An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
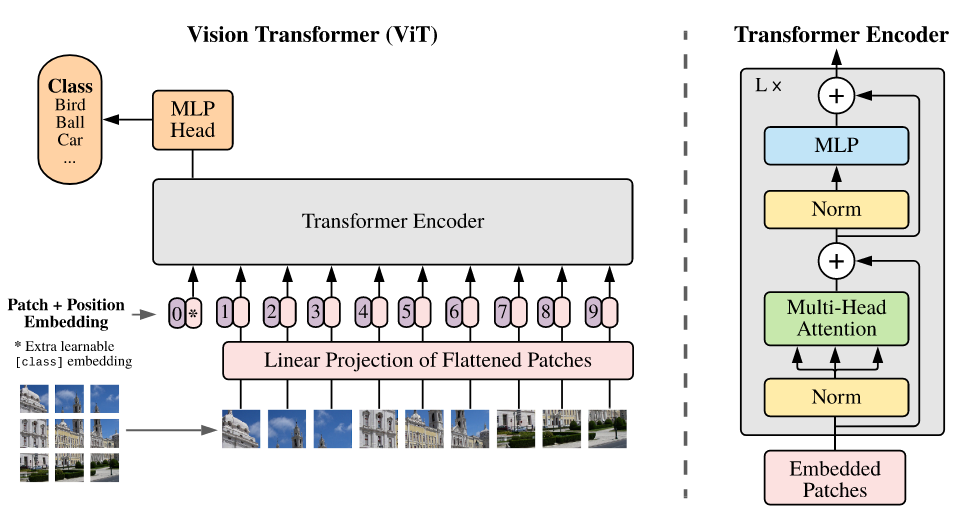
While the Transformer architecture has become the de-facto standard for natural language processing tasks, its applications to computer vision remain limited. In vision, attention is either applied in conjunction with convolutional networks, or used to replace certain components of convolutional networks while keeping their overall structure in place. We show that this reliance on CNNs is not necessary and a pure transformer applied directly to sequences of image patches can perform very well on image classification tasks. When pre-trained on large amounts of data and transferred to multiple mid-sized or small image recognition benchmarks (ImageNet, CIFAR-100, VTAB, etc.), Vision Transformer (ViT) attains excellent results compared to state-of-the-art convolutional networks while requiring substantially fewer computational resources to train.
@article{dosoViTskiy2020,
title={An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
author={DosoViTskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},
journal={arXiv preprint arXiv:2010.11929},
year={2020}
}To use other repositories' pre-trained models, it is necessary to convert keys.
We provide a script vit2mmseg.py in the tools directory to convert the key of models from timm to MMSegmentation style.
python tools/model_converters/vit2mmseg.py ${PRETRAIN_PATH} ${STORE_PATH}E.g.
python tools/model_converters/vit2mmseg.py https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-vitjx/jx_vit_base_p16_224-80ecf9dd.pth pretrain/jx_vit_base_p16_224-80ecf9dd.pthThis script convert model from PRETRAIN_PATH and store the converted model in STORE_PATH.
| Method | Backbone | Crop Size | Lr schd | Mem (GB) | Inf time (fps) | mIoU | mIoU(ms+flip) | config | download |
|---|---|---|---|---|---|---|---|---|---|
| UPerNet | ViT-B + MLN | 512x512 | 80000 | 9.20 | 6.94 | 47.71 | 49.51 | config | model | log |
| UPerNet | ViT-B + MLN | 512x512 | 160000 | 9.20 | 7.58 | 46.75 | 48.46 | config | model | log |
| UPerNet | ViT-B + LN + MLN | 512x512 | 160000 | 9.21 | 6.82 | 47.73 | 49.95 | config | model | log |
| UPerNet | DeiT-S | 512x512 | 80000 | 4.68 | 29.85 | 42.96 | 43.79 | config | model | log |
| UPerNet | DeiT-S | 512x512 | 160000 | 4.68 | 29.19 | 42.87 | 43.79 | config | model | log |
| UPerNet | DeiT-S + MLN | 512x512 | 160000 | 5.69 | 11.18 | 43.82 | 45.07 | config | model | log |
| UPerNet | DeiT-S + LN + MLN | 512x512 | 160000 | 5.69 | 12.39 | 43.52 | 45.01 | config | model | log |
| UPerNet | DeiT-B | 512x512 | 80000 | 7.75 | 9.69 | 45.24 | 46.73 | config | model | log |
| UPerNet | DeiT-B | 512x512 | 160000 | 7.75 | 10.39 | 45.36 | 47.16 | config | model | log |
| UPerNet | DeiT-B + MLN | 512x512 | 160000 | 9.21 | 7.78 | 45.46 | 47.16 | config | model | log |
| UPerNet | DeiT-B + LN + MLN | 512x512 | 160000 | 9.21 | 7.75 | 45.37 | 47.23 | config | model | log |