-
Notifications
You must be signed in to change notification settings - Fork 45
/
6_pipeline.qmd
1083 lines (815 loc) · 35.5 KB
/
6_pipeline.qmd
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
490
491
492
493
494
495
496
497
498
499
500
501
502
503
504
505
506
507
508
509
510
511
512
513
514
515
516
517
518
519
520
521
522
523
524
525
526
527
528
529
530
531
532
533
534
535
536
537
538
539
540
541
542
543
544
545
546
547
548
549
550
551
552
553
554
555
556
557
558
559
560
561
562
563
564
565
566
567
568
569
570
571
572
573
574
575
576
577
578
579
580
581
582
583
584
585
586
587
588
589
590
591
592
593
594
595
596
597
598
599
600
601
602
603
604
605
606
607
608
609
610
611
612
613
614
615
616
617
618
619
620
621
622
623
624
625
626
627
628
629
630
631
632
633
634
635
636
637
638
639
640
641
642
643
644
645
646
647
648
649
650
651
652
653
654
655
656
657
658
659
660
661
662
663
664
665
666
667
668
669
670
671
672
673
674
675
676
677
678
679
680
681
682
683
684
685
686
687
688
689
690
691
692
693
694
695
696
697
698
699
700
701
702
703
704
705
706
707
708
709
710
711
712
713
714
715
716
717
718
719
720
721
722
723
724
725
726
727
728
729
730
731
732
733
734
735
736
737
738
739
740
741
742
743
744
745
746
747
748
749
750
751
752
753
754
755
756
757
758
759
760
761
762
763
764
765
766
767
768
769
770
771
772
773
774
775
776
777
778
779
780
781
782
783
784
785
786
787
788
789
790
791
792
793
794
795
796
797
798
799
800
801
802
803
804
805
806
807
808
809
810
811
812
813
814
815
816
817
818
819
820
821
822
823
824
825
826
827
828
829
830
831
832
833
834
835
836
837
838
839
840
841
842
843
844
845
846
847
848
849
850
851
852
853
854
855
856
857
858
859
860
861
862
863
864
865
866
867
868
869
870
871
872
873
874
875
876
877
878
879
880
881
882
883
884
885
886
887
888
889
890
891
892
893
894
895
896
897
898
899
900
901
902
903
904
905
906
907
908
909
910
911
912
913
914
915
916
917
918
919
920
921
922
923
924
925
926
927
928
929
930
931
932
933
934
935
936
937
938
939
940
941
942
943
944
945
946
947
948
949
950
951
952
953
954
955
956
957
958
959
960
961
962
963
964
965
966
967
968
969
970
971
972
973
974
975
976
977
978
979
980
981
982
983
984
985
986
987
988
989
990
991
992
993
994
995
996
997
998
999
1000
---
title: "Premier pas vers l'industrialisation avec les pipelines scikit"
date: 2023-10-20T13:00:00Z
weight: 60
slug: pipeline-scikit
tags:
- scikit
- Machine Learning
- Pipeline
- Modelisation
- Tutorial
categories:
- Modélisation
- Tutoriel
description: |
Les _pipelines_ `Scikit` permettent d'intégrer de manière très flexible
un ensemble d'opérations de pre-processing et d'entraînement de modèles
dans une chaîne d'opérations. Il s'agit d'une approche particulièrement
appropriée pour réduire la difficulté à changer d'algorithme ou pour
faciliter la ré-application d'un code à de nouvelles données.
echo: false
image: featured.png
bibliography: ../../reference.bib
---
::: {.content-visible when-format="html"}
{{< include "../../build/_printBadges.qmd" >}}
:::
Ce chapitre présente la première application
d'une journée de cours que j'ai
donné à l'Université Dauphine dans le cadre
des _PSL Data Week_.
<details>
<summary>
Dérouler les _slides_ associées ci-dessous ou [cliquer ici](https://linogaliana.github.io/dauphine-week-data/#/title-slide)
pour les afficher en plein écran.
</summary>
<div class="sourceCode" id="cb1"><pre class="sourceCode yaml code-with-copy"><code class="sourceCode yaml"></code><button title="Copy to Clipboard" class="code-copy-button"><i class="bi"></i></button></pre><iframe class="sourceCode yaml code-with-copy" src="https://linogaliana.github.io/dauphine-week-data/#/title-slide"></iframe></div>
</details>
Pour lire les données de manière efficace, nous
proposons d'utiliser le _package_ `duckdb`.
Pour l'installer, voici la commande :
```{python}
#| output: false
#| echo: true
!pip install duckdb
```
## Pourquoi utiliser les _pipelines_ ?
### Définitions préalables
Ce chapitre nous amènera à explorer plusieurs écosystèmes, pour lesquels on retrouve quelques buzz-words dont voici les définitions :
| Terme | Définition |
|-------|------------|
| _DevOps_ | Mouvement en ingénierie informatique et une pratique technique visant à l’unification du développement logiciel (dev) et de l’administration des infrastructures informatiques (ops) |
| _MLOps_ | Ensemble de pratiques qui vise à déployer et maintenir des modèles de machine learning en production de manière fiable et efficace |
Ce chapitre fera des références régulières au cours
de 3e année de l'ENSAE
[_"Mise en production de projets data science"_](https://ensae-reproductibilite.github.io/website/).
### Objectif
Les chapitres précédents ont permis de montrer des bouts de code
épars pour entraîner des modèles ou faire du _preprocessing_.
Cette démarche est intéressante pour tâtonner mais risque d'être coûteuse
ultérieurement s'il est nécessaire d'ajouter une étape de _preprocessing_
ou de changer d'algorithme.
Les _pipelines_ sont pensés pour simplifier la mise en production
ultérieure d'un modèle de _machine learning_.
Ils sont au coeur de la démarche de _MLOps_ qui est
présentée
dans le cours de 3e année de l'ENSAE
de [_"Mise en production de projets data science"_](https://ensae-reproductibilite.github.io/website/),
qui vise à simplifier la mise en oeuvre opérationnelle de
projets utilisant des techniques de _machine learning_.
```{python}
#| echo: true
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
import pandas as pd
```
### Les _pipelines_ `Scikit`
Heureusement, `Scikit` propose un excellent outil pour proposer un cadre
général pour créer une chaîne de production *machine learning*. Il
s'agit des
[_pipelines_](https://scikit-learn.org/stable/modules/compose.html).
Ils présentent de nombreux intérêts, parmi lesquels :
* Ils sont très __pratiques__ et __lisibles__. On rentre des données en entrée, on n'appelle qu'une seule fois les méthodes `fit` et `predict` ce qui permet de s'assurer une gestion cohérente des transformations de variables, par exemple après l'appel d'un `StandardScaler` ;
* La __modularité__ rend aisée la mise à jour d'un pipeline et renforce la capacité à le réutiliser ;
* Ils permettent de facilement chercher les hyperparamètres d'un modèle. Sans *pipeline*, écrire un code qui fait du *tuning* d'hyperparamètres peut être pénible. Avec les *pipelines*, c'est une ligne de code ;
* La __sécurité__ d'être certain que les étapes de preprocessing sont bien appliquées aux jeux de données désirés avant l'estimation.
::: {.cell .markdown}
```{=html}
<div class="alert alert-warning" role="alert">
<h3 class="alert-heading"><i class="fa-solid fa-lightbulb"></i> Hint</h3>
```
Un des intérêts des *pipelines* scikit est qu'ils fonctionnent aussi avec
des méthodes qui ne sont pas issues de `scikit`.
Il est possible d'introduire un modèle de réseau de neurone `Keras` dans
un pipeline `scikit`.
Pour introduire un modèle économétrique `statsmodels`
c'est un peu plus coûteux mais nous allons proposer des exemples
qui peuvent servir de modèle et qui montrent que c'est faisable
sans trop de difficulté.
```{=html}
</div>
```
:::
## Comment créer un *pipeline*
Un *pipeline* est un enchaînement d'opérations qu'on code en enchainant
des pairs *(clé, valeur)* :
* la clé est le nom du pipeline, cela peut être utile lorsqu'on va
représenter le *pipeline* sous forme de diagramme acyclique (visualisation DAG)
ou qu'on veut afficher des informations sur une étape
* la valeur représente la transformation à mettre en oeuvre dans le *pipeline*
(c'est-à-dire, à l'exception de la dernière étape,
mettre en oeuvre une méthode `transform` et éventuellement une
transformation inverse).
```{python}
#| echo: true
from sklearn.pipeline import Pipeline
from sklearn.svm import SVC
from sklearn.decomposition import PCA
estimators = [('reduce_dim', PCA()), ('clf', SVC())]
pipe = Pipeline(estimators)
pipe
```
Au sein d'une étape de *pipeline*, les paramètres d'un estimateur
sont accessibles avec la notation `<estimator>__<parameter>`.
Cela permet de fixer des valeurs pour les arguments des fonctions `scikit`
qui sont appelées au sein d'un *pipeline*.
C'est cela qui rendra l'approche des pipelines particulièrement utile
pour la *grid search* :
```{python}
#| echo: true
from sklearn.model_selection import GridSearchCV
param_grid = {"reduce_dim__n_components":[2, 5, 10], "clf__C":[0.1, 10, 100]}
grid_search = GridSearchCV(pipe, param_grid=param_grid)
grid_search
```
Ces _pipelines_ sont initialisés sans données, il s'agit d'une structure formelle
que nous allons ensuite ajuster en entraînant des modèles.
### Données utilisées
Nous allons utiliser les données
de transactions immobilières [DVF](https://app.dvf.etalab.gouv.fr/) pour chercher
la meilleure manière de prédire, sachant les caractéristiques d'un bien, son
prix.
Ces données sont mises à disposition
sur [`data.gouv`](https://www.data.gouv.fr/fr/datasets/demandes-de-valeurs-foncieres/).
Néanmoins, le format csv n'étant pas pratique pour importer des jeux de données
volumineux, nous proposons de privilégier la version `Parquet` mise à
disposition par Eric Mauvière sur [`data.gouv`](https://www.data.gouv.fr/fr/datasets/dvf-2022-format-parquet/#/discussions).
L'approche la plus efficace pour lire ces données est
d'utiliser `DuckDB` afin de lire le fichier, extraire les colonnes
d'intérêt puis passer à `Pandas` (pour en savoir plus sur
l'intérêt de `DuckDB` pour lire des fichiers volumineux, vous pouvez
consulter [ce post de blog](https://ssphub.netlify.app/post/parquetrp/) ou
[celui-ci](https://www.icem7.fr/outils/3-explorations-bluffantes-avec-duckdb-1-interroger-des-fichiers-distants/) écrit
par Eric Mauvière).
Même si, en soi, les gains de temps sont faibles car `DuckDB` optimise
les requêtes HTTPS nécessaires à l'import des données, nous proposons
de télécharger les données pour réduire les besoins de bande passante.
```{python}
#| echo: true
#| eval: false
import requests
import os
url = "https://www.data.gouv.fr/fr/datasets/r/56bde1e9-e214-408b-888d-34c57ff005c4"
file_name = "dvf.parquet"
# Check if the file already exists
if not os.path.exists(file_name):
response = requests.get(url)
if response.status_code == 200:
with open(file_name, "wb") as f:
f.write(response.content)
print("Téléchargement réussi.")
else:
print(f"Échec du téléchargement. Code d'état : {response.status_code}")
else:
print(f"Le fichier '{file_name}' existe déjà. Aucun téléchargement nécessaire.")
```
En premier lieu, puisque cela va faciliter les requêtes SQL ultérieures, on crée
une vue :
```{python}
#| echo: false
import duckdb
# version remote
url = "https://www.data.gouv.fr/fr/datasets/r/56bde1e9-e214-408b-888d-34c57ff005c4"
duckdb.sql(f'CREATE OR REPLACE VIEW dvf AS SELECT * FROM read_parquet("{url}")')
```
```{python}
#| echo: true
#| eval: false
import duckdb
duckdb.sql(f'CREATE OR REPLACE VIEW dvf AS SELECT * FROM read_parquet("dvf.parquet")')
```
Les données prennent la forme suivante :
```{python}
#| echo: true
duckdb.sql(f"SELECT * FROM dvf LIMIT 5")
```
Les variables que nous allons conserver sont les suivantes,
nous allons les reformater pour la suite de l'exercice.
```{python}
#| echo: true
xvars = [
"Date mutation", "Valeur fonciere",
'Nombre de lots', 'Code type local',
'Nombre pieces principales'
]
xvars = ", ".join([f'"{s}"' for s in xvars])
```
```{python}
#| echo: true
mutations = duckdb.sql(
f'''
SELECT
date_part('month', "Date mutation") AS month,
substring("Code postal", 1, 2) AS dep,
{xvars},
COLUMNS('Surface Carrez.*')
FROM dvf
'''
).to_df()
colonnes_surface = mutations.columns[mutations.columns.str.startswith('Surface Carrez')]
mutations.loc[:, colonnes_surface] = mutations.loc[:, colonnes_surface].replace({',': '.'}, regex=True).astype(float).fillna(0)
```
::: {.cell .markdown}
```{=html}
<div class="alert alert-info" role="alert">
<h3 class="alert-heading"><i class="fa-solid fa-comment"></i> Note</h3>
```
Le fichier `Parquet` mis à disposition sur `data.gouv` présente une incohérence de mise en forme de
certaines colonnes à cause des virgules qui empêchent le formattage sous forme de colonne
numérique.
Le code ci-dessus effectue la conversion adéquate au niveau de `Pandas`.
```{=html}
</div>
```
:::
```{python}
#| echo: true
mutations.head(2)
```
::: {.cell .markdown}
<details>
<summary>
Introduire un effet confinement
</summary>
Si vous travaillez avec les données de 2020, n'oubliez pas
d'intégrer l'effet
confinement dans vos modèles puisque cela a lourdement
affecté les possibilités de transaction sur cette période, donc
l'effet potentiel de certaines variables explicatives du prix.
Pour introduire cet effet, vous pouvez créer une variable
indicatrice entre les dates en question:
```python
mutations['confinement'] = (
mutations['Date mutation']
.between(pd.to_datetime("2020-03-17"), pd.to_datetime("2020-05-03"))
.astype(int)
)
```
Comme nous travaillons sur les données de 2022,
nous pouvons nous passer de cette variable.
</details>
:::
Les données DVF proposent une observation par transaction.
Ces transactions
peuvent concerner plusieurs lots. Par exemple, un appartement
avec garage et cave comportera trois lots.
Pour simplifier,
on va créer une variable de surface qui agrège les différentes informations
de surface disponibles dans le jeu de données.
Les agréger revient à supposer que le modèle de fixation des prix est le même
entre chaque lot. C'est une hypothèse simplificatrice qu'une personne plus
experte du marché immobilier, ou qu'une approche propre de sélection
de variable pourrait amener à nier. En effet, les variables
en question sont faiblement corrélées les unes entre elles, à quelques
exceptions près (@fig-corr-surface):
```{python}
#| echo: true
#| output: false
corr = mutations.loc[
:,
mutations.columns[mutations.columns.str.startswith('Surface Carrez')].tolist()
]
corr.columns = corr.columns.str.replace("Carrez du ", "")
corr = corr.corr()
mask = np.triu(np.ones_like(corr, dtype=bool))
cmap = sns.diverging_palette(230, 20, as_cmap=True)
```
```{python}
#| echo: true
#| fig-cap: Matrice de corrélation des variables de surface
#| label: fig-corr-surface
fig, ax = plt.subplots(1)
g = sns.heatmap(
corr, ax=ax,
mask=mask,
vmax=.3, center=0,
square=True, linewidths=.5, cbar_kws={"shrink": .5},
xticklabels=corr.columns.values,
yticklabels=corr.columns.values, cmap=cmap, annot=True, fmt=".2f"
)
g
```
```{python}
#| echo: true
mutations['lprix'] = np.log(mutations["Valeur fonciere"])
mutations['surface'] = mutations.loc[:, colonnes_surface].sum(axis = 1).astype(int)
```
```{python}
#| echo: true
mutations['surface'] = mutations.loc[:, mutations.columns[mutations.columns.str.startswith('Surface Carrez')].tolist()].sum(axis = 1)
```
## Un premier pipeline : *random forest* sur des variables standardisées
Notre premier *pipeline* va nous permettre d'intégrer ensemble:
1. Une étape de *preprocessing* avec la standardisation de variables
2. Une étape d'estimation du prix en utilisant un modèle de *random forest*
Pour le moment, on va prendre comme acquis un certain nombre de variables
explicatives (les *features*) et les hyperparamètres du modèle.
L'algorithme des _random forest_ est une technique statistique basée sur
les arbres de décision. Elle a été définie explicitement par l'un
des pionniers du _machine learning_, @breiman2001random.
Il s'agit d'une [méthode ensembliste](https://en.wikipedia.org/wiki/Ensemble_learning)
puisqu'elle consiste à utiliser plusieurs algorithmes (en l'occurrence des arbres
de décision) pour obtenir une meilleure prédiction que ne le permettraient
chaque modèle isolément.
Les _random forest_ sont une méthode d'aggrégation[^2] d'arbres de décision.
On calcule $K$ arbres de décision et en tire, par une méthode d'agrégation,
une règle de décision moyenne qu'on va appliquer pour tirer une
prédiction de nos données.
[^2]: Les _random forest_ sont l'une des principales méthodes
ensemblistes. Outre cette approche, les plus connues sont
le [_bagging_ (_boostrap aggregating_)](https://en.wikipedia.org/wiki/Bootstrap_aggregating) et le _boosting_
qui consistent à choisir la prédiction à privilégier
selon des algorithmes de choix différens.
Par exemple le _bagging_ est une technique basée sur le vote majoritaire [@breiman1996bagging].
Cette technique s'inspire du _bootstrap_ qui, en économétrie,
consiste à ré-estimer sur *K* sous-échantillons
aléatoires des données un estimateur afin d'en tirer, par exemple, un intervalle
de confiance empirique à 95%. Le principe du _bagging_ est le même. On ré-estime
_K_ fois notre estimateur (par exemple un arbre de décision) et propose une
règle d'agrégation pour en tirer une règle moyennisée et donc une prédiction.
Le _boosting_ fonctionne selon un principe différent, basé sur
l'optimisation de combinaisons de classifieurs faibles.
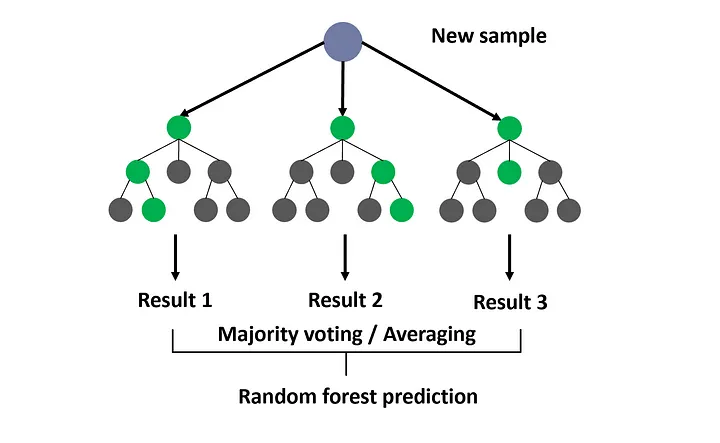
L'un des intérêts
des *random forest* est qu'il existe des méthodes pour déterminer
l'importance relative de chaque variable dans la prédiction.
Nous allons ici partir d'un *random forest* avec des valeurs d'hyperparamètres
données, à savoir la profondeur de l'arbre.
### Définition des ensembles _train_ et _test_
Nous allons donc nous restreindre à un sous-ensemble de colonnes dans un
premier temps.
Nous allons également ne conserver que les
transactions inférieures à 5 millions
d'euros (on anticipe que celles ayant un montant supérieur sont des transactions
exceptionnelles dont le mécanisme de fixation du prix diffère)
```{python}
#| echo: true
mutations2 = mutations.drop(
colonnes_surface.tolist() + ["Date mutation", "lprix"], # ajouter "confinement" si données 2020
axis = "columns"
).copy()
mutations2 = mutations2.loc[mutations2['Valeur fonciere'] < 5e6] #keep only values below 5 millions
mutations2.columns = mutations2.columns.str.replace(" ", "_")
mutations2 = mutations2.dropna(subset = ['dep','Code_type_local','month'])
```
Notre _pipeline_ va incorporer deux types de variables: les variables
catégorielles et les variables numériques.
Ces différents types vont bénéficier d'étapes de _preprocessing_
différentes.
```{python}
#| echo: true
numeric_features = mutations2.columns[~mutations2.columns.isin(['dep','Code_type_local', 'month', 'Valeur_fonciere'])].tolist()
categorical_features = ['dep','Code_type_local','month']
```
Au passage, nous avons abandonné la variable de code postal pour privilégier
le département afin de réduire la dimension de notre jeu de données. Si on voulait
vraiment avoir un bon modèle, il faudrait faire autrement car le code postal
est probablement un très bon prédicteur du prix d'un bien, une fois que
les caractéristiques du bien sont contrôlées.
::: {.cell .markdown}
```{=html}
<div class="alert alert-success" role="alert">
<h3 class="alert-heading"><i class="fa-solid fa-pencil"></i> Exercice 1 : Découpage des échantillons</h3>
```
Nous allons stratifier notre échantillonage de _train/test_ par département
afin de tenir compte, de manière minimale, de la géographie.
Pour accélérer les calculs pour ce tutoriel, nous n'allons considérer que
30% des transactions observées sur chaque département.
Voici le code pour le faire:
```python
mutations2 = mutations2.groupby('dep').sample(frac = 0.1, random_state = 123)
```
Avec la fonction adéquate de `Scikit`, faire un découpage de `mutations2`
en _train_ et _test sets_
en suivant les consignes suivantes:
- 20% des données dans l'échantillon de _test_ ;
- L'échantillonnage est stratifié par départements ;
- Pour avoir des résultats reproductibles, choisir une racine égale à 123.
```{=html}
</div>
```
:::
```{python}
from sklearn.model_selection import train_test_split
mutations2 = mutations2.groupby('dep').sample(frac = 0.1, random_state = 123)
X_train, X_test, y_train, y_test = train_test_split(
mutations2.drop("Valeur_fonciere", axis = 1),
mutations2[["Valeur_fonciere"]].values.ravel(),
test_size = 0.2, random_state = 123, stratify=mutations2[['dep']]
)
```
### Définition du premier _pipeline_
Pour commencer, nous allons fixer la taille des arbres de décision avec
l'hyperparamètre `max_depth = 2`.
Notre _pipeline_ va intégrer les étapes suivantes :
1. __Preprocessing__ :
+ Les variables numériques vont être standardisées avec un `StandardScaler`.
Pour cela, nous allons utiliser la liste `numeric_features` définie précédemment.
+ Les variables catégorielles vont être explosées avec un *one hot encoding*
(méthode `OneHotEncoder` de `scikit`)
Pour cela, nous allons utiliser la liste `categorical_features`
2. __Random forest__ : nous allons appliquer l'estimateur _ad hoc_ de `Scikit`.
::: {.cell .markdown}
```{=html}
<div class="alert alert-success" role="alert">
<h3 class="alert-heading"><i class="fa-solid fa-pencil"></i> Exercice 2 : Construction d'un premier pipeline formel</h3>
```
1. Initialiser un _random forest_ de profondeur 2. Fixer la racine à 123 pour avoir des résultats reproductibles.
2. La première étape du _pipeline_ (nommer cette couche _preprocessor_) consiste à appliquer les étapes de _preprocessing_ adaptées à chaque type de variables:
- Pour les variables numériques, appliquer une étape d'imputation à la moyenne puis standardiser celles-ci
- Pour les variables catégorielles, appliquer un [_one hot encoding_](https://en.wikipedia.org/wiki/One-hot)
3. Appliquer comme couche de sortie le modèle défini plus tôt.
_💡 Il est recommandé de s'aider de la documentation de `Scikit`. Si vous avez besoin d'un indice supplémentaire, consulter le pipeline présenté ci-dessous._
```{=html}
</div>
```
:::
```{python}
#| label: exo2-q1
# Question 1
from sklearn.ensemble import RandomForestRegressor
regr = RandomForestRegressor(max_depth=2, random_state=123)
```
```{python}
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.pipeline import make_pipeline, Pipeline
from sklearn.compose import make_column_transformer
numeric_pipeline = make_pipeline(
SimpleImputer(),
StandardScaler()
)
transformer = make_column_transformer(
(numeric_pipeline, numeric_features),
(OneHotEncoder(sparse = False, handle_unknown = "ignore"), categorical_features))
pipe = Pipeline(steps=[('preprocessor', transformer),
('randomforest', regr)])
```
A l'issue de cet exercice, nous devrions obtenir le _pipeline_ suivant.
```{python}
pipe
```
Nous avons construit ce pipeline sous forme de couches successives. La couche
`randomforest` prendra automatiquement le résultat de la couche `preprocessor`
en _input_. La couche `features` permet d'introduire de manière relativement
simple (quand on a les bonnes méthodes) la complexité du *preprocessing*
sur données réelles dont les types divergent.
A cette étape, rien n'a encore été estimé.
C'est très simple à mettre en oeuvre
avec un _pipeline_.
::: {.cell .markdown}
```{=html}
<div class="alert alert-success" role="alert">
<h3 class="alert-heading"><i class="fa-solid fa-pencil"></i> Exercice 3 : Mise en oeuvre du pipeline</h3>
```
1. Estimer les paramètres du modèle sur le jeu d'entraînement
2. Observer la manière dont les données d'entraînement sont transformées
par l'étape de _preprocessing_ avec les méthodes adéquates sur 4 observations de `X_train`
tirées aléatoirement
3. Utiliser ce modèle pour prédire le prix sur l'échantillon de test. A partir de ces quelques prédictions,
quel semble être le problème ?
4. Observer la manière dont ce _preprocessing_ peut s'appliquer sur deux exemples fictifs :
+ Un appartement (`code_type_local = 2`) dans le 75, vendu au mois de mai, unique lot de la vente avec 3 pièces, faisant 75m² ;
+ Une maison (`code_type_local = 1`) dans le 06, vendue en décembre, dans une transaction avec 2 lots. La surface complète est de 180m² et le bien comporte 6 pièces.
5. Déduire sur ces deux exemples le prix prédit par le modèle.
6. Calculer et interpréter le RMSE sur l'échantillon de test. Ce modèle est-il satisfaisant ?
```{=html}
</div>
```
:::
```{python}
pipe.fit(X_train, y_train)
```
```{python}
#| output: false
# Question 2
pipe[:-1].transform(X_train.sample(4))
```
```{python}
# Question 4
pipe.predict(X_test)
```
```{python}
# Question 5
X_fictif = pd.DataFrame(
{
"month": [3, 12],
"dep": ["75", "06"],
"Nombre_de_lots": [1, 2],
"Code_type_local": [2, 1],
"Nombre_pieces_principales": [3., 6.],
"surface": [75., 180.]
}
)
pipe[:-1].transform(X_fictif)
pipe.predict(X_fictif)
```
```{python}
from sklearn.metrics import mean_squared_error
np.sqrt(
mean_squared_error(
pipe.predict(X_test),
y_test
)
)
```
### _Variable importance_
Les prédictions semblent avoir une assez faible variance, comme si des variables
de seuils intervenaient. Nous allons donc devoir essayer de comprendre pourquoi.
La _"variable importance"_
se réfère à la mesure de l'influence de chaque variable d'entrée sur la performance du modèle.
L'impureté fait référence à l'incertitude ou à l'entropie présente dans un ensemble de données.
Dans le contexte des _random forest_, cette mesure est souvent calculée en évaluant la réduction moyenne de l'impureté des nœuds de décision causée par une variable spécifique.
Cette approche permet de quantifier l'importance des variables dans le processus de prise de décision du modèle, offrant ainsi des intuitions sur les caractéristiques les plus informatives pour la prédiction (plus de détails [sur ce blog](https://mljar.com/blog/feature-importance-in-random-forest/)).
On ne va représenter, parmi notre ensemble important de colonnes, que celles
qui ont une importance non nulle.
::: {.cell .markdown}
```{=html}
<div class="alert alert-success" role="alert">
<h3 class="alert-heading"><i class="fa-solid fa-pencil"></i> Exercice 4 : Compréhension du modèle</h3>
```
1. Récupérer la _feature importance_ directement depuis la couche adaptée de votre _pipeline_
2. Utiliser le code suivant pour calculer l'intervalle de confiance de cette mesure d'importance:
```python
std = np.std([tree.feature_importances_ for tree in pipe['randomforest'].estimators_], axis=0)
```
3. Représenter les variables d'importance non nulle. Qu'en concluez-vous ?
```{=html}
</div>
```
:::
Le graphique d'importance des variables que vous devriez obtenir à l'issue
de cet exercice est le suivant.
```{python}
features_names = pipe[:-1].get_feature_names_out()
importances = pipe['randomforest'].feature_importances_
std = np.std([tree.feature_importances_ for tree in pipe['randomforest'].estimators_], axis=0)
forest_importances = pd.DataFrame(importances, index=features_names, columns = ["mdi"])
forest_importances['std'] = std
fig, ax = plt.subplots()
forest_importances.loc[forest_importances['mdi']>0, 'mdi'].plot.bar(
yerr = forest_importances.loc[forest_importances['mdi']>0, 'std'], ax = ax
)
ax.set_title("Feature importances using MDI")
ax.set_ylabel("Mean decrease in impurity")
fig.tight_layout()
```
```{python}
#| echo: false
ax
```
Les statistiques obtenues par le biais de cette _variable importance_
sont un peu rudimentaires mais permettent déjà de comprendre
le problème de notre modèle.
On voit donc que deux de nos variables déterminantes sont des effets fixes
géographiques (qui servent à ajuster de la différence de prix entre
Paris et les Hauts de Seine et le reste de la France), une autre variable
est un effet fixe type de bien. Les deux variables qui pourraient introduire
de la variabilité, à savoir la surface et, dans une moindre mesure, le
nombre de lots, ont une importance moindre.
::: {.cell .markdown}
```{=html}
<div class="alert alert-info" role="alert">
<h3 class="alert-heading"><i class="fa-solid fa-comment"></i> Note</h3>
```
Idéalement, on utiliserait `Yellowbrick` pour représenter l'importance des variables
Mais en l'état actuel du *pipeline* on a beaucoup de variables dont le poids
est nul qui viennent polluer la visualisation. Vous pouvez
consulter la
[documentation de `Yellowbrick` sur ce sujet](https://www.scikit-yb.org/en/latest/api/model_selection/importances.html)
```{=html}
</div>
```
:::
Les prédictions peuvent nous suggérer également
qu'il y a un problème:
```{python}
#| echo: true
compar = pd.DataFrame([y_test, pipe.predict(X_test)]).T
compar.columns = ['obs','pred']
compar['diff'] = compar.obs - compar.pred
g = sns.relplot(data = compar, x = 'obs', y = 'pred', color = "royalblue", alpha = 0.8)
g.set(ylim=(0, 2e6), xlim=(0, 2e6),
title='Evaluating estimation error on test sample',
xlabel='Observed values',
ylabel='Predicted values')
g.ax.axline(xy1=(0, 0), slope=1, color="red", dashes=(5, 2))
```
## Restriction du champ du modèle
Mettre en oeuvre un bon modèle de prix au niveau France entière
est complexe. Nous allons donc nous restreindre au champ suivant:
les appartements dans Paris.
```{python}
#| echo: true
mutations_paris = mutations.drop(
colonnes_surface.tolist() + ["Date mutation", "lprix"], # ajouter "confinement" si données 2020
axis = "columns"
).copy()
mutations_paris = mutations_paris.loc[mutations_paris['Valeur fonciere'] < 5e6] #keep only values below 5 millions
mutations_paris.columns = mutations_paris.columns.str.replace(" ", "_")
mutations_paris = mutations_paris.dropna(subset = ['dep','Code_type_local','month'])
mutations_paris = mutations_paris.loc[mutations_paris['dep'] == "75"]
mutations_paris = mutations_paris.loc[mutations_paris['Code_type_local'] == 2].drop(['dep','Code_type_local'], axis = "columns")
mutations_paris.loc[mutations_paris['surface']>0]
```
::: {.cell .markdown}
```{=html}
<div class="alert alert-success" role="alert">
<h3 class="alert-heading"><i class="fa-solid fa-pencil"></i> Exercice 4 : Pipeline plus simple</h3>
```
Reprendre les codes précédents et reconstruire notre _pipeline_ sur
la nouvelle base en mettant en oeuvre une méthode de _boosting_
plutôt qu'une forêt aléatoire.
