Inconsistency between topic with maximum probability and the predicted one for a document #65
Comments
|
I think it is related with HDBSCAN. You can check here, original docs. |
|
Unfortunately, the soft clustering is still an experimental feature that does have its fair share of open issues if you look through the HDBSCAN repo. As of this moment, it does seem that the probabilities for some documents do not represent the topics they were assigned to. Having said that, after some testing, it does seem that 98,9% of the probabilities are correctly assigned. The ones that aren't do match with their second highest probability. Fortunately, this means that the probabilities itself still can be interpreted although you should be careful indeed when blindly taking the highest probability. |
|
Thanks you guys for being responsive. |
|
Hey, not entirely sure how to proceed, what is the best way to get probabilities over documents: currently I have a 100% disconnect, is this normal.
|
|
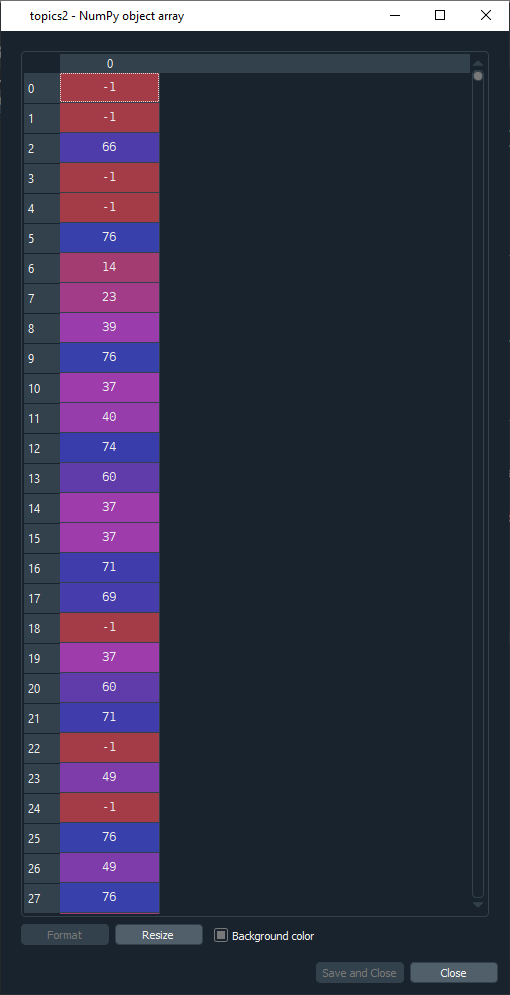
Hello everyone, I faced the same issue, and did some further research on the HDBSCAN repo and found there are some new commits that propose a way around the problem. It is not a perfect solution but the new probabilities are a much closer match than before. Following the flat.py hdbscan_flat functions, the solutions involve three steps:
import hdbscan
from bertopic import BERTopic topic_model = BERTopic(language="multilingual", calculate_probabilities=True, verbose=True,
from hdbscan.flat import (HDBSCAN_flat, def n_clusters_from_labels(labels_): n_clusters = n_clusters_from_labels(cluster.labels_) When we ask for flat clustering with same n_clusters,clusterer_flat = HDBSCAN_flat(embs, n_clusters=n_clusters, #we get the new topics, and probabilities topics2=clusterer_flat.labels_ now the prob2 match much closer to topics 2 and that2 I hope this helps |

|
Hi, |
Hi Maarten,
When using BERTopic on fetch_20newsgroups dataset to extract topics and their associated representative documents I figured out that for a given document the predicted topic was different from the one with the maximum probability. Of course, I checked it for topic label different from -1. In other words, it seems to have an inconsistency between predicted topics and probabilities. Is this normal ?
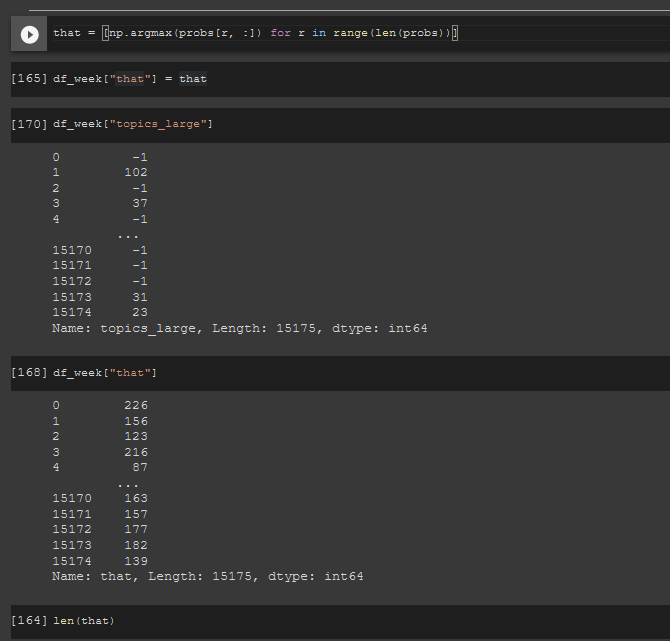
When we use the following:
For each index idx we should not have
preds[idx] == numpy.argmax(probs[idx, :])?Thank you in advance for your response.
The text was updated successfully, but these errors were encountered: