Python API 拥有三大模块:
- 基础OCR接口
- 结果可视化模块,将OCR结果绘制到图像上并展示或保存。
- 文本后处理模块,支持段落合并、竖排文本整理等功能。
from PPOCR_api import PPOCR初始化识别器对象,传入 PaddleOCR_json.exe 的路径
ocr = PPOCR(r'…………\PaddleOCR_json.exe')支持传入启动参数
argument = {'limit_side_len': 3500}
ocr = PPOCR(r'…………\PaddleOCR_json.exe' ,argument)testImg = r'………\测试.png'
getObj = ocr.run(testImg)
if getObj["code"] == 100: # 成功
print(getObj["data"])
elif getObj["code"] == 101: # 成功,但无文字
print('图片中为找到文字')
else: # 失败
print(f'识别失败,状态码{getObj["code"]}')
print(f'异常信息{getObj["data"]}')可以跟识别图片放在一起:
testImg = r'………\长截图.png'
# 调高压缩阈限,增加对长图的识别率
updateDict = {'limit_side_len': 3500}
getObj = ocr.run(testImg, updateDict)
print(f'热更新日志:{getObj["hotUpdate"]}')也可以单独执行:
# 调回正常的压缩阈值960,以免影响后续正常图片的识别速度
ocr.run('', argument={'limit_side_len': 960})剪贴板中可以是位图(截图、网页复制),也可以是单个文件句柄(文件管理器中复制)。
getObj = ocr.runClipboard()使用示例详见 demo1.py
纯Python实现,不依赖PPOCR引擎的C++ opencv可视化模块,避免中文兼容性问题。
from PPOCR_visualize import visualize需要PIL图像处理库:pip install pillow
首先得成功执行一次OCR,获取文本块列表(即['data']部分)
getObj = ocr.run(testImg)
if not getObj["code"] == 100:
print('识别失败!!')
exit()
textBlocks = getObj["data"] # 提取文本块数据只需一行代码,传入文本块和原图片的路径
visualize(textBlocks, testImg).show()此时程序阻塞,直到关闭图片浏览窗口才继续往下走。
visualize(textBlocks, testImg).save('可视化结果.png')vis = visualize(textBlocks, testImg)
img = vis.get()以上show,save,get三个接口,均能开启或禁用指定图层:
isBoxT时启用包围盒图层。isTextT时启用文字图层。isOrderT时启用序号图层。isSourceT时启用原图。F禁用原图,即得到透明背景的纯可视化结果。
传入两个PIL Image对象,返回它们左右拼接而成的新Image
img_12 = visualize.createContrast(img1, img2)导入PIL库,以便操作图片对象
from PIL import Image接口创建各个图层,传入文本块、要生成的图层大小、自定义参数,然后将各个图层合并
颜色有关的参数,均可传入6位RGB十六进制码(如#112233)或8位RGBA码(最后两位控制透明度,如#11223344)
# 创建各图层
img = Image.open(testImg).convert('RGBA') # 原始图片背景图层
imgBox = visualize.createBox(textBlocks, img.size, # 包围盒图层
outline='#ccaa99aa', width=10)
imgText = visualize.createText(textBlocks, img.size, # 文本图层
fill='#44556699')
# 合并各图层
img = visualize.composite(img, imgBox)
img = visualize.composite(img, imgText)
img.show() # 显示使用示例详见 demo2.py
tbpu : text block processing unit
由 Umi-OCR 下放的技术。
OCR返回的结果中,一项包含文字、包围盒、置信度的元素,称为一个“文本块” - text block 。
文块不一定是完整的一句话或一个段落。反之,一般是零散的文字。一个OCR结果常由多个文块组成。文块后处理就是:将传入的多个文块进行处理,比如合并、排序、删除文块。
import tbpu- 优化单行:
run_merge_line_h - 合并多行-左对齐:
run_merge_line_h_m_left - 合并多行-自然段:
run_merge_line_h_m_paragraph - 合并多行-模糊匹配:
run_merge_line_h_m_fuzzy - 竖排-从左到右-单行:
run_merge_line_v_lr - 竖排-从右至左-单行:
run_merge_line_v_rl
向接口传入文本块列表(即['data']部分),返回新的文本块列表。
# 执行文本块后处理:合并自然段
textBlocksNew = tbpu.run_merge_line_h_m_paragraph(textBlocks)执行后,原列表 textBlocks 的结构可能被破坏,不要再使用原列表(或先深拷贝备份)。
可以串联使用,但目前这没什么意义。(除非你将Umi-OCR项目中的忽略区域模块分离出来,它跟段落合并串联使用相性良好。)
tb1 = tbpu.run_merge_line_h_m_paragraph(textBlocks)
tb2 = tbpu.merge_line_h_m_fuzzy(tb1)跟结果可视化配合使用:
textBlocks = getObj["data"] # 提取文本块数据
# OCR原始结果的可视化Image
img1 = visualize(textBlocks, testImg).get(isOrder=True)
# 执行文本块后处理:合并自然段
textBlocksNew = tbpu.run_merge_line_h_m_paragraph(textBlocks)
# 后处理结果的可视化Image
img2 = visualize(textBlocksNew, testImg).get(isOrder=True)
# 左右拼接图片并展示
visualize.createContrast(img1, img2).show()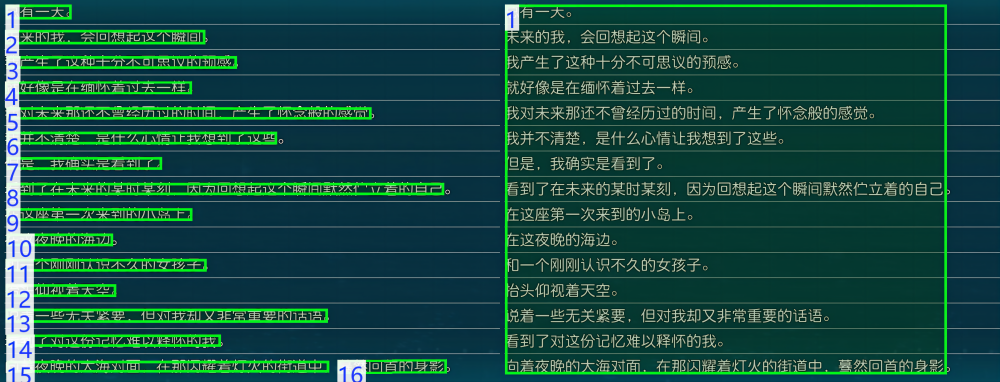
使用示例详见 demo3.py