Results on natural language code retrieval #91
Comments
|
|
So it's because of the different data used for pre-training, right? |
|
Both of them use the same model architecture as Roberta and the same pre-training data. But |
Thanks for your reply! I have another question. As described in the paper:
I wonder what data set RTD is trained on? |
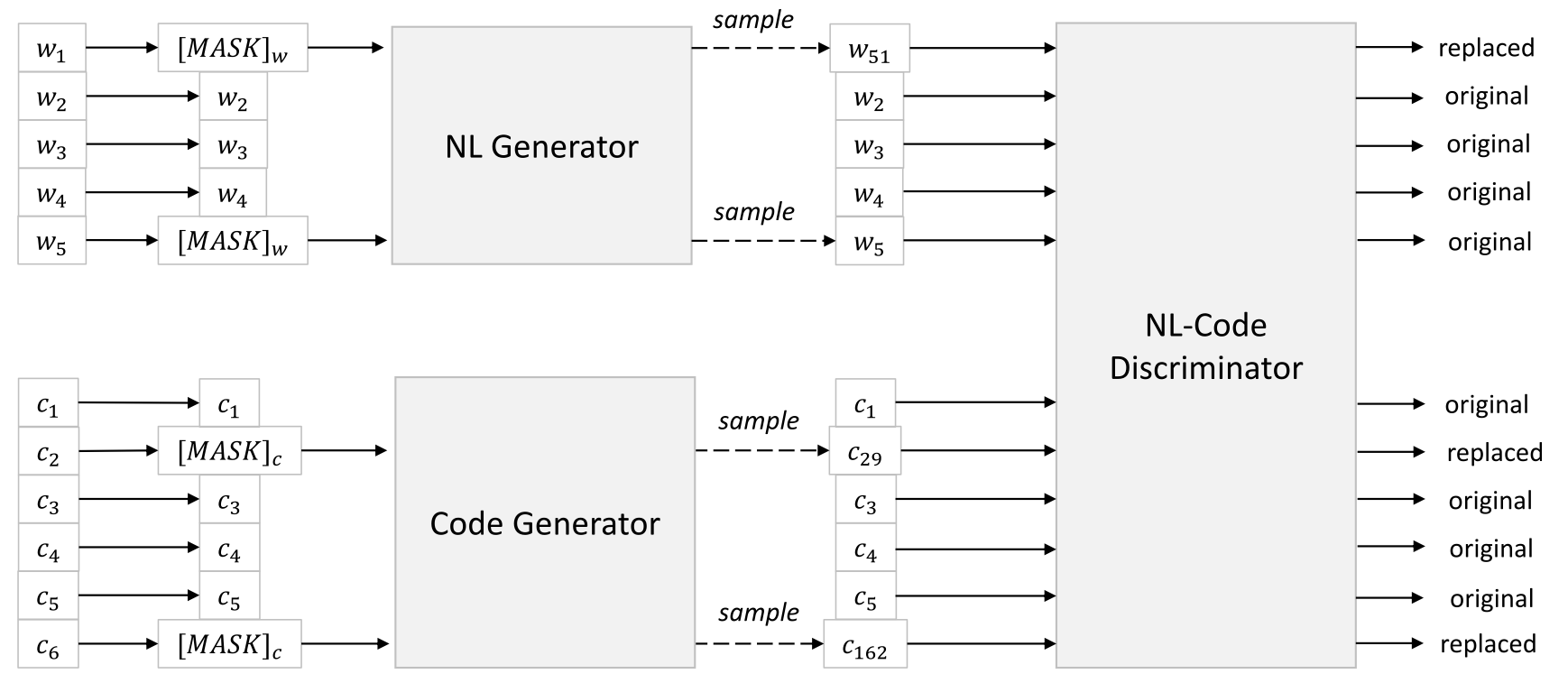

|
We first learn two generators separately with corresponding unimodal data to generate plausible alternatives for the set of randomly masked positions. Specifically, we implement two n-gram language models with bidirectional contexts. NL-Code discriminator is the targeted pre-trained model, both NL and code generators are thrown out in the fine-tuning step. |
Thanks for your reply! I have understood that discriminator is the targeted pre-trained model, both NL and code generators are thrown out in the fine-tuning step. But I don't understand that the RTD pre-training process.
So, are generators and discriminators trained separately? First, train two generators and then fix the two trained generators to train the discriminator?
What is the role of the pre-training discriminator? What is the relationship between the generic representation obtained by the discriminator during the fine-tuning phase and the representation obtained by the MLM output layer? What does it have to do with the representation of [CLS] when code searches for fine tuning?
|
|
What's the difference between pre-training data and fine-tuning data? The command to download the preprocessed training and validation dataset in the readme: what is the difference between them? Are pre-training and fine-tuning using the same data? |

Yes, you are right.
We use the multi-layer Transformer as the model architecture of CodeBERT. RTD and MLM are two objectives used for training CodeBERT. |
We only use the training data of the fine-tuning stage for pre-training. |
Thanks for your reply so quickly!
|
|
Yes,you are right. |
Is Codebert's pre-training data all NL-PL bimodal data? Do you use unimodal data?
|

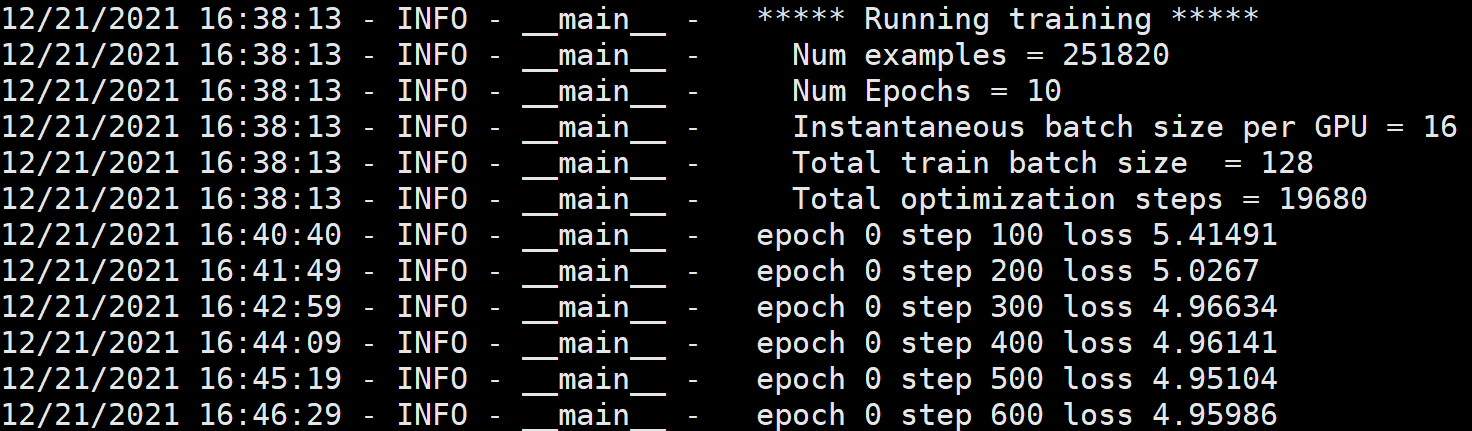

|
We pre-train CodeBERT with both bimodal data and unimodal data. We only use NL-PL bimodal data to finetune and evaluate the model for code search. |
|
I have completed the pre-training of
Are there any other tricks in the pre-training period? |

Why is the MA-AVG of
CODEBERT (MLM, INIT=R)about 3% higher than that ofPT W/ CODE ONLY (INIT=R)?Is it because their network structure is different?
But as described in the paper, they use the same network architecture and objective function MLM:
Is it because they use different pre-training data?
As described in the paper:
The text was updated successfully, but these errors were encountered: