“所有类实例同时帧更新,以模拟一系列相互独立的对象。”
没错,就是你在游戏编程中常见的Update()或Tick()方法,这可能是在游戏开发中最常见的模式了,常见到一直以来我并不认为它算得上是一种模式。
新加入的对象通常不应该在本帧更新,原因至少包括两点:一是因为此时玩家尚未看到这个物品,二是更新该对象有可能进一步导致创建或销毁新的对象。如果你不希望这样的情况发生,一个简单的办法就是在遍历之前存储当前对象列表的长度,而这一次的循环仅更新列表前面这么多的对象。
更令人担忧的问题是遍历时移除对象,这有可能会导致某些对象在本帧被跳过而不被更新。比如下面这个例子:你希望在循环中移除一只foul beast,而它碰巧位于你当前所更新的对象的前面,这可能会让你不小心跳过一个对象(helpless peasant)。
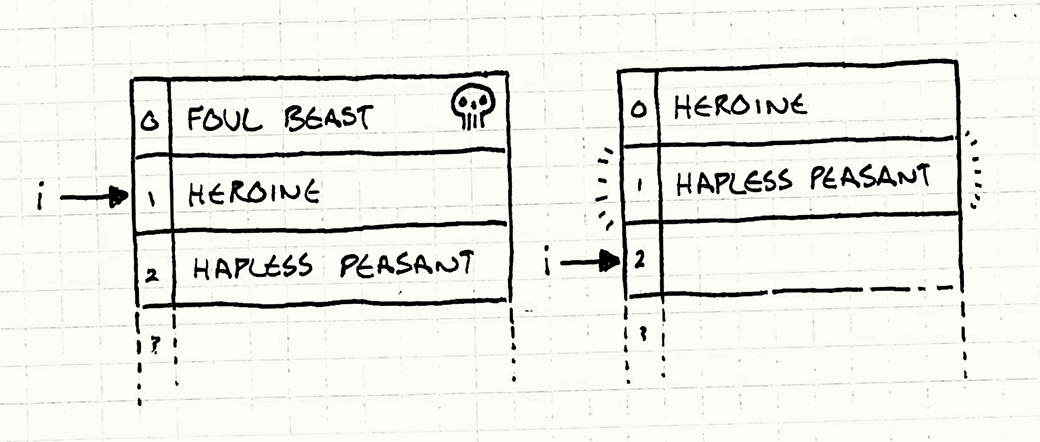
一个修补方案是把remove对象这件事情出计算在内,精确控制迭代器的指向,注意此时可以同时需要调整前面临时存储的遍历对象的个数,以防止更新到新add的对象,或者列表下标溢出;另一个方案是将移除操作推迟到本次循环遍历结束之后。将要被移除的对象标记为�dead,但并不从列表中移除它,在更新期间,确保跳过那些被标记为dead的对象,接着等到遍历更新结束后,再遍历列表来移除这些“尸体”。
另外需要注意的是:新加入的对象通常可以被GetItem(id)的方式索引到,但被标记为dead的对象通常就不应该被索引到了,所以你有可能需要对此做一些区分。
在游戏中,所有对象都在每帧进行模拟,但这并非真正同步,而是存在了先后顺序。游戏循环在每帧遍历对象并逐个更新它们,在Update()的调用中,多数对象能够访问到游戏世界的其它部分,包括那些正在更新的其它对象,这意味着,游戏循环更新对象的顺序意义重大。
Hashtable设计的主要目标是根据key值快速的index/add/remove对象,这些操作的平均时间复杂度都是O(1)的。Hashtable的设计理念决定了它在存储上存在着随机的成分,因此当Hashtable容量发生变化的时候,其遍历顺序很可能发生变化。
如果基于Hashtable容器进行对象更新,并且中间恰好发生了add/remove操作,那么将产生几个很难解决的问题:
- 如何标记新加入的对象,这些对象在本帧中不需要更新。
- 如果标记某些对象在本帧已经更新过了,从而在Hashtable遍历顺序发生变化的时候,再次遇到同一个对象时不应该重复更新它。
因此,基于遍历顺序不稳定的Hashtable进行对象更新可能会引入不易重现的bug。一个可能的解决方案是使用两个单独的table分别记录新加入的和被移除的对象,并在Update()结束的时候基于这两个table的数据重新组织你的主对象Hashtable。但这也带来了新的问题:你需要在所有可能用到主对象Hashtable的小心的维护三张table之间的关系,比如GetItem(), AddItem(), RemoveItem()等等所有这些可能在遍历过程被调用到方法。
另外,Hash table的遍历速度通常较慢,可能只有array的几分之一,下表是Unit3d中实测C#各容器的遍历开销对比,测试环境为Mac电脑:
| 函数 | 遍历类型 | cpu开销 | gc开销 |
|---|---|---|---|
| SortedTable | Pair | 6 | 0 |
| Values | 2 | 0 | |
| Values[i] | 1 | 0 | |
| Dictionary | Pair | 7 | 0 |
| Values | 8 | 12B | |
| Hashable | Pair | 4 | 36B |
| Values | 3 | 36B | |
| SortedDictionary | Pair | 18 | 100B |
| Values | 13 | 112B |
一个可以考虑的方案是使用在自定义容器中使用数组快照,比如SortedTable,这是一个基于array+二分查找的映射表,原理与C#中内置的SortedDictionary相同。基本思路是在每次Update()时,先使用内置Array.Copy()获取一个当前对象列表的数组快照,然后遍历这个数组,其实是这是双缓冲模式的一个变种。
测试环境:红米Note3,Unity 2017.1.0f3,Lua jit 5.1,对象列表长度为8192
C#测试结果为:
| 遍历类型(C#) | cpu开销 | 描述 |
|---|---|---|
| object[] | 1 | 基准类型,原始数组 |
| 数组快照 | 1.1 | Array.Copy(object[], snapshot[], size) |
| 数组拷贝 | 10.5 | 通过for循环遍历原始数组,复制数据到snapshot[]中,然后再遍历snapshot[] |
| List<object> | 4 | 使用for循环,无gcalloc |
| SortedTable<int, object> | 2.5 | 基于 array&二分查找 的自定义表,使用Array.Copy()复制数据,比List要快 |
| Dictionary<int, object> | 10 | 采用while(iter.MoveNext()) |
| Dictionary快照 | 20 | dict.Values.CopyTo(snapshot[]) |
Lua测试结果为:
| 遍历类型(lua) | cpu开销 | 描述 |
|---|---|---|
| table | 1 | 基准类型,原始table |
| table拷贝 | 2.7 | 通过for循环将数组复制到snapshot tabel中,然后再遍历snapshot table |
测试代码链接:
磁盘的读写速度通常差距比较大,写的速度可以只是读的1/N,这个N可能是 3,4,5,6,7,8,9中的一个;但是内存,读写往往速度一样,copy则更快