This auxiliary repository contains details on the experiments detailed in the paper Benchmark Evaluation of Counterfactual Algorithms for XAI: From a White Box to a Black Box . For more information on this study, please read the article.
In recent years, counterfactual algorithms have been proposed extensively in the explainable artificial intelligence (XAi) research domain. However, the standardised protocols for evaluating the quality of a counterfactual algorithm are still in their early stage. To fill the research gap, We proposed a benchmark evaluation matrix that assesses the proximity, interpretability and functionality of counterfactual algorithms.
To investigate the impact of a counterfactual generation between the different machine learning models. We select the instance centric counterfactual that we define in the paper "Counterfactuals and causability in explainable artificial intelligence: Theory, algorithms, and applications" and apply the algorithms to decision tee, random forest and neural network for analysis. We also suggested a visualization (tree-based) model for deciphering how each algorithm takes a decision path in both input and a counterfactual generation.

Caption: Experiment flow chart
The key findings of this work are: (1) without guaranteeing plausibility in the counterfactual generation process, one cannot have meaningful evaluation results. This means that all explainable counterfactual algorithms that do not take into consideration plausibility in their internal mechanisms cannot be evaluated with the current state of the art evaluation metrics; (2) the counterfactuals generated are not impacted by the different types of machine learning models; (3) DiCE was the only tested algorithm that was able to generate actionable and plausible counterfactuals, because it provides mechanisms to constraint features; (4) WatcherCF and UnjustifiedCF are limited to continuous variables and can not deal with categorical data.
 Caption: An example of a decision path in the input and its counterfactual
Caption: An example of a decision path in the input and its counterfactual
Note: The experiment utilises five public datasets from the UCI repository (https://archive.ics.uci.edu/ml/index.php).
===
root
|-- DiCE
|-- alibi-watcher-counterfactual
|-- alibi-counterfactual-prototype
|-- lore
|-- face
|-- truth
|-- datasets
|-- models
|-- utils // storing all common utilities
dice_test.ipynb
alibi_watcher_cf_test.ipynb
alibi_cf_proto_test.ipynb
lore_test.ipynb
face_test.ipynb
truth_test.ipynb
Paper link: Benchmark Evaluation of Counterfactual Algorithms for XAI: From a White Box to a Black Box (https://arxiv.org/abs/2203.02399)
the official tutorial only show the instruction for Ubuntu 18.04. However, that one doesn't work on Ubuntu 20.04.
Solution was sudo apt-get install cuda, which install and set up all the dependencies for me.
Short answer: NO
To explain the reason, I have to:
- Review LIME and LINDA
- What's LORE?
- Why LORE can be used for generating counterfactuals?
- The risk of the counterfactuals from LORE
- What does the
evaluate_counterfactualsdo? - Why we can't use
evaluate_counterfactualsfor others? - Futherwork
LIME and LINDA are simalar in terms of exaplaining strategy. They first randomly sample data points around the query instance. And use the output from the black box as the label to training an interpretable model. LIME uses decision tree or other linear models. And, LINDA use bayesian network for explaining. Basically these two XAI algorithms consist of three phases:
- Permutation.
- Using blackbox to predict permutations.
- The predictions of permutations will be used as label to train an interpretable model.
LORE has the same concept as LIME and LINDA. The only difference is the permutation strategy. Instead randomly sample around the query instance, LORE use genetic algorithm to generate permutations by maximising these two fitness functinos:

| LIME | LINDA | LORE | |
|---|---|---|---|
| Permutation | Random | Random | Genetic Alg |
| Interpretable Model | Decision Tree/ Linear Models | Bayesian Network | Decision Tree |
The rules can be extracted from the decision tree. LORE using decision tree as their interpretable model. Therefore, rules and counterfactuals can be found by exploring the local interpretable model.
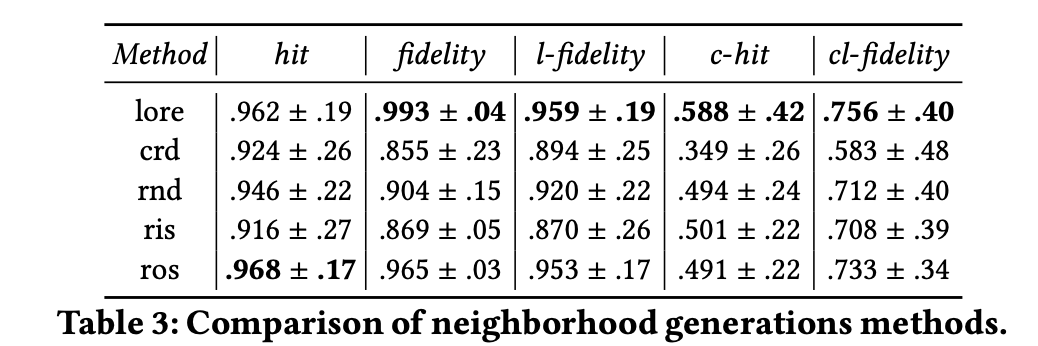
The interpretable model and the black box are not the same model. Therefore, they may have different output value from the same input instance. In other words, the counterfactual found on the interpretable model (Decision tree) has a chance to be a fake counterfactual on the black box. And, the result in the paper shows that only 58.8% counterfactuals found by decision tree are real counterfactual in the black box (c-hit in the table). Let me give an example to explain why it's a problem. If a loan application system tells the client that his applications with amount=50000 has been rejectet. In order to pass this system, LORE (White box) tell the client that his requesting amount has to be lower than 48000. However, 48000 is the condition on the white box not the real counterfactuals on the system (black box). The real counterfactuals is actually 47500. Therefore, if this client request another loan with 48000, he still has the chance to get rejected. When the systme only has 58.8% to get it right, it will not be a trustworthy system.

This function is used for checking if the counterfactual found on the interpretable model is a real counterfactual on the black box.
This function is mainly used for evaluating the interpretable model by analysing the counterfactuals (Not evaluating the counterfactual itself.). If the interpretable model is a good representation of the black box in local, the counterfauctal found in interpretable model (decision tree) should be a counterfactual in black box too.
Therefore, this function is not used for evaluating the generated counterfactuals (The function name is confusing).
What if we apply generic algorithm as the permutation strategy for LINDA? Would it improve LINDA?
The original GA implemented in LORE accept rounded output {0, 1} from model. However, this behaviour make GA hard to optimise for better result. I change the target similarity function to:
## Equal case
# From
target_similarity = 1.0 if y0 == y1 else 0.0
# To
target_similarity = -abs(y1-np.round(y0))
## Not equal case
# From
target_similarity = 1.0 if y0 != y1 else 0.0
# To
target_similarity = abs(y1 - np.round(y0))Input query prediction:

The results before (LORE implemented GA)

You can see the prediction of the generated permutations data are severely unbalanced.
After (Our GA):

Note: The 546 cases in here are actual counterfactuals.
After the change, it can get a balanced permutation dataset.