-
Notifications
You must be signed in to change notification settings - Fork 45
/
index.qmd
1355 lines (1052 loc) · 39.9 KB
/
index.qmd
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
490
491
492
493
494
495
496
497
498
499
500
501
502
503
504
505
506
507
508
509
510
511
512
513
514
515
516
517
518
519
520
521
522
523
524
525
526
527
528
529
530
531
532
533
534
535
536
537
538
539
540
541
542
543
544
545
546
547
548
549
550
551
552
553
554
555
556
557
558
559
560
561
562
563
564
565
566
567
568
569
570
571
572
573
574
575
576
577
578
579
580
581
582
583
584
585
586
587
588
589
590
591
592
593
594
595
596
597
598
599
600
601
602
603
604
605
606
607
608
609
610
611
612
613
614
615
616
617
618
619
620
621
622
623
624
625
626
627
628
629
630
631
632
633
634
635
636
637
638
639
640
641
642
643
644
645
646
647
648
649
650
651
652
653
654
655
656
657
658
659
660
661
662
663
664
665
666
667
668
669
670
671
672
673
674
675
676
677
678
679
680
681
682
683
684
685
686
687
688
689
690
691
692
693
694
695
696
697
698
699
700
701
702
703
704
705
706
707
708
709
710
711
712
713
714
715
716
717
718
719
720
721
722
723
724
725
726
727
728
729
730
731
732
733
734
735
736
737
738
739
740
741
742
743
744
745
746
747
748
749
750
751
752
753
754
755
756
757
758
759
760
761
762
763
764
765
766
767
768
769
770
771
772
773
774
775
776
777
778
779
780
781
782
783
784
785
786
787
788
789
790
791
792
793
794
795
796
797
798
799
800
801
802
803
804
805
806
807
808
809
810
811
812
813
814
815
816
817
818
819
820
821
822
823
824
825
826
827
828
829
830
831
832
833
834
835
836
837
838
839
840
841
842
843
844
845
846
847
848
849
850
851
852
853
854
855
856
857
858
859
860
861
862
863
864
865
866
867
868
869
870
871
872
873
874
875
876
877
878
879
880
881
882
883
884
885
886
887
888
889
890
891
892
893
894
895
896
897
898
899
900
901
902
903
904
905
906
907
908
909
910
911
912
913
914
915
916
917
918
919
920
921
922
923
924
925
926
927
928
929
930
931
932
933
934
935
936
937
938
939
940
941
942
943
944
945
946
947
948
949
950
951
952
953
954
955
956
957
958
959
960
961
962
963
964
965
966
967
968
969
970
971
972
973
974
975
976
977
978
979
980
981
982
983
984
985
986
987
988
989
990
991
992
993
994
995
996
997
998
999
1000
---
title: "Les nouveaux modes d'accès aux données: le format parquet et les données sur le cloud"
date: 2022-08-28T15:00:00Z
draft: false
weight: 20
slug: readS3
type: book
tags:
- S3
- boto3
categories:
- Tutoriel
summary: |
Dans les entreprises et administrations, un nombre croissant
d'infrastructure se basent sur des _clouds_, qui sont des sessions
non persistentes où les données ne sont pas stockées dans les mêmes
serveurs que les machines qui exécutent du code. L'une des technologies
dominantes dans le domaine est un système de stockage nommé `S3`,
développé par [Amazon](https://docs.aws.amazon.com/fr_fr/AmazonS3/latest/userguide/Welcome.html).
`Python`, à travers plusieurs _packages_ (notamment `boto3`, `s3fs` ou `pyarrow`),
permet d'utiliser ce système de stockage distant comme si on
accédait à des fichiers depuis son poste personnel. Cette révolution est
étroitement associée à l'émergence du format de
données [`Apache Parquet`](https://parquet.apache.org/), format utilisable en
`Python` par le biais du package [`pyarrow`](https://arrow.apache.org/docs/python/index.html)
ou avec [`Spark`](https://spark.apache.org/) et présentant
de nombreux avantages pour l'analyse de données (vitesse d'import, possibilité de traiter
des données plus volumineuses que la RAM...)
eval: false
---
::: {.cell .markdown}
```{python}
#| echo: false
#| output: 'asis'
#| include: true
#| eval: true
import sys
sys.path.insert(1, '../../../../') #insert the utils module
from utils import print_badges
#print_badges(__file__)
print_badges("content/course/NLP/05a_s3.qmd")
```
:::
Ce chapitre est une introduction à la question
du stockage des données et aux innovations
récentes dans ce domaine. L'objectif
est d'abord de présenter les avantages
du format `Parquet` et la manière dont
on peut utiliser les
librairies [`pyarrow`](https://arrow.apache.org/docs/python/index.html)
ou [`duckdb`](https://duckdb.org/docs/api/python/overview.html) pour traiter
de manière efficace des données volumineuses
au format `Parquet`. Ensuite, on présentera
la manière dont ce format `parquet` s'intègre
bien avec des systèmes de stockage _cloud_,
qui tendent à devenir la norme dans le monde
de la _data science_.
# Elements de contexte
## Principe du stockage de la donnée
Pour comprendre les apports du format `Parquet`, il est nécessaire
de faire un détour pour comprendre la manière dont une information
est stockée et accessible à un langage de traitement de la donnée.
Il existe deux approches dans le monde du stockage de la donnée.
La première est celle de la __base de données relationnelle__. La seconde est le
principe du __fichier__.
La différence entre les deux est dans la manière dont l'accès aux
données est organisé.
## Les fichiers
Dans un fichier, les données sont organisées selon un certain format et
le logiciel de traitement de la donnée va aller chercher et structurer
l'information en fonction de ce format. Par exemple, dans un fichier
`.csv`, les différentes informations seront stockées au même niveau
avec un caractère pour les séparer (la virgule `,` dans les `.csv` anglosaxons, le point virgule dans les `.csv` français, la tabulation dans les `.tsv`). Le fichier suivant
```raw
nom ; profession
Astérix ;
Obélix ; Tailleur de menhir ;
Assurancetourix ; Barde
```
sera ainsi organisé naturellement sous forme tabulée par `Python`
```{python}
#| echo: false
#| eval: true
import pandas as pd
from io import StringIO
pd.read_csv(
StringIO(
"""
nom ; profession
Astérix ;
Obélix ; Tailleur de menhir
Assurancetourix ; Barde
"""
),
sep = ";"
)
```
A propos des fichiers de ce type, on parle de __fichiers plats__ car
les enregistrements relatifs à une observation sont stockés ensemble,
sans hiérarchie.
Certains formats de données vont permettre d'organiser les informations
de manière différente. Par exemple, le format `JSON` va
hiérarchiser différemment la même information [^1]:
```raw
[
{
"nom": "Astérix"
},
{
"nom": "Obélix",
"profession": "Tailleur de menhir"
},
{
"nom": "Assurancetourix",
"profession": "Barde"
}
]
```
::: {.cell .markdown}
```{=html}
<div class="alert alert-warning" role="alert">
<h3 class="alert-heading"><i class="fa-solid fa-lightbulb"></i> Hint </h3>
```
La différence entre le CSV et le format `JSON` va au-delà d'un simple "formattage" des données.
Par sa nature non tabulaire, le format JSON permet des mises à jour beaucoup plus facile de la donnée dans les entrepôts de données.
Par exemple, un site web qui collecte de nouvelles données n'aura pas à mettre à jour l'ensemble de ses enregistrements antérieurs
pour stocker la nouvelle donnée (par exemple pour indiquer que pour tel ou tel client cette donnée n'a pas été collectée)
mais pourra la stocker dans
un nouvel item. Ce sera à l'outil de requête (`Python` ou un autre outil)
de créer une relation entre les enregistrements stockés à des endroits
différents.
Ce type d'approche flexible est l'un des fondements de l'approche `NoSQL`,
sur laquelle nous allons revenir, qui a permis l'émergence de technologies au coeur de l'écosystème actuel du _big-data_ comme `Hadoop` ou `ElasticSearch`.
```{=html}
</div>
```
:::
Cette fois, quand on n'a pas d'information, on ne se retrouve pas avec nos deux séparateurs accolés (cf. la ligne _"Astérix"_) mais l'information
n'est tout simplement pas collectée.
::: {.cell .markdown}
```{=html}
<div class="alert alert-info" role="alert">
<h3 class="alert-heading"><i class="fa-solid fa-comment"></i> Note</h3>
```
Il se peut très bien que l'information sur une observation soit disséminée
dans plusieurs fichiers dont les formats diffèrent.
Par exemple, dans le domaine des données géographiques,
lorsqu'une donnée est disponible sous format de fichier(s), elle peut l'être de deux manières!
- Soit la donnée est stockée dans un seul fichier qui mélange contours géographiques et valeurs attributaires
(la valeur associée à cette observation géographique, par exemple le taux d'abstention). Ce principe est celui du `geojson`.
- Soit la donnée est stockée dans plusieurs fichiers qui sont spécialisés: un fichier va stocker les contours géographiques,
l'autre les données attributaires et d'autres fichiers des informations annexes (comme le système de projection). Ce principe est celui du `shapefile`.
C'est alors le logiciel qui requête
les données (`Python` par exemple) qui saura où aller chercher l'information
dans les différents fichiers et associer celle-ci de manière cohérente.
```{=html}
</div>
```
:::
Un concept supplémentaire dans le monde du fichier est celui du __file system__. Le _file system_ est
le système de localisation et de nommage des fichiers.
Pour simplifier, le _file system_ est la manière dont votre ordinateur saura
retrouver, dans son système de stockage, les bits présents dans tel ou tel fichier
appartenant à tel ou tel dossier.
## Les bases de données
La logique des bases de données est différente. Elle est plus systémique.
Un système de gestion de base de données (_Database Management System_)
est un logiciel qui gère à la fois le stockage d'un ensemble de données reliée,
permet de mettre à jour celle-ci (ajout ou suppression d'informations, modification
des caractéristiques d'une table...)
et qui gère également
les modalités d'accès à la donnée (type de requête, utilisateurs
ayant les droits en lecture ou en écriture...).
La relation entre les entités présentes dans une base de données
prend généralement la forme d'un __schéma en étoile__. Une base va centraliser
les informations disponibles qui seront ensuite détaillées dans des tables
dédiées.
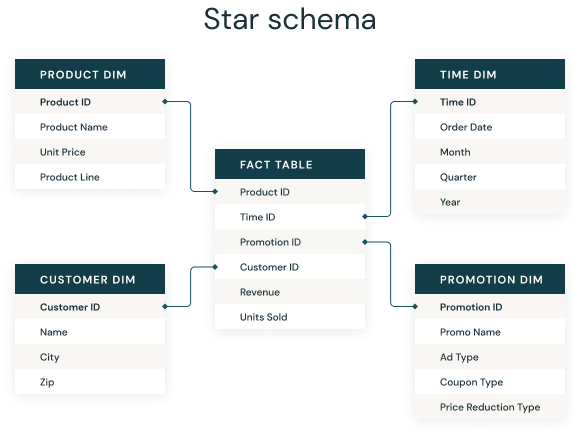
Source: [La documentation `Databricks` sur le schéma en étoile](https://www.databricks.com/fr/glossary/star-schema)
Le logiciel associé à la base de données fera ensuite le lien
entre ces tables à partir de requêtes `SQL`. L'un des logiciels les plus efficaces dans ce domaine
est [`PostgreSQL`](https://www.postgresql.org/). `Python` est tout à fait
utilisable pour passer une requête SQL à un gestionnaire de base de données.
Les packages [`sqlalchemy`](https://www.sqlalchemy.org/) et [`psycopg2`](https://www.psycopg.org/docs/)
peuvent servir à utiliser `PostgreSQL` pour requêter une
base de donnée ou la mettre à jour.
La logique de la base de données est donc très différente de celle du fichier.
Ces derniers sont beaucoup plus légers pour plusieurs raisons.
D'abord, parce qu'ils sont moins adhérents à
un logiciel gestionnaire. Là où le fichier ne nécessite, pour la gestion,
qu'un _file system_, installé par défaut sur
tout système d'exploitation, une base de données va nécessiter un
logiciel spécialisé. L'inconvénient de l'approche fichier, sous sa forme
standard, est qu'elle
ne permet pas une gestion fine des droits d'accès et amène généralement à une
duplication de la donnée pour éviter que la source initiale soit
ré-écrite (involontairement ou de manière intentionnelle par un utilisateur malveillant).
Résoudre ce problème est l'une des
innovations des systèmes _cloud_, sur lesquelles nous reviendrons en évoquant le
système `S3`.
Un deuxième inconvénient de l'approche base de données par
rapport à l'approche fichier, pour un utilisateur de `Python`,
est que les premiers nécessitent l'intermédiation du logiciel de gestion
de base de données là où, dans le second cas, on va se contenter d'une
librairie, donc un système beaucoup plus léger,
qui sait comment transformer la donnée brute en `DataFrame`.
Pour ces raisons, entre autres, les bases de données sont donc moins à la
mode dans l'écosystème récent de la _data-science_ que les fichiers.
# Le format `parquet`
Le format `CSV` a rencontré un grand succès par sa simplicité: il
est lisible par un humain (un bloc-note suffit pour l'ouvrir et
apercevoir les premières lignes), sa nature plate lui permet
de bien correspondre au concept de données tabulées sans hiérarchie
qui peuvent être rapidement valorisées, il est universel (il n'est
pas adhérent à un logiciel). Cependant, le CSV présente
plusieurs inconvénients qui justifient l'émergence d'un format
concurrent:
- le CSV est un format __lourd__ car les informations ne sont pas compressées
(ce qui le rend lisible facilement depuis un bloc-note) mais aussi
parce que toutes les données sont stockées de la même manière.
C'est la
librairie faisant l'import qui va essayer d'optimiser le typage des données
pour trouver le typage qui utilise le moins de mémoire possible sans
altération de l'information. En effet, si `pandas` détermine qu'une colonne
présente les valeurs `6 ; 5 ; 0`, il va privilégier l'utilisation du type
`int` au type `double` qui sera lui même préféré au type `object` (objets
de type données textuelles). Cependant, pour faire cela, `pandas` va devoir
scanner un nombre suffisant de valeurs, ce qui demande du temps et expose
à des erreurs (en se fondant sur trop peu de valeurs, on peut se tromper
de typage) ;
- le stockage étant __orienté ligne__,
accéder à une information donnée dans un `CSV` implique
de le lire le fichier en entier, sélectionner la ou les colonnes
d'intérêt et ensuite les lignes désirées. Par exemple, si on désire
connaître uniquement la profession de la deuxième ligne dans l'exemple
plus haut :point_up:, un algorithme de recherche devra:
prendre le fichier, déterminer que la profession est la deuxième colonne,
et ensuite aller chercher la deuxième ligne dans cette colonne. Si
on désire accéder à un sous-ensemble de lignes dont les indices
sont connus, le `CSV` est intéressant. Cependant,
si on désire accéder à un sous-ensemble
de colonnes dans un fichier (ce qui est un cas d'usage plus fréquent
pour les _data-scientists_), alors le `CSV` n'est pas le format le plus
approprié ;
- mettre à jour la donnée est coûteux car cela implique de réécrire
l'ensemble du fichier. Par exemple, si après une première
analyse de la donnée,
on désire ajouter une colonne, on ne peut accoler ces nouvelles informations
à celles déjà existantes, il est nécessaire de réécrire l'ensemble
du fichier. Pour reprendre l'exemple de nos gaulois préférés, si on veut
ajouter une colonne `cheveux` entre les deux déjà existantes,
il faudra changer totalement le fichier:
```raw
"""
nom ; cheveux ; profession
Astérix; blond; ;
Obélix; roux; Tailleur de menhir
Assurancetourix; blond; Barde
"""
```
::: {.cell .markdown}
```{=html}
<div class="alert alert-info" role="alert">
<h3 class="alert-heading"><i class="fa-solid fa-comment"></i> Note</h3>
```
La plupart des logiciels d'analyse de données proposent
un format de fichier pour sauvegarder des bases de données. On
peut citer le `.pickle` (`Python`), le `.rda` ou `.RData` (`R`),
le `.dta` (`Stata`) ou le `.sas7bdat` (`SAS`). L'utilisation
de ces formats est problématique car cela revient à se lier
les mains pour l'analyse ultérieure des données, surtout
lorsqu'il s'agit d'un format propriétaire (comme avec
`SAS` ou `Stata`). Par exemple, `Python` ne
sait pas nativement lire un `.sas7bdat`. Il existe des librairies
pour le faire (notamment `Pandas`) mais le format
étant propriétaire, les développeurs de la librairie ont dû tâtonner et
on n'est ainsi jamais assuré qu'il n'y ait pas d'altération de la donnée.
Malgré tous les inconvénients du `.csv` listés plus haut, il présente
l'immense avantage, par rapport à ces formats, de l'universalité.
Il vaut ainsi mieux privilégier un `.csv` à ces formats pour le stockage
de la donnée. Ceci dit, comme vise à le montrer ce chapitre, il vaut
mieux privilégier le format `parquet` au `CSV`.
```{=html}
</div>
```
:::
Pour répondre à ces limites du `CSV`, le format `parquet`,
qui est un [projet open-source `Apache`](https://apache.org/), a émergé.
La première différence entre le format `parquet` et le `CSV` est
que le premier repose sur un __stockage orienté colonne__ là où
le second est orienté ligne. Pour comprendre la différence, voici un
exemple issu du [blog d'upsolver](https://www.upsolver.com/blog/apache-parquet-why-use):
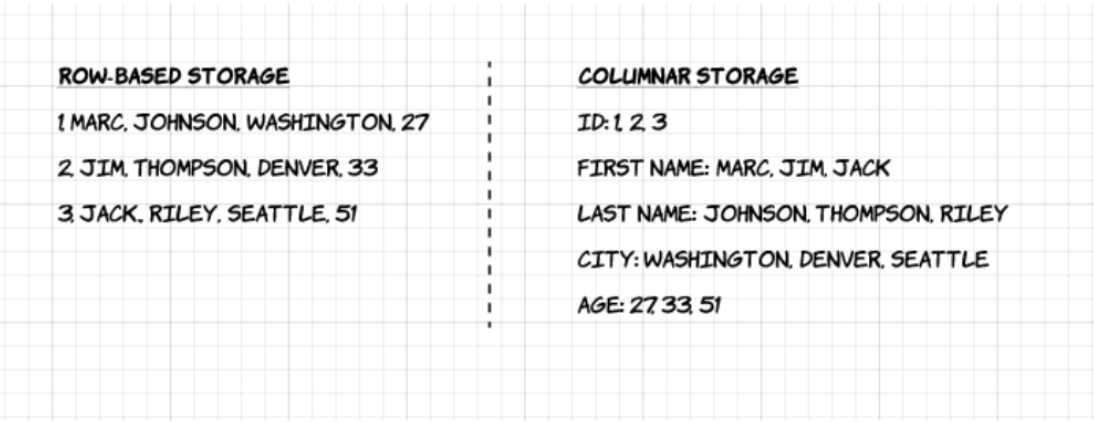
Dans notre exemple précédent, cela donnera une information prenant
la forme suivante (ignorez l'élément `pyarrow.Table`, nous
reviendrons dessus) :
```{python}
#| echo: false
#| eval: true
from pyarrow import csv
import io
s = """
nom ;profession
Astérix ;
Obélix ;Tailleur de menhir
Assurancetourix ;Barde
"""
source = io.BytesIO(s.encode())
df = csv.read_csv(source, parse_options = csv.ParseOptions(delimiter=";"))
df
```
Pour reprendre l'exemple fil rouge :point_up:, il sera ainsi beaucoup plus
facile de récupérer la deuxième ligne de la colonne `profession`:
on ne considère que le vecteur `profession` et on récupère la deuxième
valeur.
Le requêtage d'échantillon de données ne nécessite donc pas l'import de
l'ensemble des données. A cela s'ajoute des fonctionnalités supplémentaires
des librairies d'import de données parquet (par exemple `pyarrow` ou `spark`)
qui vont faciliter des recherches complexes basées, par exemple, sur des
requêtes de type `SQL`, ou permettant l'utilisation de données plus volumineuses que la RAM.
Le format `parquet` présente d'autres avantages par rapport au
`CSV`:
- Le format `parquet` est (très) compressé, ce qui réduit la volumétrie
des données sur disque ;
- Des métadonnées, notamment le typage des variables, sont stockées en complément dans le fichier.
Cette partie, nommée le _footer_ du fichier `parquet`, permet que l'import des données soit
optimisé sans risque d'altération de celle-ci. Pour un producteur de données, c'est une manière
d'assurer la qualité des données. Par exemple, un fournisseur de
données de type code-barre sera
certain que les données `000012` ne seront pas considérées identiques à un code-barre `12`.
- Il est possible de partitionner un jeu de données en fonction de différents niveaux (par
exemple des niveaux géographiques) en une arborescence de fichiers `parquet`. Cela
permet de travailler sur un échantillon pour facilement passer à l'échelle ensuite.
Par exemple, une structure partitionnée, empruntée
à la [documentation `Spark`](https://spark.apache.org/docs/latest/sql-data-sources-parquet.html#partition-discovery)
peut prendre la forme suivante:
```raw
path
└── to
└── table
├── gender=male
│ ├── ...
│ │
│ ├── country=US
│ │ └── data.parquet
│ ├── country=CN
│ │ └── data.parquet
│ └── ...
└── gender=female
├── ...
│
├── country=US
│ └── data.parquet
├── country=CN
│ └── data.parquet
└── ...
```
Qu'on lise un ou plusieurs fichiers, on finira avec le schéma suivant:
```raw
root
|-- name: string (nullable = true)
|-- age: long (nullable = true)
|-- gender: string (nullable = true)
|-- country: string (nullable = true)
```
Ces différents avantages expliquent le succès du format `parquet` dans le monde du
_big-data_. Le paragraphe suivant, extrait du [post d'upsolver]() déjà cité,
résume bien l'intérêt:
> Complex data such as logs and event streams would need to be represented as a table with hundreds or thousands of columns, and many millions of rows. Storing this table in a row based format such as CSV would mean:
>
> - Queries will take longer to run since more data needs to be scanned, rather than only querying the subset of columns we need to answer a query (which typically requires aggregating based on dimension or category)
> - Storage will be more costly since CSVs are not compressed as efficiently as Parquet
Cependant, **`Parquet` ne devrait pas intéresser que les producteurs ou utilisateurs de données _big-data_**.
C'est l'ensemble
des producteurs de données qui bénéficient des fonctionalités
de `Parquet`.
Pour en savoir plus sur `Arrow`,
des éléments supplémentaires sur `Parquet` sont disponibles sur ce très bon
post de blog d'[upsolver](https://www.upsolver.com/blog/apache-parquet-why-use)
et [sur la page officielle du projet `Parquet`](https://parquet.apache.org/).
## Lire un `parquet` en `Python`: la librairie `pyarrow`
La librairie `pyarrow` permet la lecture et l'écriture
de fichiers `parquet` avec `Python`[^3]. Elle repose
sur un type particulier de _dataframe_, le `pyarrow.Table`
qui peut être utilisé en substitut ou en complément
du `DataFrame`
de `pandas`. Il est recommandé de régulièrement
consulter la documentation officielle de `pyarrow`
concernant [la lecture et écriture de fichiers](https://arrow.apache.org/docs/python/parquet.html) et celle relative
aux [manipulations de données](https://arrow.apache.org/cookbook/py/data.html).
[^3]: Elle permet aussi la lecture et l'écriture
de `.csv`.
Pour illustrer les fonctionalités de `pyarrow`,
repartons de notre CSV initial que nous allons
enrichir d'une nouvelle variable numérique
et que nous
allons
convertir en objet `pyarrow` avant de l'écrire au format `parquet`:
```{python}
#| eval: true
import pandas as pd
from io import StringIO
import pyarrow as pa
import pyarrow.parquet as pq
s = """
nom;cheveux;profession
Astérix;blond;
Obélix;roux;Tailleur de menhir
Assurancetourix;blond;Barde
"""
source = StringIO(s)
df = pd.read_csv(source, sep = ";", index_col=False)
df["taille"] = [155, 190, 175]
table = pa.Table.from_pandas(df)
table
pq.write_table(table, 'example.parquet')
```
::: {.cell .markdown}
```{=html}
<div class="alert alert-warning" role="alert">
<h3 class="alert-heading"><i class="fa-solid fa-lightbulb"></i> Hint </h3>
```
L'utilisation des noms `pa` pour `pyarrow` et `pq` pour
`pyarrow.parquet` est une convention communautaire
qu'il est recommandé de suivre.
```{=html}
</div>
```
:::
Pour importer et traiter ces données, on peut conserver
les données sous le format `pyarrow.Table`
ou transformer en `pandas.DataFrame`. La deuxième
option est plus lente mais présente l'avantage
de permettre ensuite d'appliquer toutes les
manipulations offertes par l'écosystème
`pandas` qui est généralement mieux connu que
celui d'`Arrow`.
Supposons qu'on ne s'intéresse qu'à la taille et à la couleur
de cheveux de nos gaulois.
Il n'est pas nécessaire d'importer l'ensemble de la base, cela
ferait perdre du temps pour rien. On appelle
cette approche le __`column pruning`__ qui consiste à
ne parcourir, dans le fichier, que les colonnes qui nous
intéressent. Du fait du stockage orienté colonne du `parquet`,
il suffit de ne considérer que les blocs qui nous
intéressent (alors qu'avec un CSV il faudrait scanner tout
le fichier avant de pouvoir éliminer certaines colonnes).
Ce principe du `column pruning` se matérialise avec
l'argument `columns` dans `parquet`.
Ensuite, avec `pyarrow`, on pourra utiliser `pyarrow.compute` pour
effectuer des opérations directement sur une table
`Arrow` :
```{python}
#| eval: false
import pyarrow.compute as pc
table = pq.read_table('example.parquet', columns=['taille', 'cheveux'])
table.group_by("cheveux").aggregate([("taille", "mean")])
```
La manière équivalente de procéder en passant
par l'intermédiaire de `pandas` est
```{python}
#| eval: true
table = pq.read_table('example.parquet', columns=['taille', 'cheveux'])
table.to_pandas().groupby("cheveux")["taille"].mean()
```
Ici, comme les données sont peu volumineuses, deux des
avantages du `parquet` par rapport
au `CSV` (données moins
volumineuses et vitesse de l'import)
ne s'appliquent pas vraiment.
::: {.cell .markdown}
```{=html}
<div class="alert alert-info" role="alert">
<h3 class="alert-heading"><i class="fa-solid fa-comment"></i> Note</h3>
```
Un autre principe d'optimisation de la performance qui est
au coeur de la librairie `Arrow` est le `filter pushdown`
(ou `predicate pushdown`).
Quand on exécute un filtre de sélection de ligne
juste après avoir chargé un jeu de données,
`Arrow` va essayer de le mettre en oeuvre lors de l'étape de lecture
et non après. Autrement dit, `Arrow` va modifier le plan
d'exécution pour pousser le filtre en amont de la séquence d'exécution
afin de ne pas essayer de lire les lignes inutiles.
```{=html}
</div>
```
:::
# Le système de stockage `S3`
Si les fichiers `parquet` sont une
solution avantageuse pour
les _data-scientists_, ils ne résolvent
pas tous les inconvénients de
l'approche fichier.
En particulier, la question de la
duplication des données pour la mise
à disposition sécurisée des sources
n'est pas résolue. Pour que
l'utilisateur `B` n'altère pas les
données de l'utilisateur `A`, il est nécessaire
qu'ils travaillent sur deux fichiers
différents, dont l'un peut être une copie
de l'autre.
# Les données sur le _cloud_
La mise à disposition de données dans
les systèmes de stockage _cloud_ est
une réponse à ce problème.
Les _data lake_ qui se sont développés dans les
institutions et entreprises utilisatrices de données
Le principe d'un stockage cloud
est le même que celui d'une
`Dropbox` ou d'un `Drive` mais adapté à
l'analyse de données. Un utilisateur de données
accède à un fichier stocké sur un serveur distant
_comme s'il_ était dans son _file system_ local[^4].
Donc, du point de vue de l'utilisateur `Python`,
il n'y a pas de différence fondamentale. Cependant,
les données ne sont pas hebergées dans un dossier
local (par exemple `Mes Documents/monsuperfichier`)
mais sur un serveur distant auqgituel l'utilisateur
de `Python` accède à travers un échange réseau.

Dans l'univers du _cloud_, la hiérarchisation des données
dans des dossiers et des fichiers bien rangés
est d'ailleurs moins
importante que dans le monde du _file system_ local.
Lorsque vous essayez de retrouver un fichier dans
votre arborescence de fichiers, vous utilisez parfois
la barre de recherche de votre explorateur de fichiers,
avec des résultats mitigés[^4]. Dans le monde du _cloud_,
les fichiers sont parfois accumulés de manière plus
chaotique car les outils de recherche sont plus
efficaces[^4].
[^4]: D'ailleurs, les générations n'ayant connu nativement
que ce type de stockage ne sont pas familiarisées
au concept de _file system_ et préfèrent
payer le temps de recherche. Voir
[cet article](https://futurism.com/the-byte/gen-z-kids-file-systems)
sur le sujet.
En ce qui concerne la sécurité des données,
la gestion des droits de lecture et écriture peut être
fine: on peut autoriser certains utilisateurs uniquement
à la lecture, d'autres peuvent avoir les droits
d'écriture pour modifier les données. Cela permet
de concilier les avantages des bases de données (la sécurisation
des données) avec ceux des fichiers.
## Qu'est-ce que le système de stockage `S3` ?
Dans les entreprises et administrations,
un nombre croissant de données sont
disponibles depuis un système de stockage
nommé `S3`.
Le système `S3` (*Simple Storage System*) est un système de stockage développé
par Amazon et qui est maintenant devenu une référence pour le stockage en ligne.
Il s'agit d'une architecture à la fois
sécurisée (données cryptées, accès restreints) et performante.
Le concept central du système S3 est le __*bucket*__.
Un *bucket* est un espace (privé ou partagé) où on peut stocker une
arborescence de fichiers. Pour accéder aux fichiers figurant
dans un *bucket* privé, il faut des jetons d'accès (l'équivalent d'un mot de passe)
reconnus par le serveur de stockage. On peut alors lire et écrire dans le *bucket*.
::: {.cell .markdown}
```{=html}
<div class="alert alert-info" role="alert">
<h3 class="alert-heading"><i class="fa-solid fa-comment"></i> Note</h3>
```
Les exemples suivants seront réplicables pour les utilisateurs de la plateforme
SSP-cloud
```{python}
#| echo: false
#| output: 'asis'
#| include: true
#| eval: true
print_badges("content/course/NLP/05a_s3.qmd", onyxia_only=True)
```
Ils peuvent également l'être pour des utilisateurs ayant un
accès à AWS, il suffit de changer l'URL du `endpoint`
présenté ci-dessous.
```{=html}
</div>
```
:::
## Comment faire avec Python ?
### Les librairies principales
L'interaction entre ce système distant de fichiers et une session locale de Python
est possible grâce à des API. Les deux principales librairies sont les suivantes:
* [boto3](https://boto3.amazonaws.com/v1/documentation/api/latest/index.html), une librairie créée et maintenue par Amazon ;
* [s3fs](https://s3fs.readthedocs.io/en/latest/), une librairie qui permet d'interagir avec les fichiers stockés à l'instar d'un filesystem classique.
La librairie `pyarrow` que nous avons déjà présenté permet également
de traiter des données stockées sur le _cloud_ comme si elles
étaient sur le serveur local. C'est extrêmement pratique
et permet de fiabiliser la lecture ou l'écriture de fichiers
dans une architecture _cloud_.
Un exemple, assez court, est disponible
[dans la documentation officielle](https://arrow.apache.org/docs/python/filesystems.html#s3)
Il existe également d'autres librairies permettant de gérer
des _pipelines_ de données (chapitre à venir) de manière
quasi indifférente entre une architecture locale et une architecture
_cloud_. Parmi celles-ci, nous présenterons quelques exemples
avec `snakemake`.
En arrière-plan, `snakemake`
va utiliser `boto3` pour communiquer avec le système
de stockage.
Enfin, selon le même principe du _comme si_ les données
étaient en local, il existe l'outil en ligne de commande
`mc` ([`Minio Client`](https://docs.min.io/docs/minio-client-complete-guide.html)) qui permet de gérer par des lignes
de commande Linux les dépôts distants comme s'ils étaient
locaux.
Toutes ces librairies offrent la possibilité de se connecter depuis `Python`,
à un dépôt de fichiers distant, de lister les fichiers disponibles dans un
*bucket*, d'en télécharger un ou plusieurs ou de faire de l'*upload*
Nous allons présenter quelques unes des opérations les plus fréquentes,
en mode _cheatsheet_.
## Connexion à un bucket
Par la suite, on va utiliser des alias pour les trois valeurs suivantes, qui servent
à s'authentifier.
```python
key_id = 'MY_KEY_ID'
access_key = 'MY_ACCESS_KEY'
token = "MY_TOKEN"
```
Ces valeurs peuvent être également disponibles dans
les variables d'environnement de `Python`. Comme il s'agit d'une information
d'authentification personnelle, il ne faut pas stocker les vraies valeurs de ces
variables dans un projet, sous peine de partager des traits d'identité sans le
vouloir lors d'un partage de code.
::: {.cell .markdown}
```{=html}
<details><summary><code>boto3</code> 👇</summary>
```
Avec `boto3`, on créé d'abord un client puis on exécute des requêtes dessus.
Pour initialiser un client, il suffit, en supposant que l'url du dépôt S3 est
`"https://minio.lab.sspcloud.fr"`, de faire:
```python
import boto3
s3 = boto3.client("s3",endpoint_url = "https://minio.lab.sspcloud.fr")
```
```{=html}
</details>
```
:::
::: {.cell .markdown}
```{=html}
<details><summary><code>S3FS</code> 👇</summary>
```
La logique est identique avec `s3fs`.
Si on a des jetons d'accès à jour et dans les variables d'environnement
adéquates:
```python
import s3fs
fs = s3fs.S3FileSystem(
client_kwargs={'endpoint_url': 'https://minio.lab.sspcloud.fr'})
```
```{=html}
</details>
```
:::
::: {.cell .markdown}
```{=html}
<details><summary><code>Arrow</code> 👇</summary>
```
La logique d'`Arrow` est proche de celle de `s3fs`. Seuls les noms
d'arguments changent
Si on a des jetons d'accès à jour et dans les variables d'environnement
adéquates:
```python
from pyarrow import fs
s3 = fs.S3FileSystem(endpoint_override="http://"+"minio.lab.sspcloud.fr")
```
```{=html}
</details>
```
:::
::: {.cell .markdown}
```{=html}
<details><summary><code>Snakemake</code> 👇</summary>
```
La logique de `Snakemake` est, quant à elle,
plus proche de celle de `boto3`. Seuls les noms
d'arguments changent
Si on a des jetons d'accès à jour et dans les variables d'environnement
adéquates:
```python
from snakemake.remote.S3 import RemoteProvider as S3RemoteProvider
S3 = S3RemoteProvider(host = "https://" + os.getenv('AWS_S3_ENDPOINT'))
```
```{=html}
</details>
```
:::
Il se peut que la connexion à ce stade soit refusée (`HTTP error 403`).
Cela peut provenir
d'une erreur dans l'URL utilisé. Cependant, cela reflète plus généralement
des paramètres d'authentification erronés.
::: {.cell .markdown}
```{=html}
<details><summary><code>boto3</code> 👇</summary>
```
Les paramètres d'authentification sont des arguments supplémentaires:
```python
import boto3
s3 = boto3.client("s3",endpoint_url = "https://minio.lab.sspcloud.fr",
aws_access_key_id=key_id,
aws_secret_access_key=access_key,
aws_session_token = token)
```
```{=html}
</details>
```
:::
::: {.cell .markdown}
```{=html}
<details><summary><code>S3FS</code> 👇</summary>
```
La logique est la même, seuls les noms d'arguments diffèrent
```python
import s3fs
fs = s3fs.S3FileSystem(
client_kwargs={'endpoint_url': 'https://'+'minio.lab.sspcloud.fr'},
key = key_id, secret = access_key,
token = token)
```
```{=html}
</details>
```
:::
::: {.cell .markdown}
```{=html}
<details><summary><code>Arrow</code> 👇</summary>
```
Tout est en argument cette fois:
```python
from pyarrow import fs
s3 = fs.S3FileSystem(
access_key = key_id,
secret_key = access_key,
session_token = token,
endpoint_override = 'https://'+'minio.lab.sspcloud.fr',
scheme = "https"
)
```
```{=html}
</details>
```
:::
::: {.cell .markdown}
```{=html}
<details><summary><code>Snakemake</code> 👇</summary>
```
La logique est la même, seuls les noms d'arguments diffèrent
```python
from snakemake.remote.S3 import RemoteProvider as S3RemoteProvider
S3 = S3RemoteProvider(host = "https://" + os.getenv('AWS_S3_ENDPOINT'), access_key_id=key_id, secret_access_key=access_key)
```
```{=html}
</details>
```
:::
::: {.cell .markdown}
```{=html}
<div class="alert alert-info" role="alert">
<h3 class="alert-heading"><i class="fa-solid fa-comment"></i> Note</h3>
```
Dans le SSP-cloud,
lorsque l'initialisation du service `Jupyter` du SSP-cloud est récente
(moins de 12 heures), il est possible d'utiliser
automatiquement les jetons stockés automatiquement à la création du dépôt.
Si on désire accéder aux données du SSP-cloud depuis une session python du
datalab (service VSCode, Jupyter...),
il faut remplacer l'url par `http://minio.lab.sspcloud.fr`
```{=html}
</div>
```
:::
## Lister les fichiers
S'il n'y a pas d'erreur à ce stade, c'est que la connexion est bien effective.
Pour le vérifier, on peut essayer de faire la liste des fichiers disponibles
dans un `bucket` auquel on désire accéder.
Par exemple, on peut vouloir
tester l'accès aux bases `FILOSOFI` (données de revenu localisées disponibles
sur <https://www.insee.fr>) au sein du bucket `donnees-insee`.
::: {.cell .markdown}
```{=html}
<details><summary><code>boto3</code> 👇</summary>
```
Pour cela,
la méthode `list_objects` offre toutes les options nécessaires:
```python
for key in s3.list_objects(Bucket='donnees-insee', Prefix='FILOSOFI')['Contents']:
print(key['Key'])
```
```{=html}
</details>
```
:::
::: {.cell .markdown}
```{=html}
<details><summary><code>S3FS</code> 👇</summary>
```
Pour lister les fichiers, c'est la méthode `ls` (celle-ci ne liste pas par
défaut les fichiers de manière récursive comme `boto3`):
```{python, eval = FALSE}
fs.ls("donnees-insee")