
Fastidious is a Python parsing expression grammar (PEG) parser generator.
Fastidious is also a PEG parser compiler. The compiler is used internally to generate parsers, but is also exposed to allow the user to create their own outputs from the grammar. One could for example generate the code of a parser in another language than python.
Fastidious aims to be a PEG parser design framework. Some useful helpers are planned:
- complex rule actions
- automatic AST nodes generation
- auto-generated unit test class
- ...
- Full PEG grammar, with some syntaxic sugar
- Reasonably fast for a python parser
- Can generate standalone code, no need to import fastidious to use a parser
- Parsing error reporting, with position and expected token hint
From the calculator example.
To read the example, think regex, except that the OR spells /, that
literal chars are in quotes and that we can reference other rules.
#! /usr/bin/env python
from fastidious import Parser
class Calculator(Parser):
# __grammar__ is the PEG definition. Each `rulename <- a rule`
# adds a method `Calculator.rulename()`. This methods tries to
# match the input at current position
__grammar__ = r"""
# the label is ommited. `:expr` is equivalent to `expr:expr`
eval <- :expr EOF {@expr}
# action {on_expr} calls `Calculator.on_expr(self, value, first, rest)`
# on match. `first` and `rest` args are the labeled parts of the rule
term <- first:factor rest:( _ mult_op _ factor )* {on_expr}
# Because the Parser has a method named `on_expr` ("on_" + rulename)
# this method is the implicit action of this rule. We omitted {on_expr}
expr <- _ first:term rest:( _ add_op _ term )* _
# there's no explicit or implicit action. These rules return their exact
# matches
add_op <- '+' / '-'
mult_op <- '*' / '/'
# action {@fact} means : return only the match of part labeled `fact`.
factor <- ( '(' fact:expr ')' ) / fact:integer {@fact}
integer <- '-'? [0-9]+
_ <- [ \n\t\r]*
# this one is tricky. `.` means "any char". At EOF there's no char,
# thus Not any char, thus `!.`
EOF <- !.
"""
def on_expr(self, value, first, rest):
result = first
for r in rest:
op = r[1]
if op == '+':
result += r[3]
elif op == '-':
result -= r[3]
elif op == '*':
result *= r[3]
else:
result /= r[3]
return result
def on_integer(self, value):
return int(self.p_flatten(value))
if __name__ == "__main__":
import sys
c = Calculator("".join(sys.argv[1:]))
result = c.eval()
# because eval is the first rule defined in the grammar, it's the default rule.
# We could call the classmethod `p_parse`:
# result = Calculator.p_parse("".join(sys.argv[1:]))
# The default entry point can be overriden setting the class attribute
# `__default__`
print(result)Then you have a full-fledge state-of-the-art integer only calculator o/
examples/calculator.py "-21 * ( 3 + 1 ) / -2"
42Fastidious can generate the code of a standalone parser with only a
dependency on six. Given a parser that you had carefully designed,
debug and tested with fastidious, you may want to ship it in your
project without keeping the dependency on fastidious itself.
python -m fastidious examples.calculator.Calculator -e > mycalc.py
chmod +x mycalc.py
mycalc.py 2 + 1A parser can inherit rules. Here's an example from fastidious tests:
class Parent(Parser):
__grammar__ = r"""
some_as <- 'a'+
"""
class Child(Parent):
__grammar__ = r"""
letters <- some_as some_bs EOF {p_flatten}
some_bs <- 'b'+
EOF <- !.
"""
assert(Child.p_parse("aabb") == "aabb")Here, Child has inherited the method the rule some_as.
Rules can also be overridden in child parsers.
Note that there's no overhead in inheritance at parsing as the rules from the parent are copied into the child.
I plan to add a set of reusable rules in fastidious.contrib to compose your
parsers.
At the moment, there's only URLParser, that provides a rule that match URLs and
outputs an urlparse.ParseResult on match.
