Port the salary example to Python #104
Comments
|
@chisingh has a first cut working where you pass a string to be but maybe there's a way to solve both this problem and the next step (parsing the pipeline) at once: could we somehow inherit and extend the if we could it might solve the problem of having to parse the pandas pipeline manually because we'd have access to internal state and could see what happens at each step. this would help with tricky cases like the following: it's possible that we can learn something from @dodger487's dplython package or the similar pandas-ply package in terms of hacks pandas hacking. |
|
helpful tips from @dodger487, who recommended we check out the following libraries: https://docs.dask.org/en/stable/10-minutes-to-dask.html |
|
@giorgi-ghviniashvili: @chisingh has python code working that generates an array of specs and is now looking into rendering animations within a jupyter notebook. can you two discuss how to integrate the javascript code into jupyter? it looks like it might be as simple as calling the |
|
There are bunch of questions on Stackoverflow about embedding js code to jupyter notebook.
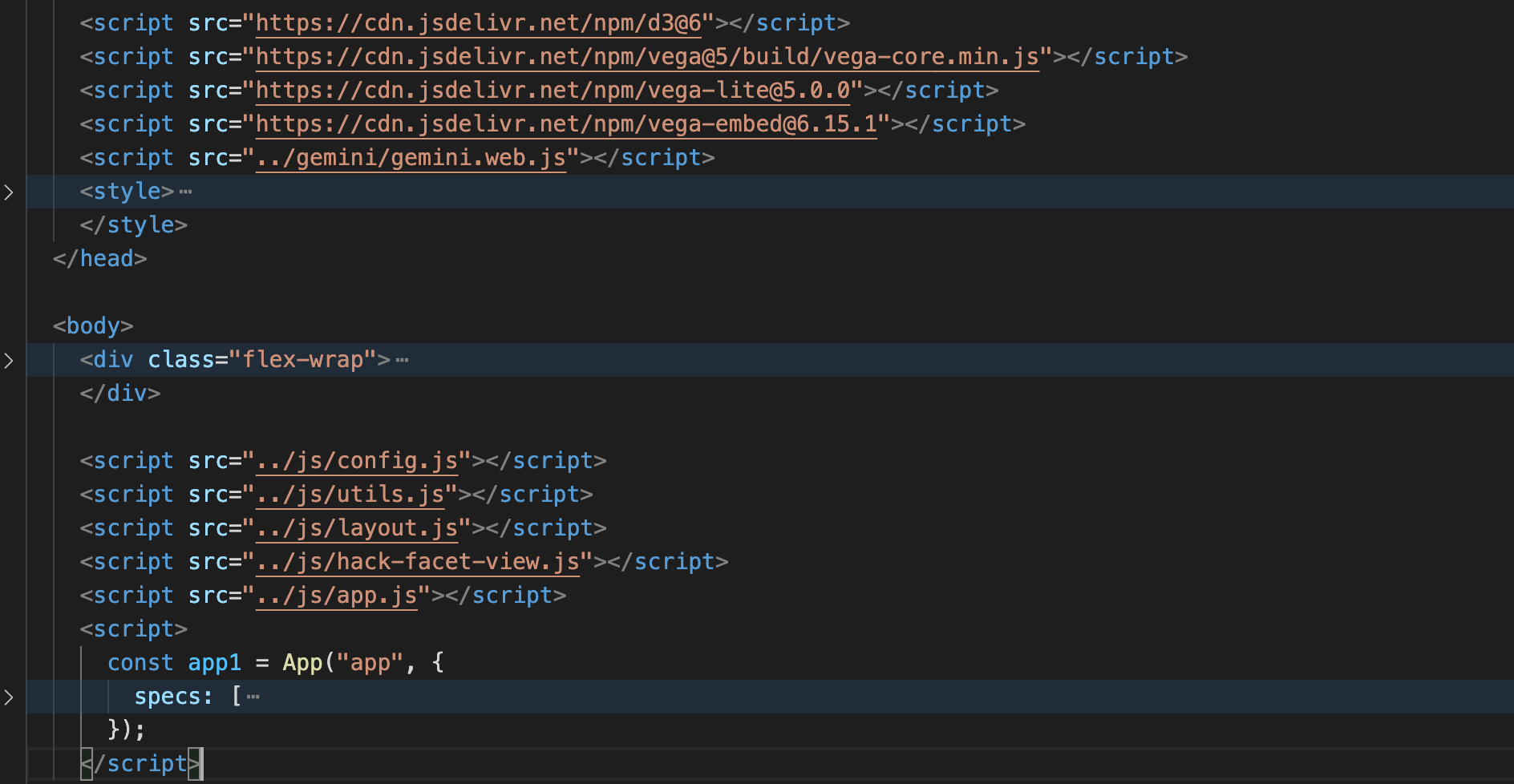
There is also cell magic commands : %%javascript or %%js: @chisingh can you try to import all the dependencies in the notebook and then call App? All the <script> tag, seen here, must be included as dependency. And then calling App like this.
|

|
@chisingh got a first cut of running @giorgi-ghviniashvili's app inside of jupyter working during our call! next steps are to:
|
|
For testing out the notebook (and also testing the python spec generation), here are the specs for this chunk of code: "small_salary %>%
group_by(Degree) %>%
summarize(mean = mean(Salary))" %>%
datamation_sanddance()small_salary.groupby("Degree").mean("Salary") |
Let's see if we can get the json for the key frames of this datamation when it's written in Python/Pandas:
In Python the analysis could should be something more like this:
small_salary.groupby("Degree").mean("Salary")where
small_salaryis a Pandas dataframe.Challenges here:
eval()function)?CSV of the data is here
cc @chisingh until your account is added to the repo.
The text was updated successfully, but these errors were encountered: