Results of mfcc in main.c is different from that in python with the same setting. #103
Comments
|
mfcc setting in python: |
|
Hi @liziru Please use some true number to test both functions. All zero simply means there is no energy in each band so the first band will give to its minimum cause by Log(0). With true signal (or just some random noise), you might plot both or use some metric like MSE or cosine similarity to compare the output of those 2 signals. Since we use the option nnom/examples/rnn-denoise/main_arm.c Line 210 in ec3afac nnom/examples/rnn-denoise/main.py Line 269 in ec3afac They will both saturated to |
|
@majianjia Second, with the sample input, the result of nnom inference is a little different from results of tf model.predict api. |
|
As a footnote,my nn model is made up of four full-connected layers, so there is no hidden information like RNN. And, the result distributions of two inference engines is almost same. |
|
the 8 bit resolution might not good for regression application. Please also try to this if It is related. #104 I will check in detail later when I am back. |
Thank you very much. I checked my code and 'NNOM_TRUNCATE' was already defined in nnom_port.h as you advised in #104, but I didnot do the following step because i think this ops will round the results. Sadly, the loss is not changed. |
|
Round or floor don't actually change the result because it only affects the result by 0.5/128. Did you try to use Conv or RNN? They might be different, dense is not working well when the 2 vectors is hugely in size (e.g. 1000 units input vs 2 units output).
|

Thank you for your reply. |
|
The RNN currently runs with 8bit input/output data and 16bit memory (state) data, which might keep more info. |
OK, I think i am close to the answer. I found the weights.h file is different because of different x_train, i have to say the x_train is generated randomly, which is used to compare with nnom infer in c code with x_train as the same input. As a result, the result of nnorm infer with different weight.h file generated with different x_train. So, the loss of two infer engines maybe caused by setting in weight.h. |

|
@majianjia After i set x_train in 'generate_model' to x_train of training as you did in main.py example, |
|
Forget about For the calibration step I will suggest you run the example first. Once it is successful, then modify the tf model and see if it still work. |
I am sorry to tell you that enlarging the size of |
Results of mfcc in main.c is different from that in python with the same setting.
I give the same input(512 zero samples.) to the 'mfcc‘ api in main.c and python with the same setting, but i got different results. The setting is shown below:
Python: mfcc api in main.c  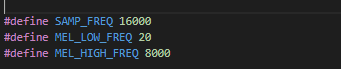The input is 512 zero sample, and the result is
-84.3408 0.0000 -0.0000 0.0000 -0.0000 0.0000 -0.0000 0.0000 -0.0000 -0.0000 0.0001 -0.0001 0.0000 -0.0000 -0.0001 -0.0000 0.0000 0.0001 -0.0001 0.0002in main.c and '-36.0437,0.0000,0.0000,0.0000,0.0000,0.0000,0.0000,0.0000,0.0000,0.0000,0.0000,0.0000,0.0000,0.0000,0.0000,0.0000,0.0000,0.0000,0.0000,0.0000' in python.The mfcc setting is the same as original rnn-denoise example that makes me confused a lot.
I will appreciate a lot for any help.
The text was updated successfully, but these errors were encountered: