[BUG] Failed replicas not being cleared from node #2461
Comments
|
@dbpolito Can you check the |
|
I don't remember customizing that, so i guess it's the default: That's not even customizable on helm chart: https://github.com/longhorn/charts/blob/master/charts/longhorn/templates/storageclass.yaml#L21 What is this? minutes? hours? days? |
|
|
|
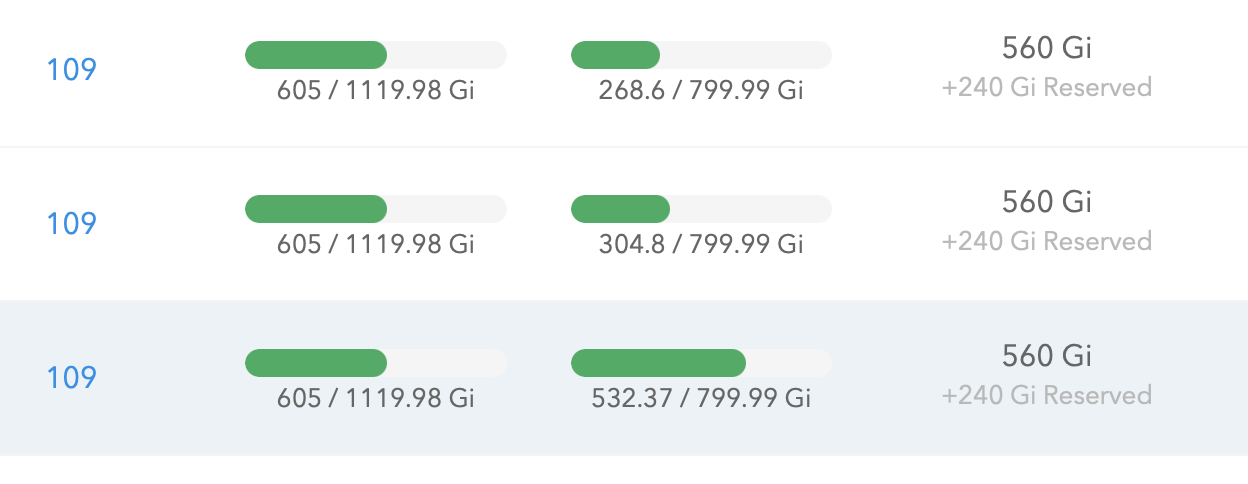
I see, well, after a few days i still have this huge difference between nodes:
Which i can't tell what it is... i'm guessing it's related to these failed replicas because this node had that and the size increased during that period of rebuild and never freed. |
|
Could you help to check if there any orphan replicas directory under the host path Right now, if the node even went down and back, Longhorn has no information anymore which is the orphan replicas (i.e., Longhorn did not scan the |
|
I left some quick thoughts on how replica deletion could be improved to ensure cleanup of replica data here: |
Describe the bug
I got a instability on one node that made some replicas to corrupt and got rebuilt, but it seems that the disk usage wasn't freed by these replicas that failed:
Environment:
Not sure that's really the problem but the only thing i noticed is this node disk increase after all these replica rebuilds...
The text was updated successfully, but these errors were encountered: