Why the speed in minicaffe is much worse than caffe with same prototxt #48
Comments
|
would you mind to paste your test code? |
|
In mini-caffe, I just add a "for(int i=0;i<100;i++)" before "test.Forward();" in run_net.cpp, and get the time from your output. |
|
I get the memory use from "nvidia-smi" with watching in the flesh. |
|
would u like to put up your performance with the resnet for a bug checking of mine? Thank you. |
|
I will test the network prototxt on 1070 later. With more details on mini-caffe and official caffe. |
|
I use those code to test your every layer's time. But cannot find the reason. |


|
Your net->Forward(2,3) give me an error. So I can only use net->Forward(0,x) to get the time from the begin and sub them. |
|
As the net get longer, the performance diff between mini-caffe and caffe become larger, when I test them by adding layer step by step for net construction. |
|
Update the performance up. |
|
I checked the cudnn and assured it ran well by adding some output info. |
|
please refer to profile.md to check the layer wise performance. I am writing tools to do the network benchmark. |
|
I have tried Profile in the beginning, but the time shown in chrome is not consistent with my test result. However, it's most possible that I made the wrong usage way. |
|
Pay attention to the Timer, it's not accuracy, use |
|
@yonghenglh6 You can try the |
|
I find the performance is not stable under Windows platform, I will test on Linux later. |
|
With your new benchmark tool, I found the bn layer is the main part that cause the difference, your bn is cost twice time than conv. So I changed to test it on google without bn layer and the result shows similar performance between caffe and mini-caffe. |
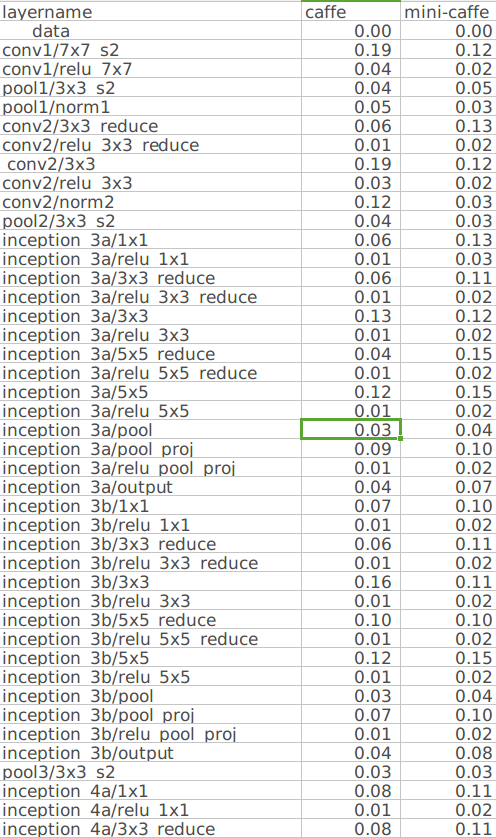
|
There is an optimization in this commit for BatchNorm Layer. I will update this from official caffe. |
|
Everytime you request memory from pool, the blob will be in uninitial state, then it will call gpu_memset function in "to_gpu()", which will cost about 10% time more than original caffe whose blob will be keeped and in head_on_gpu state. |
|
The default behave is the same in official Caffe here. |
|
Yes, but the official Caffe need not reallocate blob every forward and not call the function frequently. But your minicaffe keeping on setting the blob state to uninitial to reuse the memory and then rememset the memory when calling to_gpu(), which has caused a performance problem. |
|
you mean this function? It is a problem that this function called every time a new memory is requested. I think we can remove this function call, as the dirty data in the memory seems no problem for late use. What do you think? |
|
Yes. |
I compare the resnet from your run_test.cpp.
But the performance is like below. The speed drop down than caffe.
Any ideas?
I'm useing the newest caffe with cudnn 5.1.5.
Thanks
The text was updated successfully, but these errors were encountered: