Converging to a single point #32
Comments
|
That's an interesting and disconcerting phenomenon. It isn't immediately clear to me what would be causing this. I would speculate that the issue is "noise" -- points that are sufficiently far from everything that UMAP ends up trying to spread them all apart from one another, with the result that any points that are close end up getting packed into the point in the center to make them far from the scattered points around the outside. Assuming this speculation is correct I would expect the central dense cluster to have significant further substructure if you were to zoom in on only it and ignore the outlying points. As to how to remedy this -- assuming my speculation is correct (it may not be) then increasing the |
|
I ran it again with increased Here it is with
The central dense cluster does appear to have more substructure than is visible from a distance:
And, interestingly enough, running UMAP again on the sparse cloud surrounding the dense cluster might reveal some other structure?
Here's a subset of 250Kx128 points https://drive.google.com/open?id=18tEzVM7nQ3KZhJNH6HuvEHL9rrDMmGAC (122MB). This should be enough to show the effect. |




|
I would guess you might need quite a large |
|
Sorry, I just realized I went in exactly the wrong direction with these values :) I'll re-run it. edit: Also, fwiw, here's the code I'm using to render things quickly: def draw_embedding(embedding, size=(1024,1024), face_color=255, stroke_color=0):
canvas = np.empty(size, dtype=np.uint8)
canvas.fill(face_color)
emax = embedding.max(axis=0)
emin = embedding.min(axis=0)
erange = emax - emin
scale = np.subtract(canvas.shape[:2], 1) / erange
indices = ((embedding - emin) * scale).astype(np.int32)
canvas[indices[:,0], indices[:,1]] = stroke_color
return canvas
|


|
So I'm playing a little and the obvious potential issues (the simplicial set skeleton has lots of tiny connected components) is not the case. Something very odd is going on. Increasing |
|
Thanks for the update. It seems like After more exploration I am more convinced that this actually a structure of the data itself (a scattering of points that are are all relatively different from one another and then a more interesting manifold that is essentially equidistant from all the "noise") rather than a "bug", but I do agree that this is not a helpful presentation. What would you like to see in this circumstance however? I think the results with the larger |
|
An alternative possibility occurred to me: it could be the approximate nearest neighbors failing in enough cases, and that may be what the cloud around the outside is. That's a little harder to look into, but I'll see if I can at least find out if that's true this evening. If that is the case then it is certainly fixable as it is a bug, although exactly how to fix it will be an interesting question. Edit: I thought about this some more and it seems like a likely candidate, as I am pretty sure it would produce the behaviour we are seeing here. As for a fix I have some initial heuristics that should work and hopefully I can refine them into something sensible that would do the job well. Definitely some work required though. |
|
I can confirm that the approx nearest neighbors is not working as well as would be desireable, and importantly the distribution of precision is quite wide, which leads me to believe that this is indeed the source of the issue. I still have to figure out the "right" way to fix this. Edit: Making progress on this -- I think I can have an "interim" solution soon, and hopefully a more robust solution not too long after that. Sorry for the lack of visible progress, but I am now convinced that this is an implementation related bug rather than anything fundamental to the algorithm, and so its just a matter of figuring out how best to dig myself out of that particular implementation issue. |
|
I'm seeing a possible precision-related issue in some of my tests, but it goes away when I change the random_state seed. I'll work on getting some examples... |
|
So the good news is I made some progress figuring out how to improve the nearest neighbor issues. The current approach would cause some performance regressions, so I just need to tweak things a little more to work well in cases like this but not lose (too much) performance in general. The bad news is that it didn't actually "fix" the problem, which tips me back toward it possibly being something structural in the data. I will have to play more to see if I can find a better way to give a nicer presentation. |
|
Alright, I have an appropriate solution that should work with the current code! The nearest neighbor approximation does need to be fixed, but that is not so much the problem here, because this is "structurally true" of the data. What we actually want is to have the effective repulsive forces between data points to be dampened (since that is what is actually causing the packing). Fortunately there is already a parameter for this:
As my colleague pointed out, if you have a manifold and noise that is noise in the full dimensional ambient space (as opposed to noise off the manifold) then this is exactly what you expect to happen, and the only way to reasonably combat that is to reduce how hard we force the noise points away from everything else. |

|
Here is the same (
I feel like this is (hopefully) the solution you were probably looking for. Clearly some more documentation on parameters and what to tweak under different circumstances is needed. Let me know if this is sufficient in term of what you were looking for, or if you had a different sort of result in mind. |
|
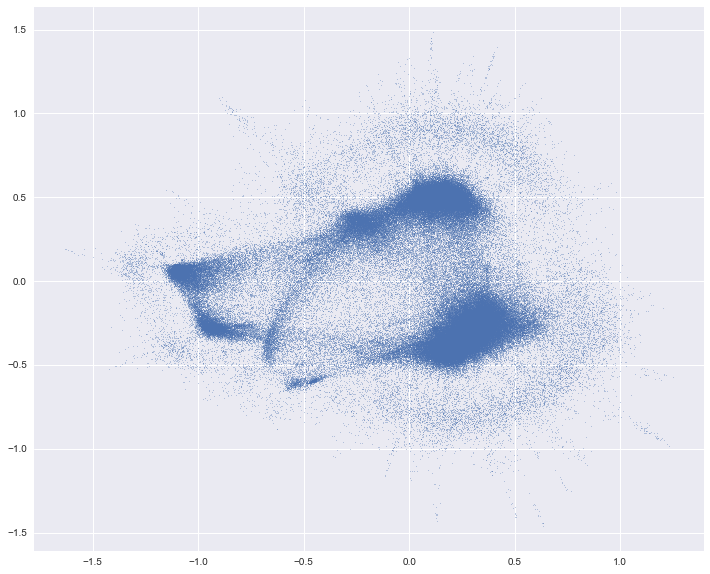
with more data, i was hoping for more resolution and data points in these smaller clusters.
and it happens up to a point, but once there are enough points these clusters turn into these "spiking" structures that shoot out. my ideal embedding would avoid those star-like spikes. but i need to look at the actual data closer and see if those small clusters are getting turned into spikes because they exist on a 1d manifold, or if it's just a "bug" and they really should be represented as a small cluster. going to close this though, since it solves my original issue of everything collapsing to a point. thanks so much for all your help and involvement in developing this tool :) |

|
For reference I have reproduced similar issues on another dataset, again at around the same amount of data. That seems a little suspicious to me, so I will continue digging. Sorry that I still don't have any good answers, but it is hard to understand exactly what is happening, let along what the correct fix is. |
|
I have finally found and fixed the issue that was causing this -- it was a (subtle) code bug in the SGD optimization. Moving to a different approach to the SGD optimization phase made this evident and resolved the issue. The latest master branch (v0.2.0+) should give better embeddings, particularly of larger datasets. For the data sample you provided I got the following:
|

|
wow this is great news! this embedding looks incredible! way more like what i would have expected! edit: i double-checked for myself and confirm i get the same output. to be clear, this is with all default parameters, no gamma or min_dist customization 😱
|

|
Why not create a repository of dataset |
I'm using UMAP to embed a bunch of 128 dimensional face embeddings generated by a neural net.
As I increase the number of embeddings (I have 3M total) the output from UMAP converges to a single point in the center surrounded by a sparse cloud around it. How can I fix this? Here are some examples from fewer samples to more samples. n = 73728, 114688, 172032, 196608, 245760
The text was updated successfully, but these errors were encountered: