-
Notifications
You must be signed in to change notification settings - Fork 45
/
03_data_analysis.qmd
357 lines (289 loc) · 17.9 KB
/
03_data_analysis.qmd
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
---
title: "Comment aborder un jeu de données"
date: 2020-07-22T12:00:00Z
draft: false
weight: 35
slug: datanalysis
type: book
bibliography: ../../reference.bib
description: |
Quelques éléments pour adopter une démarche
scientifique et éthique face à un
jeu de données.
image: panda_matrix.png
categories:
- Tutoriel
- Rappels
---
# Démarche à adopter face à un jeu de données
Pour bien débuter des travaux sur une base de données,
il est nécessaire de se poser quelques questions de bon sens
et de suivre une démarche assez simple.
## Une démarche scientifique
Dans un projet sur des jeux de données, on peut schématiquement
séparer les étapes en quatre grandes parties :
* la récupération et structuration des données;
* leur analyse (notamment descriptive) ;
* la modélisation ;
* la valorisation finale des étapes précédentes.
## Lors de la récupération des données
### Réflexions à mener en amont
La phase de constitution de son jeu de données sous-tend tout le projet qui suit.
La première question à se poser est
_"de quelles données ai-je besoin pour répondre à ma problématique ?"_.
Cette problématique pourra éventuellement
être affinée en fonction des besoins mais les travaux sont généralement
de meilleure qualité lorsque la problématique amène à la réflexion sur les données
disponibles plutôt que l'inverse.
Ensuite, _"qui produit et met à disposition ces données" ?_
_Les sources disponibles sur internet sont-elles fiables ?_
Par exemple, les sites d'_open data_ gouvernementaux sont par exemple assez fiables mais autorisent parfois l'archivage de données restructurées par des tiers et non des producteurs officiels. A l'inverse, sur `Kaggle` ou sur `Github` la source de certains jeux de données n'est pas tracée ce qui rend compliquée la confiance sur la qualité de la donnée
Une fois identifié une ou plusieurs sources de données,
_est-ce que je peux les compléter avec d'autres données ?_
(dans ce cas, faire attention à avoir des niveaux de granularité adéquats).
### Structuration des données
Vient ensuite la phase de mise en forme et nettoyage des jeux de données récupérés.
Cette étape est primordiale et est généralement celle qui mobilise le plus
de temps. Pendant quelques années, on parlait de _data-cleaning_. Cependant,
cela a pu, implicitement, laisser penser qu'il s'agissait d'une tâche
subalterne. On commence à lui préférer le concept de _feature engineering_
qui souligne bien qu'il s'agit d'une compétence qui nécessite beaucoup
de compétences.
Un jeu de données propre est un jeu de données dont la structure est
adéquate et n'entraînera pas d'erreur, visible ou non,
lors de la phase d'analyse. Voici quelques éléments structurants
d'un jeu de données propre:
- les __informations manquantes__ sont bien comprises et traitées. `numpy` et
`pandas` proposent un certain formalisme sur le sujet qu'il est utile
d'adopter en remplaçant par `NaN` les observations manquantes. Cela
implique de faire attention à la manière dont certains producteurs
codent les valeurs manquantes: certains ont la facheuse tendance à
être imaginatifs sur les codes pour valeurs manquantes: _"-999"_, _"XXX"_, _"NA"_
- les __variables servant d'identifiants__ sont bien les mêmes d'une table à l'autre (notamment dans le cas de jointure) : même format, même modalités
- pour des __variables textuelles__, qui peuvent etre mal saisies, avoir corrigé les éventuelles fautes (ex "Rolland Garros" > "Roland Garros")
- créer des variables qui synthétisent l'information dont vous avez besoin
- supprimer les éléments inutiles (colonne ou ligne vide)
- renommer les colonnes avec des noms compréhensibles
## Lors de l'analyse descriptive
Une fois les jeux de données nettoyés, vous pouvez plus sereinement
étudier l'information présente dans les données.
Cette phase et celle du nettoyage ne sont pas séquentielles,
en réalité vous devrez régulièrement passer de votre nettoyage à quelques statistiques descriptives qui vous montreront un problème, retourner au nettoyage etc.
Les questions à se poser pour _"challenger"_ le jeu de données :
- est-ce que mon échantillon est bien __représentatif__ de ce qui m'intéresse ? N'avoir que 2000 communes sur les 35000 n'est pas nécessairement un problème mais il est bon de s'être posé la question.
- est-ce que les __ordres de grandeur__ sont bons ? pour cela, confronter vos premieres stats desc à vos recherches internet. Par exemple trouver que les maisons vendues en France en 2020 font en moyenne 400 m² n'est pas un ordre de grandeur réaliste.
- est-ce que je __comprends toutes les variables__ de mon jeu de données ? est-ce qu'elles se "comportent" de la bonne façon ? à ce stade, il est parfois utile de se faire un dictionnaire de variable (qui explique comment elles sont construites ou calculées). On peut également mener des études de __corrélation__ entre nos variables.
- est-ce que j'ai des __outliers__, i.e. des valeurs aberrantes pour certains individus ? Dans ce cas, il faut décider quel traitement on leur apporte (les supprimer, appliquer une transformation logarithmique, les laisser tel quel) et surtout bien le justifier.
- est-ce que j'ai des __premiers grands messages__ sortis de mon jeu de données ? est-ce que j'ai des résultats surprenants ? Si oui, les ai-je creusé suffisamment pour voir si les résultats tiennent toujours ou si c'est à cause d'un souci dans la construction du jeu de données (mal nettoyées, mauvaise variable...)
## Lors de la modélisation
A cette étape, l'analyse descriptive doit voir avoir donné quelques premières pistes pour savoir dans quelle direction vous voulez mener votre modèle.
Une erreur de débutant est de se lancer directement dans la modélisation parce
qu'il s'agirait d'une compétence plus poussée. Cela amène généralement
à des analyses de pauvre qualité: la modélisation tend généralement à confirmer
les intuitions issues de l'analyse descriptive. Sans cette dernière,
l'interprétation des résultats d'un modèle peu s'avérer inutilement complexe.
Vous devrez plonger dans vos autres cours (Econométrie 1, Series Temporelles, Sondages, Analyse des données etc.) pour trouver le modèle le plus adapté à votre question.
La méthode sera guidée par l'objectif.
- Est-ce que vous voulez expliquer ou prédire ? https://hal-cnam.archives-ouvertes.fr/hal-02507348/document
- Est-ce que vous voulez classer un élément dans une catégorie (classification ou clustering) ou prédire une valeur numérique (régression) ?
En fonction des modèles que vous aurez déjà vu en cours et des questions que vous souhaiterez résoudre sur votre jeu de données, le choix du modèle sera souvent assez direct.
Vous pouvez également vous référez à la démarche proposée par Xavier Dupré
http://www.xavierdupre.fr/app/ensae_teaching_cs/helpsphinx3/debutermlprojet.html#l-debutermlprojet
Pour aller plus loin (mais de manière simplifiée) sur les algorithmes de Machine Learning :
https://datakeen.co/8-machine-learning-algorithms-explained-in-human-language/
### Valorisation des travaux
La mise à disposition de code sur `Github` ou `Gitlab` est une incitation
très forte pour produire du code de qualité. Il est ainsi recommandé de
systématiquement utiliser ces plateformes pour la mise à disposition de
code. Cependant, il ne s'agit que d'une petite partie des gains à
l'utiliser.
Le cours que je donne avec Romain Avouac en troisième année d'ENSAE
(https://ensae-reproductibilite.github.io/website/) évoque
l'un des principaux gains à utiliser ces plateformes, à savoir
la possibilité de mettre à disposition automatiquement différents livrables
pour valoriser son travail auprès de différents publics.
Selon le public visé, la communication ne sera pas identique. Le code peut
intéresser les personnes désirant avoir des détails sur la méthodologie mise
en oeuvre en pratique mais il peut s'agir d'un format rebutant pour d'autres
publics. Une visualisation de données dynamiques parlera à des publics
moins experts de la donnée mais est plus dure à mettre en oeuvre
qu'un graphique standard.
{{% box status="hint" title="Conseil" icon="fa fa-lightbulb" %}}
Les Notebooks `Jupyter` ont eu beaucoup de succès dans le monde de
la _data-science_ pour valoriser des travaux. Pourtant il ne s'agit
pas forcément toujours du meilleur format. En effet, beaucoup
de _notebooks_ tentent à empiler des pavés de code et du texte, ce
qui les rend difficilement lisibles.
Sur un projet conséquent, il vaut mieux reporter le plus de code
possible dans des scripts bien structurés et avoir un notebook
qui appelle ces scripts pour produire des outputs. Ou alors ne
pas utiliser un notebook et privilégier un autre format (un
tableau de bord, un site web, une appli réactive...)
{{% /box %}}
# Ethique et responsabilité du data-scientist
## La reproductibilité est importante
Les données sont une représentation synthétique de la vie des gens et les
conclusions de certaines analyses peuvent avoir un vrai impact sur
leur vie. Les chiffres erronés de
Reinhart et Rogoff ont ainsi pu servir de justification théorique à des
politiques d'austérité qui ont pu avoir des conséquences violentes
pour certains citoyens de
pays en crise[^4]. En Grande-Bretagne, le recensement des personnes
contaminées par le Covid en 2020, et donc de leurs proches pour le
suivi de l'épidémie,
a été incomplet à cause de
troncatures dues à l'utilisation d'un format non adapté de stockage
des données (tableur Excel)[^5].
Dernier exemple avec le _credit scoring_ mis en oeuvre aux Etats-Unis.
La citation ci-dessous, issue de l'article de @hurley2016credit,
illustre très bien les conséquences et les aspects problématiques
d'un système de construction automatisée d'un score de crédit :
> Consumers have limited ability to identify and contest unfair credit
decisions, and little chance to understand what steps they
should take to improve their credit. Recent studies have also
questioned the accuracy of the data used by these tools, in some
cases identifying serious flaws that have a substantial bearing
on lending decisions. Big-data tools may also risk creating a
system of _"creditworthinessby association"_ in which consumers'
familial, religious, social, and other affiliations determine their
eligibility for an affordable loan.
>
> @hurley2016credit
[^4]: Le livre de Reinhart et Rogoff, _This time is different_, s'appuyait
sur un Excel constitué à la main. Un doctorant s'est aperçu d'erreurs
dans celui-ci et a remarqué que lorsqu'on
substituait les chiffres officiels, les résultats n'étaient plus valides.
[^5]: Plus de détails sont disponibles dans la presse du moment, notamment
[cet article](https://www.lemondeinformatique.fr/actualites/lire-un-mauvais-usage-d-excel-evince-16-000-cas-positifs-covid-19-en-uk-80607.html) ou [celui-là](https://www.bbc.com/news/technology-54423988)
## Lutter contre les biais cognitifs
La transparence sur les intérêts et limites d'une méthode mise en oeuvre
est donc importante.
Cette exigence de la recherche, parfois oubliée à cause de la course
aux résultats novateurs, mérite également d'être appliquée
en entreprise ou administration.
Même sans intention manifeste de la part de la personne qui analyse des données,
une mauvaise interprétation est toujours possible. Tout en valorisant un
résultat, il est possible d'alerter sur certaines limites. Il est important,
dans ses recherches comme dans les discussions avec d'autres interlocuteurs,
de faire attention au biais de confirmation qui consiste
à ne retenir que l'information qui correspond à nos conceptions _a priori_ et
à ne pas considérer celles qui pourraient aller à l'encontre de celles-ci:

Certaines représentations de données sont à exclure car des biais cognitifs
peuvent amener à des interprétations erronées[^5]. Dans le domaine de la
visualisation de données, les camemberts (_pie chart_) ou les diagrammes
radar sont par exemple
à exclure car l'oeil humain perçoit mal ces formes circulaires. Pour une raison
similaire, les cartes avec aplat de couleur (cartes
choroplèthes) sont trompeuses.
[^5]: On suppose ici que le message erroné est transmis sans volonté de
manipulation. La manipulation manifeste est un problème encore plus grave.
## Réglementation
Le cadre réglementaire de protection des données a évolué ces dernières
années avec le RGPD. Cette réglementation a permis de mieux faire
saisir le fait que la collecte de données se justifie au nom
de finalités plus ou moins bien identifiées. Prendre conscience que
la confidentialité des données se justifie pour éviter la dissémination
non contrôlée d'informations sur une personne est important.
Des données particulièrement sensibles, notamment les données de santé,
peuvent être plus contraignantes à traiter que des données peu sensibles.
En Europe, par exemple, les agents du service statistique public
(Insee ou services statistiques ministériels) sont tenus au secret professionnel
(article L121-6 du Code général de la fonction publique),
qui leur interdit la communication des informations confidentielles
dont ils sont dépositaires au titre de leurs missions ou fonctions,
sous peine des sanctions prévues par l’article 226-13 du Code pénal
(jusqu’à un an d’emprisonnement et 15 000 € d’amende).
Le secret statistique, défini dans une loi de 1951,
renforce cette obligation dans le cas de données détenues pour des usages statistiques.
Il interdit strictement la communication de données individuelles
ou susceptibles d'identifier les personnes,
issues de traitements à finalités statistiques,
que ces traitements proviennent d’enquêtes ou de bases de données.
Le secret statistique exclut par principe de diffuser des données
qui permettraient l’identification des personnes concernées,
personnes physiques comme personnes morales.
Cette obligation limite la finesse des informations disponibles en diffusion
Ce cadre contraignant s'explique par l'héritage de la Seconde Guerre Mondiale
et le désir de ne plus revivre une situation où la collecte d'information
sert une action publique basée sur la discrimination entre catégories
de la population.
