[REQUEST] efficiently deal with frozen weights during training #2615
Comments
|
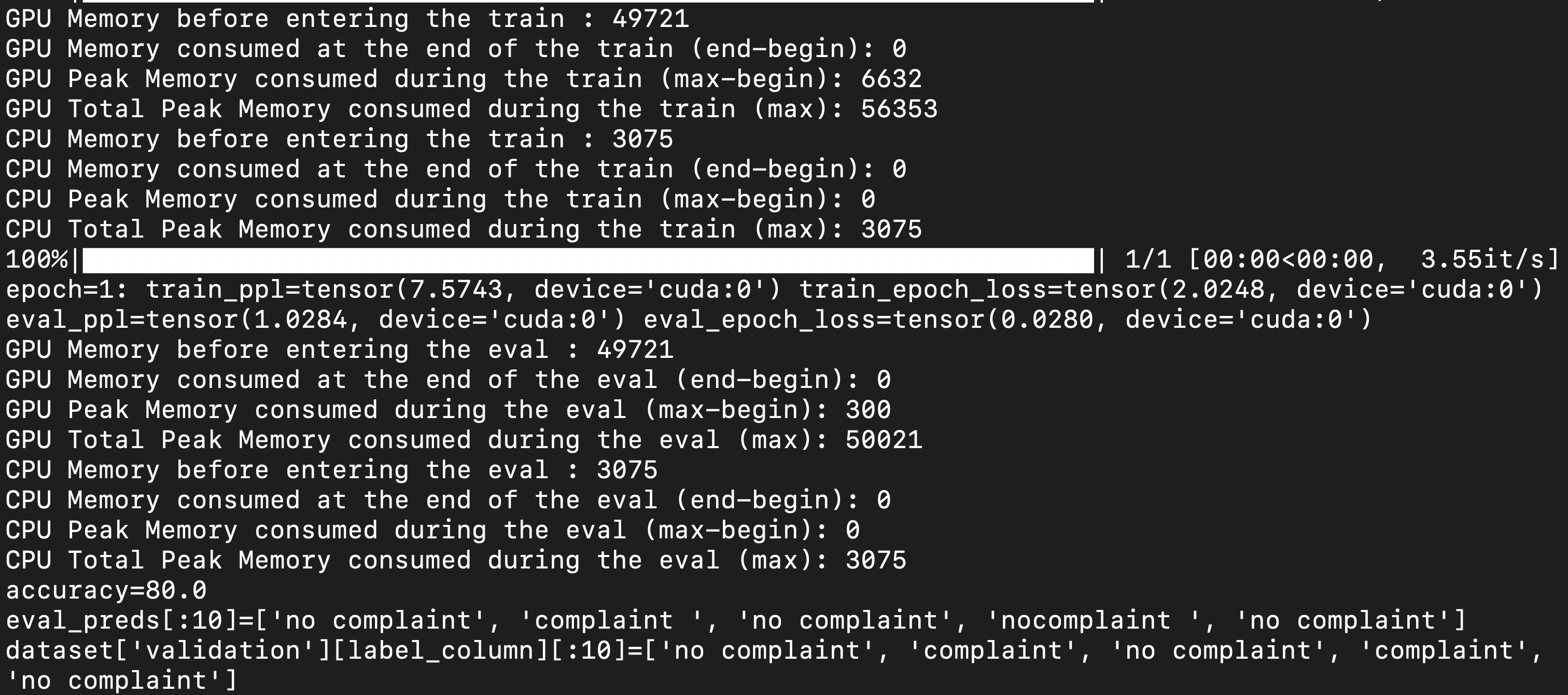
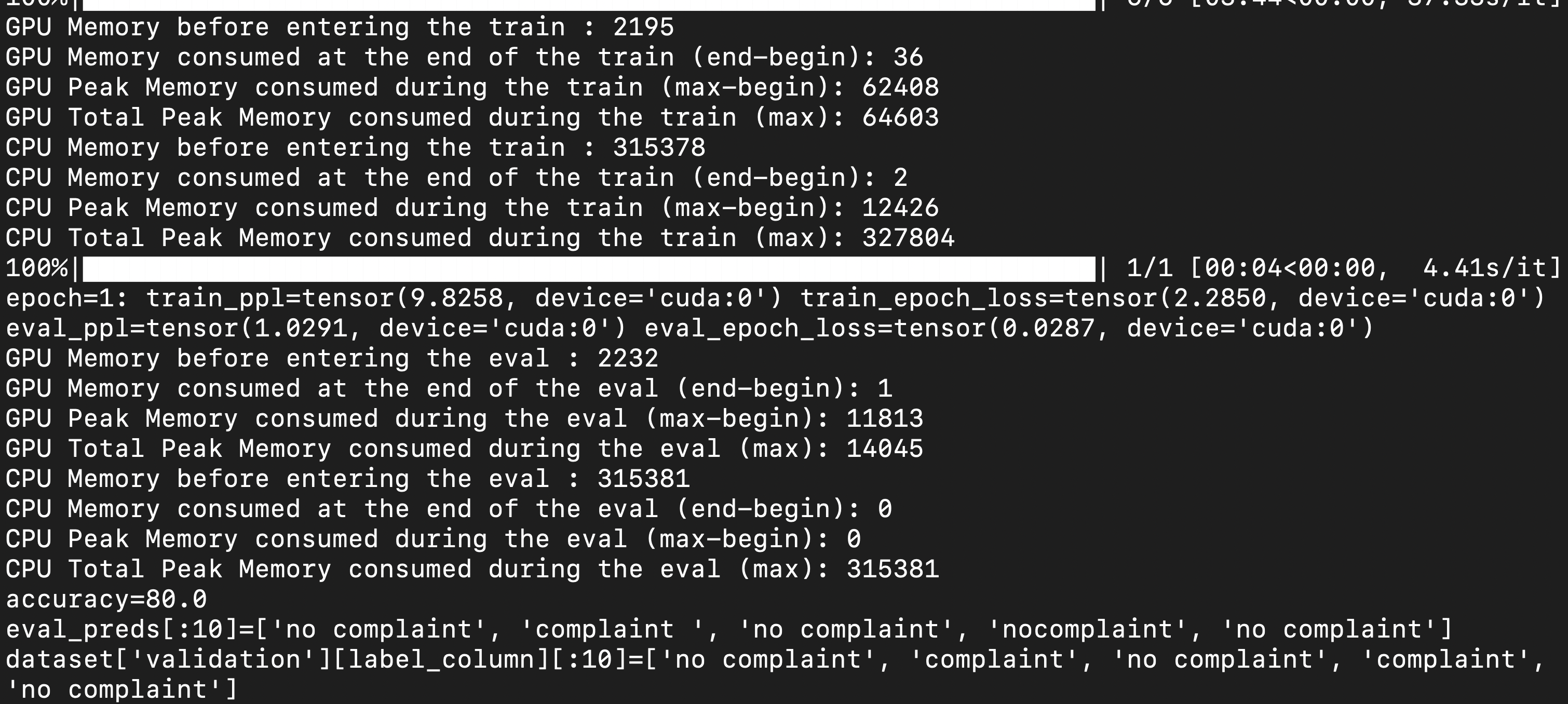
Current workaround is to create a param_group with all the frozen parameters and set the lr=0, an example is shown below: Below are the screenshots of memory usage (in MB) when using DS Stage 3 (GPU: 65 GB, CPU: 327 GB 🤯) with CPU offloading vs plain PyTorch (GPU: 56 GB, CPU: 3 GB). The model is MT0-XXL (13B params) and is using LoRA for parameter efficient fine-tuning.
Request: Efficiently deal with frozen weights during training such that large models could be offloaded on CPUs/sharded across GPUs properly with storage of the optimizer state only for the trainable parameters, e.g., we can see that using plain PyTorch, mt0-xxl (13B params) model takes up 56GB on GPU, now, it would be really helpful if one could do CPU offloading such that training could work on a 16GB or 24GB GPU. |
|
@pacman100, this is a great demo of the issue. Could you please share the repro steps? |
|
@stas00, @pacman100 please try out the linked PR. |
|
Hello @tjruwase, I tried the PR and it works great! Thanks a lot 😄, DeepSpeed team rocks✨🚀. Now, DeepSpeed ZeRO-3 with CPU offloading works as expected and the GPU memory usage is down from 65GB to 22GB and CPU usage is down from 327GB to 52GB (before PR vs after). For comparison, plain PyTorch takes (GPU: 56 GB, CPU: 3 GB) memory, so memory savings = 2.54X (PyTorch/DeepSpeed) on GPU and now would fit on consumer GPUs with 24GB GPU memory.
|

|
@stas00 @pacman100 is this already integrated into accelerate? |
|
With this PR Accelerate doesn't need to be touched. Though it could be changed to prep So the fastest is to install deepspeed from #2653 |
|
Hello @yuvalkirstain, yes, you can just get this working by installing the corresponding PR. Hello @stas00, I believe the PR would be really beneficial as it doesn't require users to make all those changes similar to the plain PyTorch case making their lives simpler. |
|
Just to clarify I'm not arguing against merging the DS PR, I was just thinking that perhaps HF Trainer and Accelerate should do that in the first place before creating the optimizer. Is there any reason why one would want frozen params in the optimizer? |
|
We plan to merge this PR as we have had internal requests as well. |
|
Awesome catch. However, I was able to get around this behaviour by having a separate deepspeed.initialize() on bloom and the prompt vocab for prompt tuning. But this had made code handling a bit harder. Thanks a lot for this one :) |
Is your feature request related to a problem? Please describe.
This is a need for HF
accelerateandm4projects.We have more and more situations where a large part of the model that's being trained is frozen.
At the moment the only way to emulate frozen weights in deepspeed is to create a param group with
lr=0, which works but a huge amount of memory is wasted to allocate states that aren't being trained (grads too?) and the compute is wasted too.Describe the solution you'd like
Ideally, if
requires_grad == Falsethose weights shouldn't be in the optimizer and not allocating any optim state/grad memory.Thank you!
@tjruwase
@pacman100 - would you like to add/expand anything to this request?
The text was updated successfully, but these errors were encountered: