-
Notifications
You must be signed in to change notification settings - Fork 45
/
5_clustering.qmd
508 lines (378 loc) · 19.8 KB
/
5_clustering.qmd
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
490
491
492
493
494
495
496
497
498
499
500
501
502
503
504
505
506
507
508
---
title: "Clustering"
date: 2023-07-20T13:00:00Z
weight: 60
slug: clustering
type: book
tags:
- scikit
- Machine Learning
- US elections
- clustering
- Kmeans
- Modelisation
- Exercice
categories:
- Modélisation
- Exercice
description: |
Le _clustering_ consiste à répartir des observations dans des groupes,
généralement non observés,
en fonction de caractéristiques observables. Il s'agit d'une
application classique, en _machine learning_
de méthodes non supervisées puisqu'on ne dispose généralement pas de l'information
sur le groupe auquel appartient réellement une observation. Les applications
au monde réel sont nombreuses, notamment dans le domaine de la
segmentation tarifaire.
image: featured_clustering.png
bibliography: ../../reference.bib
echo: false
---
::: {.cell .markdown}
```{python}
#| echo: false
#| output: 'asis'
#| include: true
#| eval: true
import sys
sys.path.insert(1, '../../') #insert the utils module
from utils import print_badges
#print_badges(__file__)
print_badges("content/modelisation/5_clustering.qmd")
```
:::
{{< include _import_data_ml.qmd >}}
## Introduction sur le *clustering*
Jusqu'à présent, nous avons fait de l'apprentissage supervisé puisque nous
connaissions la vraie valeur de la variable à expliquer/prédire (`y`). Ce n'est plus le cas avec
l'apprentissage non supervisé.
Le *clustering* est un champ d'application de l'apprentissage non-supervisé.
Il s'agit d'exploiter l'information disponible en regroupant des observations
qui se ressemblent à partir de leurs caractéristiques (_features_) communes.
::: {.cell .markdown}
<details>
<summary>
Rappel: l'arbre de décision des méthodes `Scikit`
</summary>

</details>
:::
L'objectif est de créer des groupes d'observations (_clusters_) pour lesquels :
* Au sein de chaque cluster, les observations sont homogènes (variance intra-cluster minimale) ;
* Les clusters ont des profils hétérogènes, c'est-à-dire qu'ils se distinguent les uns des autres (variance inter-cluster maximale).
En *Machine Learning*, les méthodes de clustering sont très utilisées pour
faire de la recommandation. En faisant, par exemple, des classes homogènes de
consommateurs, il est plus facile d'identifier et cibler des comportements
propres à chaque classe de consommateurs.
Ces méthodes ont également un intérêt en économie et sciences sociales parce qu'elles permettent
de regrouper des observations sans *a priori* et ainsi interpréter une variable
d'intérêt à l'aune de ces résultats. Cette [publication sur la ségrégation spatiale utilisant des données de téléphonie mobile](https://www.insee.fr/fr/statistiques/4925200)
utilise par exemple cette approche.
Dans certaines bases de données, on peut se retrouver avec quelques exemples labellisés mais la plupart sont
non labellisés. Les labels ont par exemple été faits manuellement par des experts.
::: {.cell .markdown}
```{=html}
<div class="alert alert-info" role="alert">
<h3 class="alert-heading"><i class="fa-solid fa-comment"></i> Note</h3>
```
Les méthodes de *clustering* peuvent aussi intervenir en amont d'un problème de classification (dans des
problèmes d'apprentissage semi-supervisé).
Le manuel *Hands-on machine learning with scikit-learn, Keras et TensorFlow* [@geron2022hands] présente dans le
chapitre dédié à l'apprentissage non supervisé quelques exemples.
Par exemple, supposons que dans la [base MNIST des chiffres manuscrits](https://fr.wikipedia.org/wiki/Base_de_donn%C3%A9es_MNIST), les chiffres ne soient pas labellisés
et que l'on se demande quelle est la meilleure stratégie pour labelliser cette base.
On pourrait regarder des images de chiffres manuscrits au hasard de la base et les labelliser.
Les auteurs du livre montrent qu'il existe toutefois une meilleure stratégie.
Il vaut mieux appliquer un algorithme de clustering en amont pour regrouper les images ensemble et avoir une
image représentative par groupe, et labelliser ces images représentatives au lieu de labelliser au hasard.
```{=html}
</div>
```
:::
Les méthodes de *clustering* sont nombreuses.
Nous allons nous pencher sur la plus intuitive : les *k-means*.
## Les k-means
### Principe
L'objectif des *k-means* est de partitionner l'espace des observations en trouvant des points (*centroids*) jouant le rôle de centres de gravité pour lesquels les observations proches peuvent être regroupées dans une classe homogène.
L'algorithme *k-means* fonctionne par itération, en initialisant les centroïdes puis en les mettant à jour à chaque
itération, jusqu'à ce que les centroïdes se stabilisent. Quelques exemples de *clusters* issus de la méthode *k-means* :
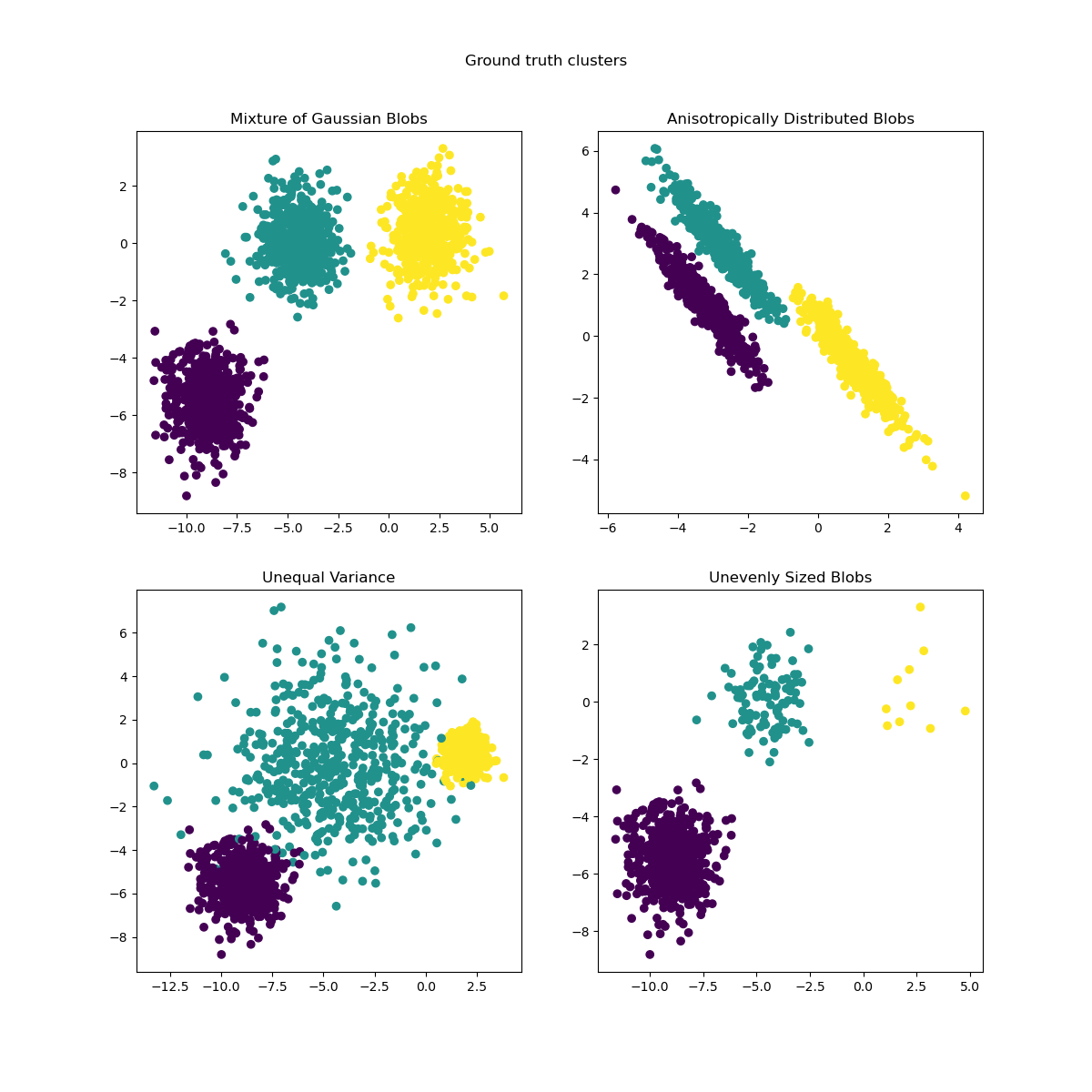
::: {.cell .markdown}
```{=html}
<div class="alert alert-warning" role="alert">
<h3 class="alert-heading"><i class="fa-solid fa-pencil"></i> Hint</h3>
```
L'objectif des *k-means* est de trouver une partition des données $S=\{S_1,...,S_K\}$ telle que
$$
\arg\min_{S} \sum_{i=1}^K \sum_{x \in S_i} ||x - \mu_i||^2
$$
avec $\mu_i$ la moyenne des $x_i$ dans l'ensemble de points $S_i$
```{=html}
</div>
```
:::
Dans ce chapitre nous allons principalement
utiliser `Scikit`. Voici néanmoins une proposition
d'imports de packages, pour gagner du temps.
```{python}
#| echo: true
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import geopandas as gpd
from sklearn.cluster import KMeans #pour kmeans
import seaborn as sns #pour scatterplots
```
::: {.cell .markdown}
```{=html}
<div class="alert alert-success" role="alert">
<h3 class="alert-heading"><i class="fa-solid fa-pencil"></i> Exercice 1 : Principe des k-means</h3>
```
1. Importer les données et se restreindre aux variables `'Unemployment_rate_2019', 'Median_Household_Income_2019', 'Percent of adults with less than a high school diploma, 2015-19', "Percent of adults with a bachelor's degree or higher, 2015-19"` et bien sûr `'per_gop'`. Appelez cette base restreinte `df2` et enlevez les valeurs manquantes.
2. Faire un *k-means* avec $k=4$.
3. Créer une variable `label` dans `votes` stockant le résultat de la typologie
4. Afficher cette typologie sur une carte.
5. Choisir les variables `Median_Household_Incomme_2019` et `Unemployment_rate_2019` et représenter le nuage de points en colorant différemment
en fonction du label obtenu.
6. Représenter la distribution du vote pour chaque *cluster*
```{=html}
</div>
```
:::
```{python}
#| output: false
# 1. Chargement de la base restreinte.
xvars = ['Unemployment_rate_2019', 'Median_Household_Income_2019',
'Percent of adults with less than a high school diploma, 2015-19',
"Percent of adults with a bachelor's degree or higher, 2015-19"]
df2 = votes[xvars + ["per_gop"]].dropna()
```
```{python}
#| output: false
#2. kmeans avec k=4
model = KMeans(n_clusters=4)
model.fit(df2[xvars])
```
```{python}
#| output: false
#3. Création de la variable label dans votes
votes['label'] = model.labels_
#votes['label'].head()
```
La carte obtenue à la question 4, qui permet de
représenter spatialement nos groupes, est
la suivante :
```{python}
#| output: false
#4. Carte de la typologie
p = votes.plot(column = "label", cmap = "inferno")
p.set_axis_off()
```
```{python}
p.get_figure()
```
Le nuage de point de la question 5, permettant de représenter
la relation entre `Median_Household_Income_2019`
et `Unemployment_rate_2019`, aura l'aspect suivant :
```{python}
#| output: false
#5. Nuage de points de 2 variables et coloration selon le label
plt.figure()
p = sns.scatterplot(
data=votes,
x="Median_Household_Income_2019",
y="Unemployment_rate_2019", hue = "label", palette="deep",
alpha = 0.4)
p.set(xscale="log")
```
```{python}
#| echo: false
p.figure.get_figure()
```
```{python}
#| output: false
p.figure.get_figure().savefig("featured_clustering.png")
```
Enfin, l'histogramme des votes pour chaque cluster est :
```{python}
#| output: false
# 6. Distribution du vote selon chaque cluster
plt.figure()
p2 = sns.displot(data=votes, x="per_gop", hue="label", alpha = 0.4)
```
```{python}
#| echo: false
p2.figure.get_figure()
```
::: {.cell .markdown}
```{=html}
<div class="alert alert-warning" role="alert">
<h3 class="alert-heading"><i class="fa-solid fa-pencil"></i> Hint</h3>
```
Il faut noter plusieurs points sur l'algorithme implémenté par défaut par `scikit-learn`, que l'on peut lire dans
la documentation :
- l'algorithme implémenté par défaut est kmeans ++ (cf. paramètre `init`). Cela signifie que
l'initialisation des centroïdes est faite de manière intelligente pour que les centroïdes initiaux soient choisis
afin de ne pas être trop proches.
- l'algorithme va être démarré avec `n_init` centroïdes différents et le modèle va choisir la meilleure initialisation
en fonction de l'_inertie_ du modèle, par défaut égale à 10.
Le modèle renvoie les `cluster_centers_`, les labels `labels_`, l'inertie `inertia_` et le nombre d'itérations
`n_iter_`.
```{=html}
</div>
```
:::
### Choisir le nombre de clusters
Le nombre de clusters est fixé par le modélisateur.
Il existe plusieurs façons de fixer ce nombre :
* connaissance a priori du problème ;
* analyse d'une métrique spécifique pour définir le nombre de clusters à choisir ;
* etc.
Il y a un arbitrage à faire
entre biais et variance :
un trop grand nombre de clusters implique une variance
intra-cluster très faible (sur-apprentissage, même s'il n'est jamais possible de déterminer
le vrai type d'une observation puisqu'on est en apprentissage non supervisé).
Sans connaissance a priori du nombre de clusters, on peut recourir à deux familles de méthodes :
* **La méthode du coude** (*elbow method*) : On prend le point d'inflexion de la courbe
de performance du modèle. Cela représente le moment où ajouter un cluster
(complexité croissante du modèle) n'apporte que des gains modérés dans la
modélisation des données.
* **Le score de silhouette** : On mesure la similarité entre un point et les autres points
du cluster par rapport aux autres clusters. Plus spécifiquement :
> Silhouette value is a measure of how similar an object is to its own cluster
> (cohesion) compared to other clusters (separation). The silhouette ranges
> from −1 to +1, where a high value indicates that the object is
> well matched to its own cluster and poorly matched to neighboring
> clusters. If most objects have a high value, then the clustering
> configuration is appropriate. If many points have a low or negative
> value, then the clustering configuration may have too many or too few clusters
>
> Source: [Wikipedia](https://en.wikipedia.org/wiki/Silhouette_(clustering))
Le score de silhouette d'une observation est donc égal à
`(m_nearest_cluster - m_intra_cluster)/max( m_nearest_cluster,m_intra_cluster)`
où `m_intra_cluster` est la moyenne des distances de l'observation aux observations du même cluster
et `m_nearest_cluster` est la moyenne des distances de l'observation aux observations du cluster le plus proche.
Le package `yellowbrick` fournit une extension utile à `scikit` pour représenter
facilement la performance en *clustering*.
```{python}
#| echo: true
#| output: false
from sklearn.cluster import KMeans
from yellowbrick.cluster import KElbowVisualizer
visualizer = KElbowVisualizer(model, k=(2,12))
visualizer.fit(df2[xvars]) # Fit the data to the visualizer
```
```{python}
#| echo: false
visualizer.show(outpath="elbow-yellowbrick.png") # Finalize and render the figure
```

Pour la méthode du coude, la courbe
de performance du modèle marque un coude léger à $k=4$. Le modèle initial
semblait donc approprié.
`yellowbrick` permet également de représenter des silhouettes mais
l'interprétation est moins aisée et le coût computationnel plus élevé :
```{python}
#| echo: true
#| output: false
from yellowbrick.cluster import SilhouetteVisualizer
fig, ax = plt.subplots(2, 2, figsize=(15,8))
j=0
for i in [3, 4, 6, 10]:
j += 1
'''
Create KMeans instance for different number of clusters
'''
km = KMeans(n_clusters=i, init='k-means++', n_init=10, max_iter=100, random_state=42)
q, mod = divmod(j, 2)
'''
Create SilhouetteVisualizer instance with KMeans instance
Fit the visualizer
'''
visualizer = SilhouetteVisualizer(km, colors='yellowbrick', ax=ax[q-1][mod])
ax[q-1][mod].set_title("k = " + str(i))
visualizer.fit(df2[xvars])
```
```{python}
#| output: false
fig.savefig("silhouette-yellowbrick.png")
```

Le score de silhouette offre une représentation plus riche que la courbe coudée.
Sur ce graphique, les barres verticales en rouge et en pointillé représentent le score de silhouette
global pour chaque `k` choisi. On voit par exemple que pour tous les `k` représentés ici, le
score de silhouette se situe entre 0.5 et 0.6 et varie peu.
Ensuite, pour un `k` donné, on va avoir la représentation des scores de silhouette de chaque
observation, regroupées par cluster.
Par exemple, pour `k = 4`, ici, on voit bien quatre couleurs différentes qui sont les 4 clusters modélisés.
Les ordonnées sont toutes les observations clusterisées et en abscisses on a le score de silhouette de
chaque observation. Si au sein d'un cluster, les observations ont un score de silhouette plus faible que le
score de silhouette global (ligne verticale en rouge), cela signifie que les observations du clusters sont
trop proches des autres clusters.
Grâce à cette représentation, on peut aussi se rendre compte de la taille relative des clusters. Par exemple,
avec `k = 3`, on voit qu'on a deux clusters conséquents et un plus "petit" cluster relativement aux deux autres.
Cela peut nous permettre de choisir des clusters de tailles homogènes ou non.
Enfin, quand le score de silhouette est négatif, cela signifie que la moyenne des distances de l'observation
aux observations du cluster le plus proche est inférieure à la moyenne des distances de l'observation aux
observations de son cluster. Cela signifie que l'observation est mal classée.
### Autres méthodes de clustering
Il existe de nombreuses autres méthodes de clustering. Parmi les plus connues, on peut citer trois exemples en particulier :
- Le clustering ascendant hiérarchique
- DBSCAN
- les mélanges de Gaussiennes
#### Clustering Ascendant Hiérarchique (CAH)
Quel est le principe ?
- On commence par calculer la dissimilarité entre nos _N_ individus, _i.e_. leur distance deux à deux dans l'espace de nos variables
- Puis on regroupe les deux individus dont le regroupement minimise un critère d'agrégation donné, créant ainsi une classe comprenant ces deux individus.
- On calcule ensuite la dissimilarité entre cette classe et les _N-2_ autres individus en utilisant le critère d'agrégation.
- Puis on regroupe les deux individus ou classes d'individus dont le regroupement minimise le critère d'agrégation.
- On continue ainsi jusqu'à ce que tous les individus soient regroupés.
Ces regroupements successifs produisent un arbre binaire de classification (dendrogramme), dont la racine correspond à la classe regroupant l'ensemble des individus. Ce dendrogramme représente une hiérarchie de partitions. On peut alors choisir une partition en tronquant l'arbre à un niveau donné, le niveau dépendant soit des contraintes de l'utilisateur, soit de critères plus objectifs.
Plus d'informations [ici](https://www.xlstat.com/fr/solutions/fonctionnalites/classification-ascendante-hierarchique-cah).
#### DBSCAN
L'[algorithme DBSCAN](https://fr.wikipedia.org/wiki/DBSCAN) est implémenté dans `sklearn.cluster`.
Il peut être utilisé pour faire de la détection d'anomalies
notamment.
En effet, cette méthode repose sur le clustering en régions où la densité
des observations est continue, grâce à la notion de voisinage selon une certaine distance epsilon.
Pour chaque observation, on va regarder si dans son voisinage selon une distance epsilon, il y a des voisins. S'il y a au
moins `min_samples` voisins, alors l'observation sera une *core instance*.
Les observations qui ne sont pas des *core instances* et qui n'en ont pas dans leur voisinage selon une distance espilon
vont être détectées comme des anomalies.
#### Les mélanges de gaussiennes
En ce qui concerne la théorie, voir le cours [Probabilités numériques et statistiques computationnelles, M1 Jussieu, V.Lemaire et T.Rebafka](https://perso.lpsm.paris/~rebafka/#enseignement)
Se référer notamment aux notebooks pour l'algorithme EM pour mélange gaussien.
Dans `sklearn`, les mélanges gaussiens sont implémentés dans `sklearn.mixture` comme `GaussianMixture`.
Les paramètres importants sont alors le nombre de gaussiennes `n_components` et le nombre d'initiatisations `n_init`.
Il est possible de faire de la détection d'anomalie savec les mélanges de gaussiennes.
::: {.cell .markdown}
```{=html}
<div class="alert alert-warning" role="alert">
<h3 class="alert-heading"><i class="fa-solid fa-pencil"></i> Pour aller plus loin</h3>
```
Il existe de nombreuses autres méthodes de clustering :
- Local outlier factor ;
- Bayesian gaussian mixture models ;
- D'autres méthodes de clustering hiérarchique ;
- etc.
```{=html}
</div>
```
:::
## L'Analyse en Composantes Principales
### Pour la visualisation de clusters
La méthode la plus simple pour visualiser les _clusters_, peu importe la méthode avec laquelles ils ont été obtenus, serait de représenter chaque individu dans l'espace à _N_ dimensions des variables de la table, et colorier chaque individu en fonction de son cluster.
On pourrait alors bien différencier les variables les plus discrimantes et les différents groupes.
Un seul problème ici : dès que _N > 3_, nous avons du mal à représenter le résultat de façon intelligible...
C'est là qu'intervient l'**Analyse en Composantes Principales** ([ACP](https://www.xlstat.com/fr/solutions/fonctionnalites/analyse-en-composantes-principales-acp)), qui permet de projeter notre espace à haute dimension dans un espace de dimension plus petite.
La contrainte majeure de la projection est de pouvoir conserver le maximum d'information (mesurée par la variance totale de l'ensemble de données) dans notre nombre réduit de dimensions, appelées composantes principales.
En se limitant à 2 ou 3 dimensions, on peut ainsi se représenter visuellement les relations entre les observations avec une perte de fiabilité minimale.
On peut généralement espérer que les clusters déterminés dans notre espace à N dimensions se différencient bien sur notre projection par ACP, et que la composition des composantes principales en fonction des variables initiales permette d'interpréter les clusters obtenus.
En effet, la combinaison linéaire des colonnes donnant naissance à nos nouveaux axes a souvent un "sens" dans le monde réel :
- Soit parce qu'une petite poignée de variables représente la majorité de la composante
- Soit parce que la plupart des colonnes intervenant dans la composante sommée se combinent bien pour former une interprétation naturelle.
Pour mettre en pratique les méthodes de création de clusters, de la base brute jusqu'à la visualisation par ACP, vous pouvez consulter la partie 2 du sujet 3 du funathon 2023, *Explorer les habitudes alimentaires de nos compatriotes*, sur le [SSP Cloud](https://www.sspcloud.fr/formation?search=funath&path=%5B%22Funathon%202023%22%5D) ou sur [Github](https://github.com/InseeFrLab/funathon2023_sujet3/).
### Pour la réduction de dimension
L'ACP est également très utile dans le champ de la réduction du nombre de variables pour de nombreux types de modélisations, comme par exemple les régressions linéaires.
Il est ainsi possible de projeter l'espace des variables explicatives dans un espace de dimension donnée plus faible, pour notamment limiter les risques d'overfitting.