## Partager les moyens de reproduire une analyse
Un [article récent de `Nature`](https://www.nature.com/articles/d41586-022-01692-1),
qui reprend les travaux d'une équipe d'épidémiologistes [@gabelica2022many]
évoque le problème de l'accès aux données pour des chercheurs désirant reproduire
une étude. Même dans les articles scientifiques où il est mentionné que les
données peuvent être mises à disposition d'autres chercheurs, le partage
de celles-ci est rare :
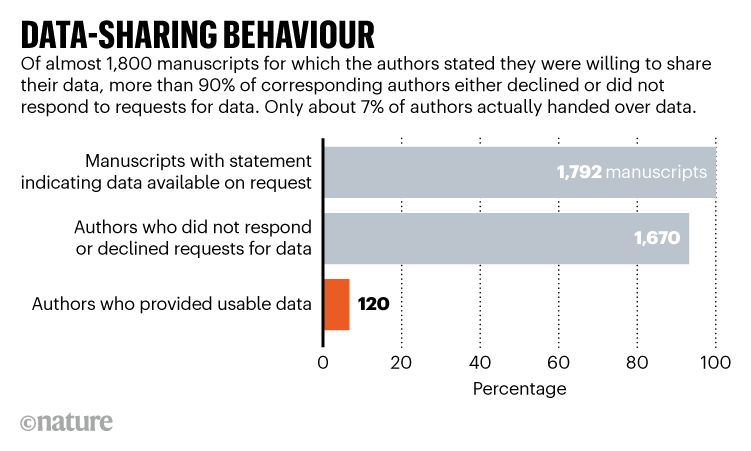
Graphique issu de l'article de _Nature_
Afin de partager les moyens de reproduire des publications sans diffuser des
données potentiellement confidentielles, les jeux de données synthétiques
sont de plus en plus utilisés. Par le biais de modèles de _deep learning_,
il est ainsi possible de générer des jeux de données synthétiques complexes
qui permettent de reproduire les principales caractéristiques d'un jeu de données
tout en évitant, si le modèle a été bien calibré, de diffuser une information
individuelle.
## Adopter une approche écologique
Le numérique constitue une part croissante des
émissions de gaz à effet de serre.
Représentant aujourd'hui 4 % des émissions mondiales
de CO2, cette part devrait encore croître [@arcep2019].
Le monde de la _data-science_ est également
concerné.
L'utilisation de données de plus en
plus massives, notamment la constitution
de corpus monumentaux de textes,
récupérés par scraping, est une première source
de dépense d'énergie. De même, la récupération
en continue de nouvelles traces numériques
nécessite d'avoir des serveurs fonctionnels
en continu. A cette première source de
dépense d'énergie, s'ajoute l'entraînement
des modèles qui peut prendre des jours,
y compris sur des architectures très
puissantes. @strubell2019energy
estime que l'entraînement d'un modèle à
l'état de l'art dans le domaine du
NLP nécessite autant d'énergie que ce que
consommeraient cinq voitures, en moyenne,
au cours de l'ensemble de leur
cycle de vie.
L'utilisation accrue de l'intégration
continue, qui permet de mettre en oeuvre de manière
automatisée l'exécution de certains scripts ou
la production de livrables en continu,
amène également à une dépense d'énergie importante.
Il convient donc d'essayer de limiter l'intégration
continue à la production d'output vraiment nouveaux.
Par exemple, cet ouvrage utilise de manière intensive
cette approche. Néanmoins, pour essayer de limiter
les effets pervers de la production en continu d'un
ouvrage extensif, seuls les chapitres modifiés
sont produits lors des prévisualisations mises en
oeuvre à chaque `pull request` sur le dépôt
{{< githubrepo >}}.
Les _data-scientists_ doivent être conscients
des implications de leur usage intensif de
ressources et essayer de minimiser leur
impact. Par exemple, plutôt que ré-estimer
un modèle de NLP,
la méthode de l'apprentissage par transfert,
qui permet de transférer les poids d'apprentissage
d'un modèle à une nouvelle source, permet
de réduire les besoins computationnels.
De même, il peut être utile, pour prendre
conscience de l'effet d'un code trop long,
de convertir le temps de calcul en
émissions de gaz à effet de serre.
Le package [codecarbon](https://codecarbon.io/)
propose cette solution en adaptant l'estimation
en fonction du mix énergétique du pays
en question. Mesurer étant le
prérequis pour prendre conscience puis comprendre,
ce type d'initiatives peut amener à responsabiliser
les _data-scientists_ et ainsi permettre un
meilleur partage des ressources.
# Références
::: {#refs}
:::