-
Notifications
You must be signed in to change notification settings - Fork 45
/
index.qmd
1184 lines (888 loc) · 41.3 KB
/
index.qmd
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
490
491
492
493
494
495
496
497
498
499
500
501
502
503
504
505
506
507
508
509
510
511
512
513
514
515
516
517
518
519
520
521
522
523
524
525
526
527
528
529
530
531
532
533
534
535
536
537
538
539
540
541
542
543
544
545
546
547
548
549
550
551
552
553
554
555
556
557
558
559
560
561
562
563
564
565
566
567
568
569
570
571
572
573
574
575
576
577
578
579
580
581
582
583
584
585
586
587
588
589
590
591
592
593
594
595
596
597
598
599
600
601
602
603
604
605
606
607
608
609
610
611
612
613
614
615
616
617
618
619
620
621
622
623
624
625
626
627
628
629
630
631
632
633
634
635
636
637
638
639
640
641
642
643
644
645
646
647
648
649
650
651
652
653
654
655
656
657
658
659
660
661
662
663
664
665
666
667
668
669
670
671
672
673
674
675
676
677
678
679
680
681
682
683
684
685
686
687
688
689
690
691
692
693
694
695
696
697
698
699
700
701
702
703
704
705
706
707
708
709
710
711
712
713
714
715
716
717
718
719
720
721
722
723
724
725
726
727
728
729
730
731
732
733
734
735
736
737
738
739
740
741
742
743
744
745
746
747
748
749
750
751
752
753
754
755
756
757
758
759
760
761
762
763
764
765
766
767
768
769
770
771
772
773
774
775
776
777
778
779
780
781
782
783
784
785
786
787
788
789
790
791
792
793
794
795
796
797
798
799
800
801
802
803
804
805
806
807
808
809
810
811
812
813
814
815
816
817
818
819
820
821
822
823
824
825
826
827
828
829
830
831
832
833
834
835
836
837
838
839
840
841
842
843
844
845
846
847
848
849
850
851
852
853
854
855
856
857
858
859
860
861
862
863
864
865
866
867
868
869
870
871
872
873
874
875
876
877
878
879
880
881
882
883
884
885
886
887
888
889
890
891
892
893
894
895
896
897
898
899
900
901
902
903
904
905
906
907
908
909
910
911
912
913
914
915
916
917
918
919
920
921
922
923
924
925
926
927
928
929
930
931
932
933
934
935
936
937
938
939
940
941
942
943
944
945
946
947
948
949
950
951
952
953
954
955
956
957
958
959
960
961
962
963
964
965
966
967
968
969
970
971
972
973
974
975
976
977
978
979
980
981
982
983
984
985
986
987
988
989
990
991
992
993
994
995
996
997
998
999
1000
---
title: "Introduction à pandas"
date: 2020-07-28T13:00:00Z
draft: false
weight: 20
tags:
- pandas
- Pollution
- Ademe
- Tutoriel
- Manipulation
categories:
- Tutoriel
- Manipulation
slug: pandas
type: book
summary: |
`pandas` est l'élément central de l'écosystème `Python` pour la _data-science_.
Le succès récent de `Python` dans l'analyse de données tient beaucoup à `pandas` qui a permis d'importer la
logique `SQL` dans le langage `Python`. `pandas` embarque énormément de
fonctionalités qui permettent d'avoir des _pipelines_ efficaces pour
traiter des données de volumétrie moyenne (jusqu'à quelques Gigas). Au-delà
de cette volumétrie, il faudra se tourner vers d'autres solutions
(`PostgresQL`, `Dask`, `Spark`...).
bibliography: ../../../../reference.bib
---
Pour essayer les exemples présents dans ce tutoriel :
::: {.cell .markdown}
```{python}
#| echo: false
#| output: asis
#| include: true
#| eval: true
import sys
sys.path.insert(1, '../../../../') #insert the utils module
from utils import print_badges
#print_badges(__file__)
print_badges("content/course/manipulation/02a_pandas_tutorial.qmd")
```
:::
Le _package_ `pandas` est l'une des briques centrales de l'écosystème de
la data-science. Son créateur, Wes McKinney, l'a pensé comme
une surcouche à la librairie `numpy` pour introduire
dans `Python` un objet central dans des langages comme `R`
ou `Stata`, à savoir le _dataframe_. `pandas` est rapidement
devenu un incontournable de la _data-science_. L'ouvrage
de référence de @mckinney2012python présente de manière plus
ample ce _package_. Ce tutoriel vise à introduire aux concepts
de base de ce package par l'exemple et à introduire à certaines
des tâches les plus fréquentes de (re)structuration
des données du _data-scientist_. Il ne s'agit pas d'un ensemble
exhaustif de commandes: `pandas` est un package tentaculaire
qui permet de réaliser la même opération de nombreuses manières.
Nous nous concentrerons ainsi sur les éléments les plus pertinents
dans le cadre d'une introduction à la _data-science_ et laisserons
les utilisateurs intéressés approfondir leurs connaissances
dans les ressources foisonnantes qu'il existe sur le sujet.
Dans ce tutoriel `pandas`, nous allons utiliser:
* Les émissions de gaz à effet de serre estimées au niveau communal par l'ADEME. Le jeu de données est
disponible sur [data.gouv](https://www.data.gouv.fr/fr/datasets/inventaire-de-gaz-a-effet-de-serre-territorialise/#_)
et requêtable directement dans `Python` avec
[cet url](https://koumoul.com/s/data-fair/api/v1/datasets/igt-pouvoir-de-rechauffement-global/convert)
Le [chapitre suivant](#pandasTP) permettra de mettre en application des éléments présents dans ce chapitre avec
les données ci-dessus associées à des données de contexte au niveau communal[^1].
::: {.cell .markdown}
[^1]: Idéalement, on utiliserait les données
[disponibles sur le site de l'Insee](https://www.insee.fr/fr/statistiques/3560121) mais celles-ci nécessitent un peu de travail
de nettoyage qui n'entre pas dans le cadre de ce TP.
Pour faciliter l'import de données Insee, il est recommandé d'utiliser le package
[`pynsee`](https://github.com/InseeFrLab/Py-Insee-Data) qui simplifie l'accès aux données
de l'Insee disponibles sur le site web [insee.fr](https://www.insee.fr/fr/accueil)
ou via des API.
:::
{{% box status="note" title="Note" icon="fa fa-comment" %}}
Le package `pynsee` est relativement jeune et n'est disponible que sur
[Github](https://github.com/InseeFrLab/Py-Insee-Data), pas sur `PyPi`.
Idéalement, on utilise la commande suivante, en ligne de commande, pour l'installer:
~~~shell
pip install git+https://github.com/InseeFrLab/Py-Insee-Data.git
~~~
Cependant, cela implique que `Jupyter` et `Git` sont capables de communiquer. Si
`Jupyter` ne sait pas où trouver `Git`, il est possible de rencontrer une erreur.
Dans ce cas, il faut télécharger le package compressé et l'installer localement :
```{python}
#| eval: false
import requests
url = 'https://github.com/InseeFrLab/Py-Insee-Data/archive/refs/heads/master.zip'
r = requests.get(url)
with open("pynsee.zip" , 'wb') as zipfile:
zipfile.write(r.content)
```
L'installation se fait de la manière suivante:
```python
!pip install --ignore-installed pynsee.zip
!pip install python-Levenshtein
```
Si le fait de ne pas avoir de barre de progrès lors du téléchargement
vous trouble, vous pouvez vous rendre à la
[Section Annexe](#annexe) pour découvrir un bout de code
qui effectue les mêmes tâches mais avec des barres de progrès
{{% /box %}}
:warning: `pandas` offre la possibilité d'importer des données
directement depuis un url. C'est l'option prise dans ce tutoriel.
Si vous préfèrez, pour des
raisons d'accès au réseau ou de performance, importer depuis un poste local,
vous pouvez télécharger les données et changer
les commandes d'import avec le chemin adéquat plutôt que l'url.
Nous suivrons les conventions habituelles dans l'import des packages
```{python import pkg}
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import pynsee.download
```
Pour obtenir des résultats reproductibles, on peut fixer la racine du générateur
pseudo-aléatoire.
```{python seed, show = FALSE}
np.random.seed(123)
```
Au cours de cette démonstration des principales fonctionalités de `pandas`, et
lors du TP
::: {.cell .markdown}
```{python}
#| echo: false
#| output: 'asis'
#| include: true
#| eval: true
import sys
sys.path.insert(1, '../../../../') #insert the utils module
from utils import print_badges
#print_badges(__file__)
print_badges("content/course/manipulation/02b_pandas_TP.qmd")
```
:::
Je recommande de se référer régulièrement aux ressources suivantes:
* L'[aide officielle de pandas](https://pandas.pydata.org/docs/user_guide/index.html).
Notamment, la
[page de comparaison des langages](https://pandas.pydata.org/pandas-docs/stable/getting_started/comparison/index.html)
est très utile
* La cheatsheet suivante, [issue de ce post](https://becominghuman.ai/cheat-sheets-for-ai-neural-networks-machine-learning-deep-learning-big-data-678c51b4b463)

# Logique de pandas
L'objet central dans la logique `pandas` est le `DataFrame`.
Il s'agit d'une structure particulière de données
à deux dimensions, structurées en alignant des lignes et colonnes. Les colonnes
peuvent être de type différent.
Un DataFrame est composé des éléments suivants:
* l'indice de la ligne ;
* le nom de la colonne ;
* la valeur de la donnée ;
Structuration d'un DataFrame pandas, emprunté à <https://medium.com/epfl-extension-school/selecting-data-from-a-pandas-dataframe-53917dc39953>:
```{python}
#| include: false
import shutil
import requests
url = 'https://miro.medium.com/max/700/1*6p6nF4_5XpHgcrYRrLYVAw.png'
response = requests.get(url, stream=True)
with open('featured.png', 'wb') as out_file:
shutil.copyfileobj(response.raw, out_file)
```

Le concept de *tidy* data, popularisé par Hadley Wickham via ses packages `R`,
est parfaitement pertinent pour décrire la structure d'un DataFrame pandas.
Les trois règles sont les suivantes:
* Chaque variable possède sa propre colonne
* Chaque observation possède sa propre ligne
* Une valeur, matérialisant la valeur d'une observation d'une variable,
se trouve sur une unique cellule.

:warning: Les DataFrames sont assez rapides en Python[^2] et permettent de traiter en local de manière efficace des tables de
données comportant plusieurs millions d'observations (en fonction de la configuration de l'ordinateur)
et dont la volumétrie peut être conséquente (plusieurs centaines
de Mo). Néanmoins, passé un certain seuil, qui dépend de la puissance de la machine mais aussi de la complexité
de l'opération effectuée, le DataFrame `pandas` peut montrer certaines limites. Dans ce cas, il existe différentes
solutions: `dask` (dataframe aux opérations parallélisés), `SQL` (notamment postgres), `spark` (solution big data)
::: {.cell .markdown}
[^2]: En `R`, les deux formes de dataframes qui se sont imposées récemment sont les `tibbles` (package `dplyr`)
et les `data.tables` (package `data.table`). `dplyr` reprend la syntaxe SQL de manière relativement
transparente ce qui rend la syntaxe très proche de celle de `pandas`. Cependant,
alors que `dplyr` supporte très mal les données dont la volumétrie dépasse 1Go, `pandas` s'en
accomode bien. Les performances de `pandas` sont plus proches de celles de `data.table`, qui est
connu pour être une approche efficace avec des données de taille importante.
:::
Concernant la syntaxe, une partie des commandes python est inspirée par la logique SQL. On retrouvera ainsi
des instructions relativement transparentes.
Il est vivement recommandé, avant de se lancer dans l'écriture d'une
fonction, de se poser la question de son implémentation native dans `numpy`, `pandas`, etc.
En particulier, la plupart du temps, s'il existe une solution implémentée dans une librairie, il convient
de l'utiliser.
# Les Series
En fait, un DataFrame est une collection d'objets appelés `pandas.Series`.
Ces `Series` sont des objets d'une dimension qui sont des extensions des
array-unidimensionnels `numpy`. En particulier, pour faciliter le traitement
de données catégorielles ou temporelles, des types de variables
supplémentaires sont disponibles dans `pandas` par rapport à
`numpy` (`categorical`, `datetime64` et `timedelta64`). Ces
types sont associés à des méthodes optimisées pour faciliter le traitement
de ces données.
Il ne faut pas négliger l'attribut `dtype` d'un objet
`pandas.Series` car cela a une influence déterminante sur les méthodes
et fonctions pouvant être utilisées (on ne fait pas les mêmes opérations
sur une donnée temporelle et une donnée catégorielle) et le volume en
mémoire d'une variable (le type de la variable détermine le volume
d'information stocké pour chaque élément ; être trop précis est parfois
néfaste).
Il existe plusieurs types possibles pour un `pandas.Series`.
Le type `object` correspond aux types Python `str` ou `mixed`.
Il existe un type particulier pour les variables dont le nombre de valeurs
est une liste finie et relativement courte, le type `category`.
Il faut bien examiner les types de son DataFrame, et convertir éventuellement
les types lors de l'étape de `data cleaning`.
## Indexation
La différence essentielle entre une `Series` et un objet `numpy` est l'indexation.
Dans `numpy`,
l'indexation est implicite ; elle permet d'accéder à une donnée (celle à
l'index situé à la position *i*).
Avec une `Series`, on peut bien-sûr utiliser un indice de position mais on peut
surtout faire appel à des indices plus explicites.
Par exemple,
```{python}
taille = pd.Series(
[1.,1.5,1],
index = ['chat', 'chien', 'koala']
)
taille.head()
```
Cette indexation permet d'accéder à des valeurs de la `Series`
via une valeur de l'indice. Par
exemple, `taille['koala']`:
```{python}
taille['koala']
```
L'existence d'indice rend le *subsetting* particulièrement aisé, ce que vous
pouvez expérimenter dans les TP
::: {.cell .markdown}
```{python}
#| echo: false
#| output: 'asis'
#| include: true
#| eval: true
import sys
sys.path.insert(1, '../../../../') #insert the utils module
from utils import print_badges
#print_badges(__file__)
print_badges("content/course/manipulation/02b_pandas_TP.qmd")
```
:::
Pour transformer un objet `pandas.Series` en array `numpy`,
on utilise la méthode `values`. Par exemple, `taille.values`:
```{python}
taille.values
```
Un avantage des `Series` par rapport à un *array* `numpy` est que
les opérations sur les `Series` alignent
automatiquement les données à partir des labels.
Avec des `Series` labélisées, il n'est ainsi pas nécessaire
de se poser la question de l'ordre des lignes.
L'exemple dans la partie suivante permettra de s'en assurer.
## Valeurs manquantes
Par défaut, les valeurs manquantes sont affichées `NaN` et sont de type `np.nan` (pour
les valeurs temporelles, i.e. de type `datatime64`, les valeurs manquantes sont
`NaT`).
On a un comportement cohérent d'agrégation lorsqu'on combine deux `DataFrames` (ou deux colonnes).
Par exemple,
```{python}
x = pd.DataFrame(
{'prix': np.random.uniform(size = 5),
'quantite': [i+1 for i in range(5)]
},
index = ['yaourt','pates','riz','tomates','gateaux']
)
x
```
```{python}
y = pd.DataFrame(
{'prix': [np.nan, 0, 1, 2, 3],
'quantite': [i+1 for i in range(5)]
},
index = ['tomates','yaourt','gateaux','pates','riz']
)
y
```
```{python}
x + y
```
donne bien une valeur manquante pour la ligne `tomates`. Au passage, on peut remarquer que l'agrégation
a tenu compte des index.
Il est possible de supprimer les valeurs manquantes grâce à `dropna()`.
Cette méthode va supprimer toutes les lignes où il y a au moins une valeur manquante.
Il est aussi possible de supprimer seulement les colonnes où il y a des valeurs manquantes
dans un DataFrame avec `dropna()` avec le paramètre `axis=1` (par défaut égal à 0).
Il est également possible de remplir les valeurs manquantes grâce à la méthode `fillna()`.
# Le DataFrame pandas
Le `DataFrame` est l'objet central de la librairie `pandas`.
Il s'agit d'une collection de `pandas.Series` (colonnes) alignées par les index.
Les types des variables peuvent différer.
Un DataFrame non-indexé a la structure suivante:
```{python}
#| echo: false
df = pd.DataFrame(
{'taille': [1.,1.5,1],
'poids' : [3, 5, 2.5]
},
index = ['chat', 'chien', 'koala']
)
df.reset_index()
```
Alors que le même dataframe indexé aura la structure suivante:
```{python}
#| echo: false
df = pd.DataFrame(
{'taille': [1.,1.5,1],
'poids' : [3, 5, 2.5]
},
index = ['chat', 'chien', 'koala']
)
df.head()
```
## Les attributs et méthodes utiles
Pour présenter les méthodes les plus pratiques pour l'analyse de données,
on peut partir de l'exemple des consommations de CO2 communales issues
des données de l'Ademe. Cette base de données est exploitée plus intensément
dans le TP
::: {.cell .markdown}
```{python}
#| echo: false
#| output: 'asis'
#| include: true
#| eval: true
import sys
sys.path.insert(1, '../../../../') #insert the utils module
from utils import print_badges
#print_badges(__file__)
print_badges("content/course/manipulation/02b_pandas_TP.qmd")
```
:::
```{python}
df = pd.read_csv("https://koumoul.com/s/data-fair/api/v1/datasets/igt-pouvoir-de-rechauffement-global/convert")
df
```
Dans un processus de production, où normalement on connait les types des variables du DataFrame qu'on va importer,
il convient de préciser les types avec lesquels on souhaite importer les données
(argument `dtype`, sous la forme d'un dictionnaire). Cela est particulièrement important lorsqu'on désire utiliser une colonne comme une variable textuelle mais qu'elle comporte des attributs proches d'un nombre qui vont inciter `pandas` à l'importer sous forme de variable numérique.
Par exemple, une colonne `[00001,00002,...] ` risque d'être importée comme une variable numérique, ignorant l'information des premiers 0 (qui peuvent pourtant la distinguer de la séquence 1, 2, etc.). Pour s'assurer que `pandas` importe sous forme textuelle la variable, on peut utiliser `dtype = {"code": "str"}`
Sinon, on peut importer le csv, et modifier les types avec `astype()`.
Avec `astype`, on peut gérer les erreurs de conversion avec le paramètre `errors`.
L'affichage des DataFrames est très ergonomique. On obtiendrait le même *output*
avec `display(df)`[^3]. Les premières et dernières lignes s'affichent
automatiquement. Autrement, on peut aussi faire:
* `head` qui permet, comme son
nom l'indique, de n'afficher que les premières lignes ;
* `tail` qui permet, comme son
nom l'indique, de n'afficher que les dernières lignes
* `sample` qui permet d'afficher un échantillon aléatoire de *n* lignes.
Cette méthode propose de nombreuses options
::: {.cell .markdown}
```{python}
#| echo: false
#| output: 'asis'
#| include: true
#| eval: true
import sys
sys.path.insert(1, '../../../../') #insert the utils module
from utils import print_badges
#print_badges(__file__)
print_badges("content/course/manipulation/02b_pandas_TP.qmd")
```
:::
::: {.cell .markdown}
[^3]: Il est préférable d'utiliser la fonction `display` (ou tout simplement
taper le nom du DataFrame qu'utiliser la fonction `print`). Le
`display` des objets `pandas` est assez esthétique, contrairement à `print`
qui renvoie du texte brut.
:::
{{% box status="danger" title="warning" icon="fa fa-exclamation-triangle" %}}
Il faut faire attention au `display` et aux
commandes qui révèlent des données (`head`, `tail`, etc.)
dans un notebook ou un markdown qui exploite
des données confidentielles lorsqu'on utilise `git`. En effet, on peut se
retrouver à partager des données, involontairement, dans l'historique
`git`. Avec un `R markdown`, il suffit d'ajouter les sorties au fichier
`gitignore` (par exemple avec une balise de type `*.html`). Avec un
notebook `jupyter`, la démarche est plus compliquée car les fichiers
`.ipynb` intègrent dans le même document, texte, sorties et mise en forme.
Techniquement, il est possible d'appliquer des filtres avec `git`
(voir
[ici](http://timstaley.co.uk/posts/making-git-and-jupyter-notebooks-play-nice/))
mais c'est une démarche très complexe
{{% /box %}}
On pourra alors préférer convertir systématiquement les `.ipynb` en `.py` grâce
à `jupytext` (`jupytext --to py nom_du_notebook.ipynb`) et mettre l'extension `*.ipynb`
dans le `.gitignore` de son projet git.
### Dimensions et structure du DataFrame
Les premières méthodes utiles permettent d'afficher quelques
attributs d'un DataFrame.
```{python}
df.axes
df.columns
df.index
```
Pour connaître les dimensions d'un DataFrame, on peut utiliser quelques méthodes
pratiques:
```{python}
df.ndim
df.shape
df.size
```
Pour déterminer le nombre de valeurs uniques d'une variable, plutôt que chercher à écrire soi-même une fonction,
on utilise la
méthode `nunique`. Par exemple,
```{python}
df['Commune'].nunique()
```
Voici un premier résumé des méthodes `pandas` utiles, et un comparatif avec `R`
| Opération | pandas | dplyr (`R`) | data.table (`R`) |
|-------------------------------|--------------|----------------|----------------------------|
| Récupérer le nom des colonnes | `df.columns` | `colnames(df)` | `colnames(df)` |
| Récupérer les indices[^4] | `df.index` | |`unique(df[,get(key(df))])` |
| Récupérer les dimensions | `df.shape` | `c(nrow(df), ncol(df))` | `c(nrow(df), ncol(df))` |
| Récupérer le nombre de valeurs uniques d'une variable | `df['myvar'].nunique()` | `df %>% summarise(distinct(myvar))` | `df[,uniqueN(myvar)]` |
::: {.cell .markdown}
[^4]: Le principe d'indice n'existe pas dans `dplyr`. Ce qui s'approche le plus des indices, au sens de
`pandas`, sont les *clés* en `data.table`.
:::
### Statistiques agrégées
`pandas` propose une série de méthodes pour faire des statistiques
agrégées de manière efficace.
On peut, par exemple, appliquer des méthodes pour compter le nombre de lignes,
faire une moyenne ou une somme de l'ensemble des lignes
```{python}
df.count()
df.mean()
df.sum()
df.nunique()
df.quantile(q = [0.1,0.25,0.5,0.75,0.9])
```
Il faut toujours regarder les options de ces fonctions en termes de valeurs manquantes, car
ces options sont déterminantes dans le résultat obtenu.
Les exercices de TD visent à démontrer l'intérêt de ces méthodes dans quelques cas précis.
::: {.cell .markdown}
```{python}
#| echo: false
#| output: 'asis'
#| include: true
#| eval: true
import sys
sys.path.insert(1, '../../../../') #insert the utils module
from utils import print_badges
#print_badges(__file__)
print_badges("content/course/manipulation/02b_pandas_TP.qmd")
```
:::
Le tableau suivant récapitule le code équivalent pour avoir des
statistiques sur toutes les colonnes d'un dataframe en `R`.
| Opération | pandas | dplyr (`R`) | data.table (`R`) |
|-------------------------------|--------------|----------------|----------------------------|
| Nombre de valeurs non manquantes | `df.count()` | `df %>% summarise_each(funs(sum(!is.na(.))))` | `df[, lapply(.SD, function(x) sum(!is.na(x)))]`
| Moyenne de toutes les variables | `df.mean()` | `df %>% summarise_each(funs(mean((., na.rm = TRUE))))` | `df[,lapply(.SD, function(x) mean(x, na.rm = TRUE))]`| TO BE CONTINUED |
La méthode `describe` permet de sortir un tableau de statistiques
agrégées:
```{python}
df.describe()
```
### Méthodes relatives aux valeurs manquantes
Les méthodes relatives aux valeurs manquantes peuvent être mobilisées
en conjonction des méthodes de statistiques agrégées. C'est utiles lorsqu'on
désire obtenir une idée de la part de valeurs manquantes dans un jeu de
données
[](https://mybinder.org/v2/gh/linogaliana/python-datascientist/master)
[](https://datalab.sspcloud.fr/launcher/ide/jupyter?onyxia.friendlyName=%C2%ABpython-datascientist%C2%BB&resources.requests.memory=%C2%AB4Gi%C2%BB)
[](http://colab.research.google.com/github/linogaliana/python-datascientist/blob/pandas_intro/static/notebooks/numpy.ipynb)
([ou depuis github](https://github.com/linogaliana/python-datascientist/blob/master/content/01_data/02_pandas_tp.ipynb))
```python
df.isnull().sum()
```
On trouvera aussi la référence à `isna()` qui est la même méthode que `isnull()`.
# Graphiques rapides
Les méthodes par défaut de graphique
(approfondies dans la [partie visualisation](#visualisation))
sont pratiques pour
produire rapidement un graphique, notamment après des opérations
complexes de maniement de données.
En effet, on peut appliquer la méthode `plot()` directement à une `pandas.Series`:
```{python matplotlib-example}
#| eval: false
df['Déchets'].plot()
df['Déchets'].hist()
df['Déchets'].plot(kind = 'hist', logy = True)
```
```{python matplotlib, include = FALSE}
plt.figure()
fig = df['Déchets'].plot()
fig
#plt.savefig('plot_base.png', bbox_inches='tight')
plt.figure()
fig = df['Déchets'].hist()
fig
#plt.savefig('plot_hist.png', bbox_inches='tight')
plt.figure()
fig = df['Déchets'].plot(kind = 'hist', logy = True)
fig
#plt.show()
#plt.savefig('plot_hist_log.png', bbox_inches='tight')
```
La sortie est un objet `matplotlib`. La *customisation* de ces
figures est ainsi
possible (et même désirable car les graphiques `matplotlib`
sont, par défaut, assez rudimentaires), nous en verrons quelques exemples.
# Accéder à des éléments d'un DataFrame
## Sélectionner des colonnes
En SQL, effectuer des opérations sur les colonnes se fait avec la commande
`SELECT`. Avec `pandas`,
pour accéder à une colonne dans son ensemble on peut
utiliser plusieurs approches:
* `dataframe.variable`, par exemple `df.Energie`.
Cette méthode requiert néanmoins d'avoir des
noms de colonnes sans espace.
* `dataframe[['variable']]` pour renvoyer la variable sous
forme de `DataFrame` ou dataframe['variable'] pour
la renvoyer sous forme de `Series`. Par exemple, `df[['Autres transports']]`
ou `df['Autres transports']`. C'est une manière préférable de procéder.
## Accéder à des lignes
Pour accéder à une ou plusieurs valeurs d'un `DataFrame`,
il existe deux manières conseillées de procéder, selon la
forme des indices de lignes ou colonnes utilisés:
* `df.loc`: use labels
* `df.iloc`: use indices
Les bouts de code utilisant la structure `df.ix`
sont à bannir car la fonction est *deprecated* et peut
ainsi disparaître à tout moment.
`iloc` va se référer à l'indexation de 0 à *N* où *N* est égal à `df.shape[0]` d'un
`pandas.DataFrame`. `loc` va se référer aux valeurs de l'index
de `df`.
Par exemple, si j'ai un `pandas.DataFrame` `df`:
```
year sale
month
1 2012 55
4 2014 40
7 2013 84
10 2014 31
```
Alors `df.loc[1, :]` donnera la première ligne de `df` (ligne où l'indice `month` est égal à 1) tandis que
`df.iloc[1, :]` donnera la deuxième ligne (puisque l'indexation en `Python` commence à 0).
<!----
data.loc[1:3]
data.loc[(data.age >= 20), ['section', 'city']]
data.iloc[[0,2]]
data.iloc[[0,2],[1,3]]
data.iloc[1:3,2:4]
data.loc[(data.age >= 12), ['section']]
------>
# Principales manipulation de données
L'objectif du [TP pandas](#pandasTP) est de se familiariser plus avec ces
commandes à travers l'exemple des données des émissions de C02.
Les opérations les plus fréquentes en SQL sont résumées par le tableau suivant.
Il est utile de les connaître (beaucoup de syntaxes de maniement de données
reprennent ces termes) car, d'une
manière ou d'une autre, elles couvrent la plupart
des usages de manipulation des données
| Opération | SQL | pandas | dplyr (`R`) | data.table (`R`) |
|-----|-----------|--------|-------------|------------------|
| Sélectionner des variables par leur nom | `SELECT` | `df[['Autres transports','Energie']]` | `df %>% select(Autres transports, Energie)` | `df[, c('Autres transports','Energie')]` |
| Sélectionner des observations selon une ou plusieurs conditions; | `FILTER` | `df[df['Agriculture']>2000]` | `df %>% filter(Agriculture>2000)` | `df[Agriculture>2000]` |
| Trier la table selon une ou plusieurs variables | `SORT BY` | `df.sort_values(['Commune','Agriculture'])` | `df %>% arrange(Commune, Agriculture)` | `df[order(Commune, Agriculture)]` |
| Ajouter des variables qui sont fonction d’autres variables; | `SELECT *, LOG(Agriculture) AS x FROM df` | `df['x'] = np.log(df['Agriculture'])` | `df %>% mutate(x = log(Agriculture))` | `df[,x := log(Agriculture)]` |
| Effectuer une opération par groupe | `GROUP BY` | `df.groupby('Commune').mean()` | `df %>% group_by(Commune) %>% summarise(m = mean)` | `df[,mean(Commune), by = Commune]` |
| Joindre deux bases de données (*inner join*) | `SELECT * FROM table1 INNER JOIN table2 ON table1.id = table2.x` | `table1.merge(table2, left_on = 'id', right_on = 'x')` | `table1 %>% inner_join(table2, by = c('id'='x'))` | `merge(table1, table2, by.x = 'id', by.y = 'x')` |
## Opérations sur les colonnes: select, mutate, drop
Les DataFrames pandas sont des objets *mutables* en langage `python`,
c'est-à-dire qu'il est possible de faire évoluer le DataFrame au grès
des opérations. L'opération la plus classique consiste à ajouter ou retirer
des variables à la table de données.
{{% box status="danger" title="warning" icon="fa fa-exclamation-triangle" %}}
Attention au comportement de `pandas` lorsqu'on crée une duplication
d'un DataFrame. Par défaut, `pandas` effectue une copie par référence. Dans ce
cas, les deux objets (la copie et l'objet copié) restent reliés. Les colonnes
crées sur l'un vont être répercutées sur l'autre. Ce comportement permet de
limiter l'inflation en mémoire de `python`. En faisant ça, le deuxième
objet prend le même espace mémoire que le premier. Le package `data.table`
en `R` adopte le même comportement, contrairement à `dplyr`.
Cela peut amener à quelques surprises si ce comportement d'optimisation
n'est pas anticipé. Si vous voulez, par sécurité, conserver intact le
premier DataFrame, faites appel à une copie profonde (*deep copy*) en
utilisant la méthode `copy`:
```{python}
df_new = df.copy()
```
Attention toutefois, cela a un coût mémoire. Avec des données volumineuses, c'est une pratique à utiliser avec précaution
{{% /box %}}
La manière la plus simple d'opérer pour ajouter des colonnes est
d'utiliser la réassignation. Par exemple, pour créer une variable
`x` qui est le `log` de la
variable `Agriculture`:
```{python}
df_new['x'] = np.log(df_new['Agriculture'])
```
Il est possible d'appliquer cette approche sur plusieurs colonnes. Un des
intérêts de cette approche est qu'elle permet de recycler le nom de colonnes.
```{python}
vars = ['Agriculture', 'Déchets', 'Energie']
df_new[[v + "_log" for v in vars]] = np.log(df_new[vars])
df_new
```
Il est également possible d'utiliser la méthode `assign`. Pour des opérations
vectorisées, comme le sont les opérateurs de `numpy`, cela n'a pas d'intérêt.
Cela permet notamment d'enchainer les opérations sur un même `DataFrame` (notamment grâce au `pipe` que
nous verrons plus loin).
Cette approche utilise généralement
des *lambda functions*. Par exemple le code précédent (celui concernant une
seule variable) prendrait la forme:
```{python}
df_new.assign(Energie_log = lambda x: np.log(x['Energie']))
```
Dans les méthodes suivantes, il est possible de modifier le `pandas.DataFrame`
*en place*, c'est à dire en ne le réassignant pas, avec le paramètre `inplace = True`.
Par défaut, `inplace` est égal à False et pour modifier le `pandas.DataFrame`,
il convient de le réassigner.
On peut facilement renommer des variables avec la méthode `rename` qui
fonctionne bien avec des dictionnaires (pour renommer des colonnes il faut
préciser le paramètre `axis = 1`):
```{python}
df_new = df_new.rename({"Energie": "eneg", "Agriculture": "agr"}, axis=1)
```
Enfin, pour effacer des colonnes, on utilise la méthode `drop` avec l'argument
`columns`:
```{python}
df_new = df_new.drop(columns = ["eneg", "agr"])
```
## Réordonner
La méthode `sort_values` permet de réordonner un `DataFrame`. Par exemple,
si on désire classer par ordre décroissant de consommation de CO2 du secteur
résidentiel, on fera
```{python}
df = df.sort_values("Résidentiel", ascending = False)
```
Ainsi, en une ligne de code, on identifie les villes où le secteur
résidentiel consomme le plus.
## Filtrer
L'opération de sélection de lignes s'appelle `FILTER` en SQL. Elle s'utilise
en fonction d'une condition logique (clause `WHERE`). On sélectionne les
données sur une condition logique. Il existe plusieurs méthodes en `pandas`.
La plus simple est d'utiliser les *boolean mask*, déjà vus dans le chapitre
[`numpy`](#numpy)
Par exemple, pour sélectionner les communes dans les Hauts-de-Seine, on
peut utiliser le résultat de la méthode `str.startswith` (qui renvoie
`True` ou `False`) directement dans les crochets:
```{python}
df[df['INSEE commune'].str.startswith("92")].head(2)
```
Pour remplacer des valeurs spécifiques, on utilise la méthode `where` ou une
réassignation couplée à la méthode précédente.
Par exemple, pour assigner des valeurs manquantes aux départements du 92,
on peut faire cela
```{python}
df_copy = df.copy()
df_copy = df_copy.where(~df['INSEE commune'].str.startswith("92"))
```
et vérifier les résultats:
```{python}
df_copy[df['INSEE commune'].str.startswith("92")].head(2)
df_copy[~df['INSEE commune'].str.startswith("92")].head(2)
```
ou alors utiliser une réassignation plus classique:
```{python}
df_copy = df.copy()
df_copy[df_copy['INSEE commune'].str.startswith("92")] = np.nan
```
Il est conseillé de filtrer avec `loc` en utilisant un masque.
En effet, contrairement à `df[mask]`, `df.loc[mask, :]` permet d'indiquer clairement
à Python que l'on souhaite appliquer le masque aux labels de l'index.
Ce n'est pas le cas avec `df[mask]`. D'ailleurs, lorsqu'on utilise la syntaxe `df[mask]`, `pandas` renvoie généralement un *warning*
## Opérations par groupe
En SQL, il est très simple de découper des données pour
effectuer des opérations sur des blocs cohérents et recollecter des résultats
dans la dimension appropriée.
La logique sous-jacente est celle du *split-apply-combine* qui est repris
par les langages de manipulation de données, auxquels `pandas`
[ne fait pas exception](https://pandas.pydata.org/pandas-docs/stable/user_guide/groupby.html).
L'image suivante, issue de
[ce site](https://unlhcc.github.io/r-novice-gapminder/16-plyr/)
représente bien la manière dont fonctionne l'approche
`split`-`apply`-`combine`
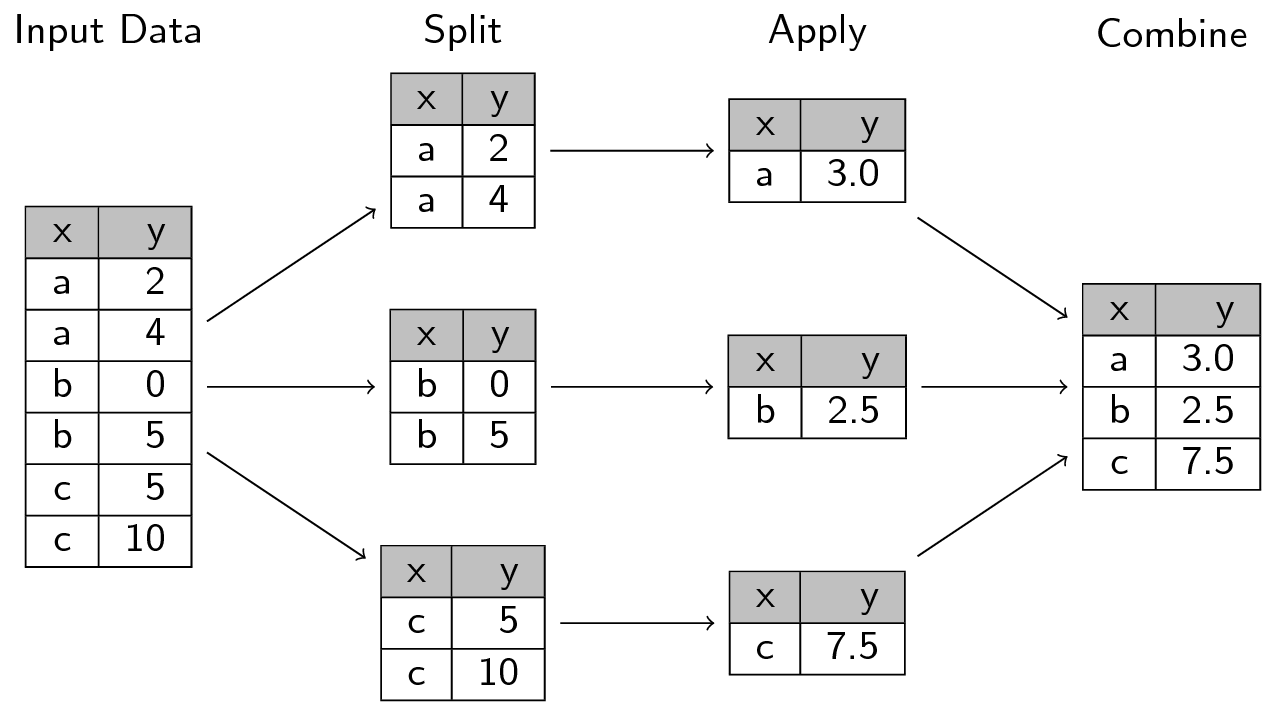
Ce [tutoriel](https://realpython.com/pandas-groupby/) sur le sujet
est particulièrement utile.
Pour donner quelques exemples, on peut créer une variable départementale qui
servira de critère de groupe.
```{python}
df['dep'] = df['INSEE commune'].str[:2]
```
En `pandas`, on utilise `groupby` pour découper les données selon un ou
plusieurs axes. Techniquement, cette opération consiste à créer une association
entre des labels (valeurs des variables de groupe) et des
observations.
Par exemple, pour compter le nombre de communes par département en SQL, on
utiliserait la requête suivante:
```sql
SELECT dep, count(INSEE commune)
FROM df
GROUP BY dep;
```
Ce qui, en `pandas`, donne:
```{python}
df.groupby('dep')["INSEE commune"].count()
```
La syntaxe est quasiment transparente. On peut bien-sûr effectuer des opérations
par groupe sur plusieurs colonnes. Par exemple,
```{python}
df.groupby('dep').mean()
```
A noter que la variable de groupe, ici `dep`, devient, par défaut, l'index
du DataFrame de sortie. Si on avait utilisé plusieurs variables de groupe,
on obtiendrait un objet multi-indexé. Sur la gestion des `multiindex`, on
pourra se référer à la référence de `Modern pandas` donnée en fin de cours.
Tant qu'on n'appelle pas une action sur un DataFrame par groupe, du type
`head` ou `display`, `pandas` n'effectue aucune opération. On parle de
*lazy evaluation*. Par exemple, le résultat de `df.groupby('dep')` est
une transformation qui n'est pas encore évaluée:
```{python}
df.groupby('dep')
```
Il est possible d'appliquer plus d'une opération à la fois grâce à la méthode
`agg`. Par exemple, pour obtenir à la fois le minimum, la médiane et le maximum
de chaque département, on peut faire:
```{python}
df.groupby('dep').agg(['min',"median","max"])
```
## Appliquer des fonctions
`pandas` est, comme on a pu le voir, un package très flexible, qui
propose une grande variété de méthodes optimisées. Cependant, il est fréquent
d'avoir besoin de méthodes non implémentées.
Dans ce cas, on recourt souvent aux `lambda` functions. Par exemple, si
on désire connaître les communes dont le nom fait plus de 10 caractères,
on peut appliquer la fonction `len` de manière itérative:
```{python}
# Noms de communes superieurs à 10 caracteres
df[df['Commune'].apply(lambda s: len(s)>40)]
```
Cependant, toutes les `lambda` functions ne se justifient pas.
Par exemple, prenons
le résultat d'agrégation précédent. Imaginons qu'on désire avoir les résultats
en milliers de tonnes. Dans ce cas, le premier réflexe est d'utiliser
la `lambda` function suivante:
```{python}
df.groupby('dep').agg(['min',"median","max"]).apply(lambda s: s/1000)
```
En effet, cela effectue le résultat désiré. Cependant, il y a mieux: utiliser
la méthode `div`:
```{python}
#| eval: false
import timeit
%timeit df.groupby('dep').agg(['min',"median","max"]).div(1000)
%timeit df.groupby('dep').agg(['min',"median","max"]).apply(lambda s: s/1000)
```
La méthode `div` est en moyenne plus rapide et a un temps d'exécution