Model Inferencing #117
Comments
|
Do you change saved path? "roberta" folder is a pre-trained model and you can't save the model to this folder when you fine-tune the model. please follow this https://github.com/microsoft/CodeBERT/tree/master/GraphCodeBERT/clonedetection and results will be printed to saved_models/predictions.txt CodeBERT/GraphCodeBERT/clonedetection/run.py Line 510 in edc05c3 |
So after fine tuning the model, I downloaded the fine tuned model and added it to the roberta folder and renamed it to "pytorch_model.bin". Now after that I'm trying to inference the model to do eval from the folder "roberta" |
|
You can't replace "roberta/pytorch_model.bin" by fine-tuned model, and you need to keep roberta folder unchanged. Here will reload fine-tuned model CodeBERT/GraphCodeBERT/clonedetection/run.py Lines 614 to 616 in edc05c3 |
So, I was able to load and run the fine-tuned model for inferencing for evaluation only, using the following command "!python run.py --output_dir=saved_models --config_name=microsoft/graphcodebert-base --model_name_or_path=microsoft/graphcodebert-base --tokenizer_name=microsoft/graphcodebert-base --do_eval --train_data_file=dataset/train.txt --eval_data_file=dataset/valid.txt --test_data_file=dataset/test.txt --epoch 1 --code_length 128 --eval_batch_size 4 --learning_rate 2e-5 --max_grad_norm 1.0 --evaluate_during_training". I'm running this on the dataset provided in the github itself. So I have created my own dataset with func and idx and created valid.txt also. So how do I evalute this on the model. and generate predictions.txt on clone detection of graphcodebert |
|
You can use the same format to save your dataset. And then replace our dataset by your own dataset. |
|
I need to create the dataset in python and I'm facing few errors when done and being tested on the model. json.decoder.JSONDecodeError: Expecting ',' delimiter: line 1 column 414 (char 413 This one and an nother jsondecodeerror so. Can you please let us know. Or provide a simple code here lets say for adding two numbers and subracting two numbers in python. maybe if you provide this simple input it will be a lot helpful for me to create the custom data and test it on the model ps. i tried following the same instructions and created the dataset {"func": " public class MinimumValueExample \n {\n \n static int findMin(int inputArr[], int index, int size)\n {\n \n if(size == 1)\n {\n return inputArr[index];\n }\n \n return Math.min( inputArr[index], findMin(inputArr, index + 1, size - 1));\n }\n public static void main(String argvs[]) \n {\n int numArr[] = { 27, 56, 90, 12, 120, 263 }; \n System.out.println("The input Array is : " + Arrays.toString(numArr));\n int length = numArr.length; \n int minVal = findMin(numArr, 0, length); \n \n System.out.print("Minimum element of the input array is: " + minVal + " \n ");\n }\n }", "idx": "1212121"} |
|
Your data is not correct json format. Please use |
|
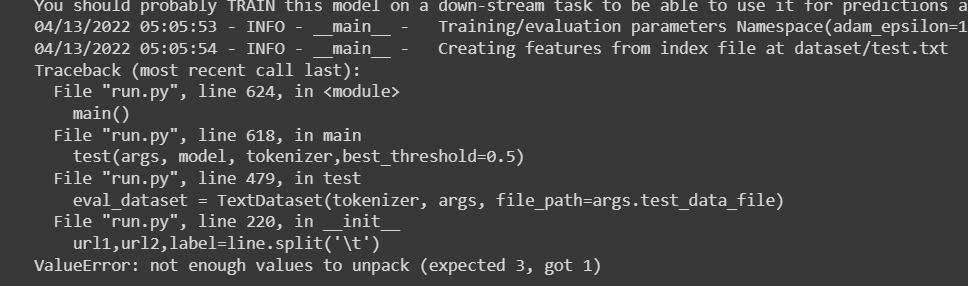
So I dumped as you mentioned above and got rid of the json error. Now I'm getting a Value error I have only 3 values in my test.txt file and i have successfuly entered the code that i wanna test into the data.jsonl file too
after all this when i run the comman !python run.py --output_dir=saved_models --config_name=microsoft/graphcodebert-base --model_name_or_path=microsoft/graphcodebert-base --tokenizer_name=microsoft/graphcodebert-base --do_test --train_data_file=dataset/train.txt --test_data_file=dataset/test.txt --epoch 1 --code_length 256 --data_flow_length 64 --learning_rate 2e-5 --max_grad_norm 1.0 --seed 123456 2>&1| tee custom_saved_models/test.log |


|
For test.txt file, please use Tab, i.e \t, to separate them instead of space key. |
|
So, I saved the finetuned model and I am trying to load and use it and I'm getting the following error What to do to load the saved model and use it while inferencing |

|
Don't change any code you show. If you want to reload fine-tuned model from other path, just change here: CodeBERT/GraphCodeBERT/clonedetection/run.py Lines 614 to 615 in 3e58572 |
Hi, I'm using clone detection in GraphCodeBERT and I'm trying to do model inference from the saved checkpoint. I'm trying to load the saved model from a folder called "roberta" with all the pre-requisits that I got from hugging-face transformers. While Inferencing using the code given to inference "!python run.py --output_dir=saved_models --config_name=roberta --model_name_or_path=roberta --tokenizer_name=roberta --do_eval --train_data_file=dataset/train.txt --eval_data_file=dataset/valid.txt --test_data_file=dataset/test.txt --epoch 1 --code_length 128 --eval_batch_size 4 --learning_rate 2e-5 --max_grad_norm 1.0 --evaluate_during_training" So while running this command that I'm trying to load from the folder "roberta". I'm facing an error as "ValueError: The state dictionary of the model you are training to load is corrupted. Are you sure it was properly saved?". I load the model separately and try to print it. The model is in OrderedDict instead of StateDict. I tried rerunning and fine tune the model once again to save the model correctly and I see it doing the same things and saving in an OrderedDict format. And maybe this is causing the error.

PS:
What I'm trying to do is, Given two pieces of code in the dataset.json and the test.txt when all the indexes and actual predictions are mentioned I need to to inference on the saved model to give me the prediction whether it is similar or not. Either 0 or 1. How do I go about this, If possible give me a brief on how to do the process only for the above mentioned problem.
The text was updated successfully, but these errors were encountered: