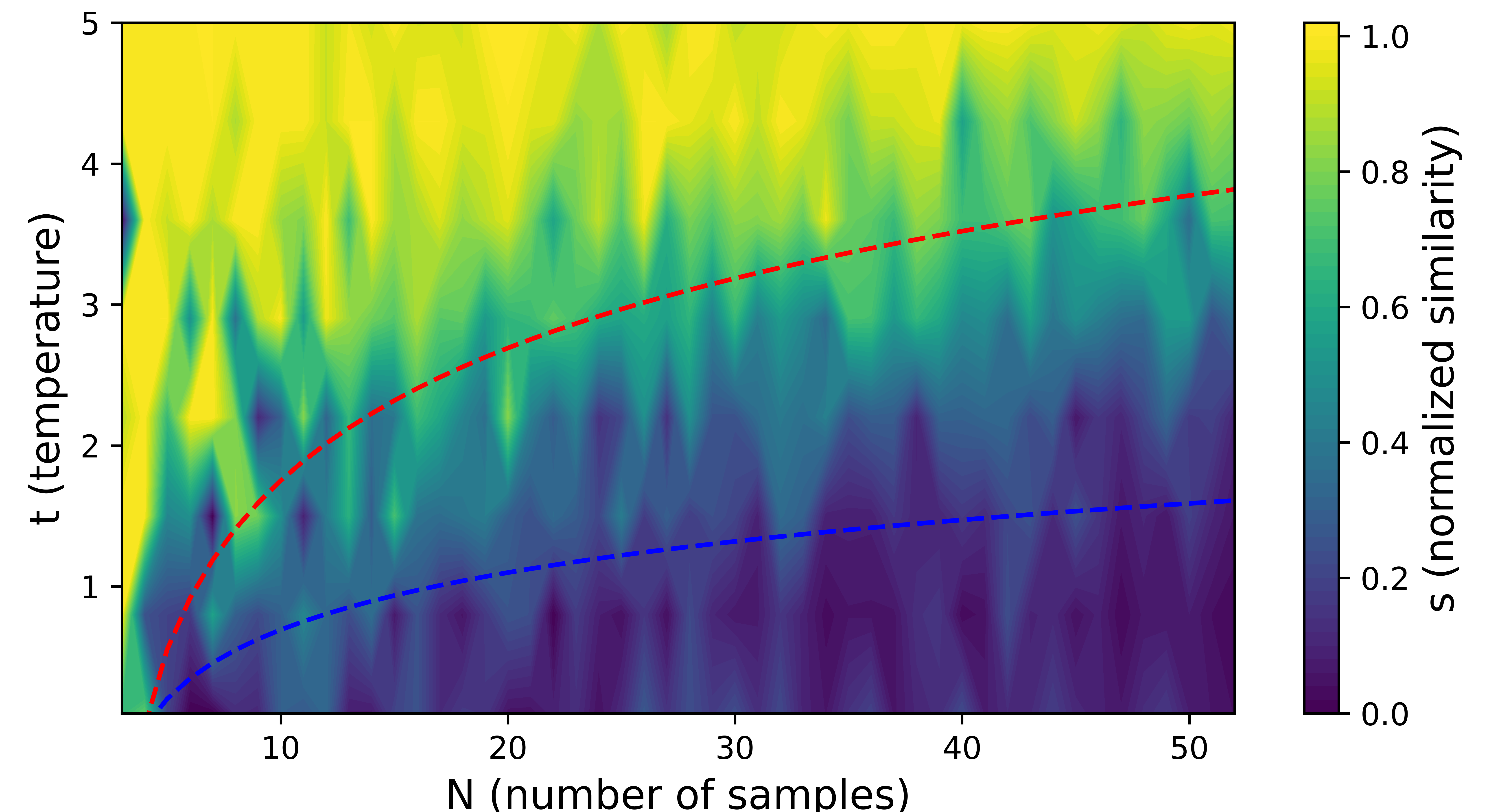
The normalized similarity
The code example is available in the Jupyter Notebook.