Please send a pull request if you made an interesting piece of code :)
Fastidious can also generate a nice graphical view of a grammar with graphiz
python -m fastidious graph examples.calculator.Calculator | dot -Tpng > doc/images/calculator.png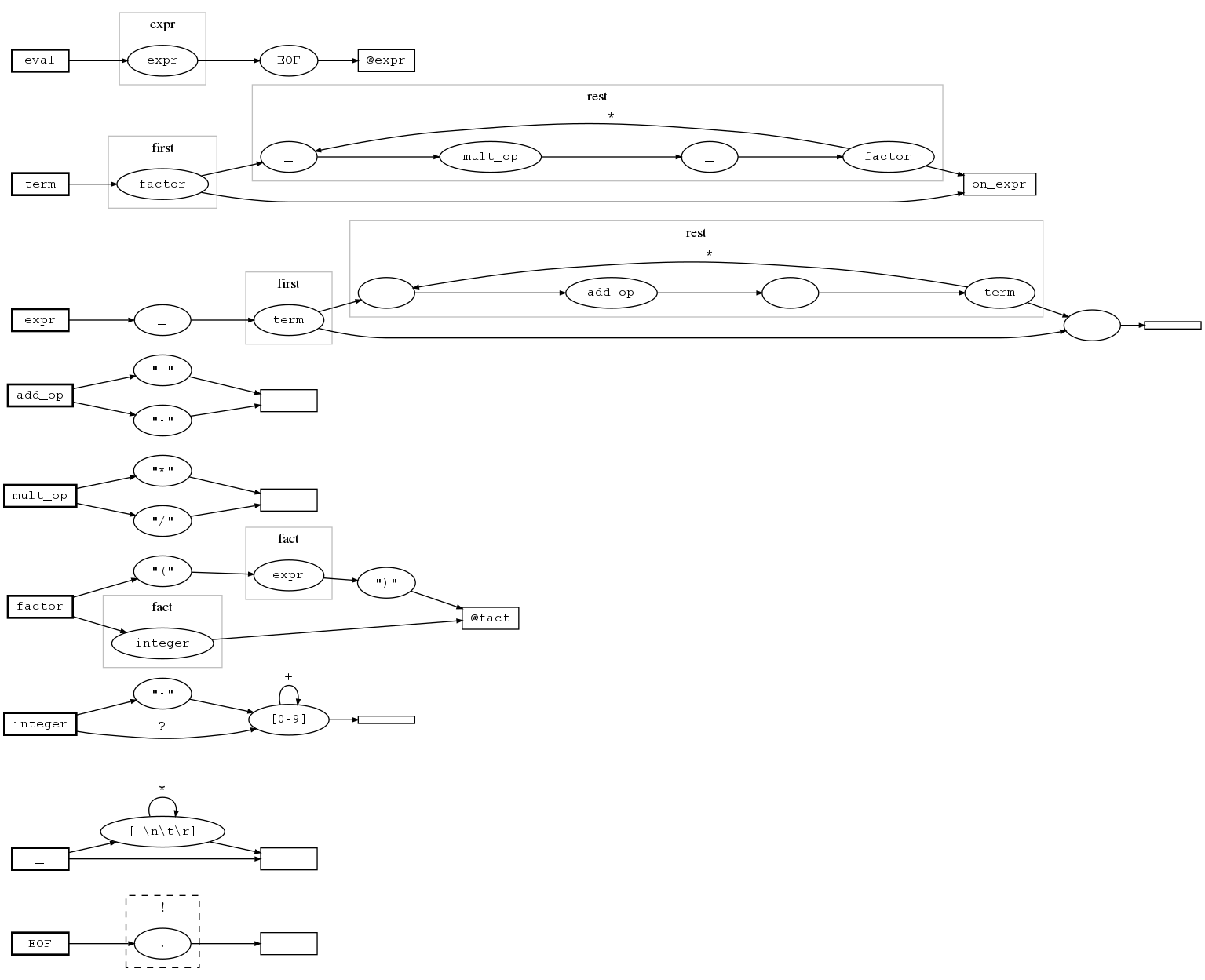
Fastidious generates an AST of the grammar. Then by successive passes of AST transforms, it generate python code that is complied and added to the class at runtime.
This design has many advantages:
- It's trivial to implement user preferences and tweaks on the generated code
- It's easy to add features and optimisations. For example, the ratpack optimisation (memeoization) is implemented as a pass in the compiler. It's ~50 LoC of a simple visitor that adds the memoization code to the generated code.
- The new pass can be toggled in tests to check correctness and to measure the optimisation gains (I can prove that memoized code is 30% faster)
The user can force their own compilers on a parser class definition. The compiler code is stil messy, and undocumented though.
- Fastidious grammar used to be loosely based on Pigeon<https://github.com/PuerkitoBio/pigeon>_
- It has diverged a lot since then.
- However, most of the PEG documentation below is a shameless copy of Pigeon doc
- Parsimonious<https://github.com/erikrose/parsimonious>_ is another python PEG
parser generator.
- Parsimonious was designed for speed and low memory usage. I guess it's a good reference for Fastidious benchmarks. Fastidious seems faster on small inputs (<100kB). Both parsers slow down as the size of the input grows. Fastidious eventually become slower than Parsimonious
- Well, it's just stupid benchmarks, never trust them, just try with your own workload.
- Anyway, I'm quite upset I didn't find Parsimonious' name first, I'll do my best to be faster, as a revenge :-)
The whole syntax is formally defined in fastidious parser class, using the PEG syntax (which is actually used to generate the fastidious parser itself, so it's THE TRUTH. Yes, I like meta-stuff). What follows is an informal and rather incomplete description of this syntax.
Identifiers, whitespace, comments and literals follow a subset of python notation:
# a comment 'a string literal' "a more \"complex\" one with a litteral '\\' \nand a second line" _aN_iden7ifi3r
Identifiers MUST be valid python identifiers as they are added as methods on the parser objects. Parsers have utility methods that are prefixed by p_ and _p_. Please avoid these names.
A PEG grammar consists of a set of rules. A rule is an identifier followed by a
rule definition operator <- and an expression. An optional display name - a
string literal used in error messages instead of the rule identifier - can be
specified after the rule identifier. An action can also be specified enclosed in
{} after the rule, more on this later.
rule_a "friendly name" <- 'a'+ {an_action} # one or more lowercase 'a's
Actions are a way to alter the output of a rule. Without actions the rules emit strings, lists of strings, or a list of lists and strings.
Action are useful to control the output. One could for example instantiate AST nodes, or, as we do in the JSON example, our result string, lists and dicts.
Actions can also be used to reduce the result as the input is parsed, that's
exactly what we do in the calculator example in the method on_expr.
There are two kind of actions: labels and methods
If an expression has a label, you can use it as the return value. In the calculator, we use:
factor <- ( '(' fact:expr ')' ) / fact:integer {@fact}
Here, @fact means 'return the part labeled fact' which is an integer literal
or the result of an expr enclosed in parentheses, depending on the branch that
matches.
All the rest (e.g the parentheses) of the match is never output and is lost.
Method actions are methods on the parser. In the calculator, there's:
term <- first:factor rest:( _ mult_op _ factor )* {on_expr}
This means that on match, the method of the parser named on_expr is called
with one positional argument: value and two keyword arguments: first and
rest named after the labels in the expression.
value is the full value of the match, something like:
[ 2 [ " ", "*", "", 3]]
first would be 2 and rest would be [ " ", "*", "", 3].
I hope the indices of r in this method make sense, now:
def on_expr(self, value, first, rest):
result = first
for r in rest:
op = r[1]
if op == '+':
result += r[3]
elif op == '-':
result -= r[3]
elif op == '*':
result *= r[3]
else:
result /= r[3]
return resultNote that even though the rule _ has the Kleen star * it will at least
return an empty string, so rest is guaranteed to be a 4 elements list.
Because of its name, on_expr is also the implicit action of the rule expr.