```{=html}
</div>
```
:::
A l'issue de cet exercice, vous devriez avoir des _MDI_ proches
de celles-ci :
```{python}
#| label: estim-model-paris
from sklearn.ensemble import GradientBoostingRegressor
mutations_paris = mutations.drop(
colonnes_surface.tolist() + ["Date mutation", "lprix"], # ajouter "confinement" si données 2020
axis = "columns"
).copy()
mutations_paris = mutations_paris.loc[mutations_paris['Valeur fonciere'] < 5e6] #keep only values below 5 millions
mutations_paris.columns = mutations_paris.columns.str.replace(" ", "_")
mutations_paris = mutations_paris.dropna(subset = ['dep','Code_type_local','month'])
mutations_paris = mutations_paris.loc[mutations_paris['dep'] == "75"]
mutations_paris = mutations_paris.loc[mutations_paris['Code_type_local'] == 2].drop(['dep','Code_type_local', 'Nombre_de_lots'], axis = "columns")
mutations_paris.loc[mutations_paris['surface']>0]
numeric_features = mutations_paris.columns[~mutations_paris.columns.isin(['month', 'Valeur_fonciere'])].tolist()
categorical_features = ['month']
reg = GradientBoostingRegressor(random_state=0)
numeric_pipeline = make_pipeline(
SimpleImputer(),
StandardScaler()
)
transformer = make_column_transformer(
(numeric_pipeline, numeric_features),
(OneHotEncoder(sparse = False, handle_unknown = "ignore"), categorical_features))
pipe = Pipeline(steps=[('preprocessor', transformer),
('boosting', reg)])
X_train, X_test, y_train, y_test = train_test_split(
mutations_paris.drop("Valeur_fonciere", axis = 1),
mutations_paris[["Valeur_fonciere"]].values.ravel(),
test_size = 0.2, random_state = 123
)
pipe.fit(X_train, y_train)
pd.DataFrame(
pipe["boosting"].feature_importances_,
index = pipe[:-1].get_feature_names_out()
)
```
## Recherche des hyperparamètres optimaux avec une validation croisée
On détecte que le premier modèle n'est pas très bon et ne nous aidera
pas vraiment à évaluer de manière fiable l'appartement de nos rêves.
On va essayer de voir si notre modèle ne serait pas meilleur avec des
hyperparamètres plus adaptés. Après tout, nous avons choisi par défaut
la profondeur de l'arbre mais c'était un choix au doigt mouillé.
❓️ Quels sont les hyperparamètres qu'on peut essayer d'optimiser ?
```{python}
pipe['boosting'].get_params()
```
Un [détour par la documentation](https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestRegressor.html)
nous aide à comprendre ceux sur lesquels on va jouer. Par exemple, il serait
absurde de jouer sur le paramètre `random_state` qui est la racine du générateur
pseudo-aléatoire.
```{python}
X = pd.concat((X_train, X_test), axis=0)
Y = np.concatenate([y_train,y_test])
```
Nous allons nous contenter de jouer sur les paramètres:
* `n_estimators`: Le nombre d'arbres de décision que notre forêt contient
* `max_depth`: La profondeur de chaque arbre
Il existe plusieurs manières de faire de la validation croisée. Nous allons ici
utiliser la *grid search* qui consiste à estimer et tester le modèle sur chaque
combinaison d'une grille de paramètres et sélectionner le couple de valeurs
des hyperparamètres amenant à la meilleure prédiction. Par défaut, `scikit`
effectue une _5-fold cross validation_. Nous n'allons pas changer
ce comportement.
Comme expliqué précédemment, les paramètres s'appelent sous la forme
`<step>__<parameter_name>`
La validation croisée pouvant être très consommatrice de temps, nous
n'allons l'effectuer que sur un nombre réduit de valeurs de notre grille.
Il est possible de passer la liste des valeurs à passer au crible sous
forme de liste
(comme nous allons le proposer pour l'argument `max_depth` dans l'exercice ci-dessous) ou
sous forme d'`array` (comme nous allons le proposer pour l'argument `n_estimators`) ce qui est
souvent pratique pour générer un criblage d'un intervalle avec `np.linspace`.
::: {.cell .markdown}
```{=html}
<div class="alert alert-warning" role="alert">
<h3 class="alert-heading"><i class="fa-solid fa-lightbulb"></i> Hint </h3>
```
Les estimations sont, par défaut, menées de manière séquentielle (l'une après
l'autre). Nous sommes cependant face à un problème
*embarassingly parallel*.
Pour gagner en performance, il est recommandé d'utiliser l'argument
`n_jobs=-1`.
```{=html}
</div>
```
:::
```{python}
#| output: false
#| label: grid-search
import numpy as np
from sklearn.model_selection import GridSearchCV
import time
start_time = time.time()
# Parameters of pipelines can be set using ‘__’ separated parameter names:
param_grid = {
"boosting__n_estimators": np.linspace(5,25, 5).astype(int),
"boosting__max_depth": [2,4]
}
grid_search = GridSearchCV(pipe, param_grid=param_grid)
grid_search.fit(X, Y)
end_time = time.time()
print(f"Elapsed time : {int(end_time - start_time)} seconds")
```
```{python}
grid_search
```
```{python}
grid_search.best_params_
grid_search.best_estimator_
```
Toutes les performances sur les ensembles d'échantillons et de test sur la grille
d'hyperparamètres sont disponibles dans l'attribut:
```{python}
perf_random_forest = pd.DataFrame(grid_search.cv_results_)
```