This can of course be overridden by adding an explicit action on the rule
At the moment, there's one builtin action {{p_flatten}} that recursively
concatenates a list of lists and strings:
["a", ["b", ["c", "d"], "e"], "fg"] => "abcdefg"
A rule is defined by an expression. The following sections describe the various expression types. Expressions can be grouped by using parentheses, and a rule can be referenced by its identifier in place of an expression.
The choice expression is a list of expressions that will be tested in the order they are defined. The first one that matches will be used. Expressions are separated by the forward slash character "/". E.g.:
choice_expr <- A / B / C # A, B and C should be rules declared in the grammar
Because the first match is used, it is important to think about the order of expressions. For example, in this rule, "<=" would never be used because the "<" expression comes first:
bad_choice_expr <- "<" / "<="
The sequence expression is a list of expressions that must all match in that same order for the sequence expression to be considered a match. Expressions are separated by whitespace. E.g.:
seq_expr <- "A" "b" "c" # matches "Abc", but not "Acb"
A labeled expression consists of an identifier followed by a colon ":" and an expression. A labeled expression introduces a variable named with the label that can be referenced in the action of the rule. The variable will have the value of the expression that follows the colon. E.g.:
labeled_expr <- value:[a-z]+ "a suffix" {@value}
If this sequence matches, the rule returns only the [a-z]+ part instead of
["thevalue", "a suffix"]
An expression prefixed with the exclamation point ! is the "not" predicate
expression: it is considered a match if the following expression is not a
match, but it does not consume any input.
An expression prefixed with the ampersand & is the "and" predicate
expression: it is considered a match if the following expression is a match,
but it does not consume any input.
& doesn't exist in pure PEG grammar theory, and is sugar for !!
not_expr <- "A" !"B" # matches "A" if not followed by a "B" (does not consume "B") and_expr <- "A" &"B" # matches "A" if followed by a "B" (does not consume "B")
An expression followed by "*", "?" or "+" is a match if the expression occurs zero or more times ("*"), zero or one time "?" or one or more times ("+") respectively. The match is greedy, it will match as many times as possible. E.g:
zero_or_more_as <- "A"*
A literal matcher tries to match the input against a single character or a string literal. The literal may be a single-quoted or double-quoted string. The same rules as Python apply regarding allowed characters and escaping.
The literal may be followed by a lowercase i (outside the ending quote)
to indicate that the match is case-insensitive. E.g.:
literal_match <- "Awesome\n"i # matches "awesome" followed by a newline
A character class matcher tries to match the input against a class of
characters inside square brackets [...]. Inside the brackets, characters
represent themselves and the same escapes as in string literals are available,
except that the single- and double-quote escape is not valid, instead the
closing square bracket ] must be escaped to be used.
Character ranges can be specified using the [a-z] notation. Unicode chars are
not supported yet.
As for string literals, a lowercase i may follow the matcher (outside the
ending square bracket) to indicate that the match is case-insensitive. A ^ as
first character inside the square brackets indicates that the match is inverted
(it is a match if the input does not match the character class matcher). E.g.:
not_az <- [^a-z]i
The any matcher is represented by the dot .. It matches any character except
the end of file, thus the !. expression is used to indicate "match the end of
file". E.g.:
any_char <- . # match a single character EOF <- !.
Although not in the formal definition of PEG parsers, regex may be handy (OR NOT!)
and may provide substantial performance improvements. A regex expression is
defined in a single- or double-quoted string prefixed by a ~.
Flags "iLmsux" as described in python re module can follow the pattern. E.g.:
re_match <- ~"https?://[\\S:@/]*"i # DON'T TRY THIS ONE, it's just a silly example
PEG parsers design makes automatic syntax error reporting hard. The parser has to follow every possible path from the root and fail to parse the document before it can tell there's a syntax error. It's even harder to tell where is the error, because at this point, we only know that every path has fail.
However this paper http://arxiv.org/pdf/1405.6646v1.pdf suggest a bunch of techniques to improve syntax error detection, we implemented some of them and, by experience, it's satisfying (i.e: I can debug my errors using fastidious messages).
- make a tool to generate standalone modules
- more tests