Unable to get vaild value from layoutlm model #91
Comments
|
Hi @NancyNozomi , |
|
Hi, @ranpox i know how valuable your time is to you so that thank you for taking the time to respond to email. I can finish the train after preprocess and run it in the run_seq_labeling.py which conf is equal to the command as follow as detail: py run_seq_labeling.py //the follow is the the default value --per_gpu_train_batch_size 8 i run it as above and would get the train.log and others in the dir out.But i change the --do_train to --do_predict only, it will catch error as the last description.i would show the value of the input and output in the model as detail in the end.Besides i note that there is a error in the running like THCudaCheck FAIL file=/tmp/pip-req-build-ocx5vxk7/aten/src/THC/THCCachingHostAllocator.cpp line=278 error=59 : im not sure whether my input is a wrong format due to the value -100 in the labels dict, and i wish my information is useful. Sincerely thank you at last. |



|
Why predict calculate loss? |
|
|

|
|
|
Hi @NancyNozomi , Thanks. |
|
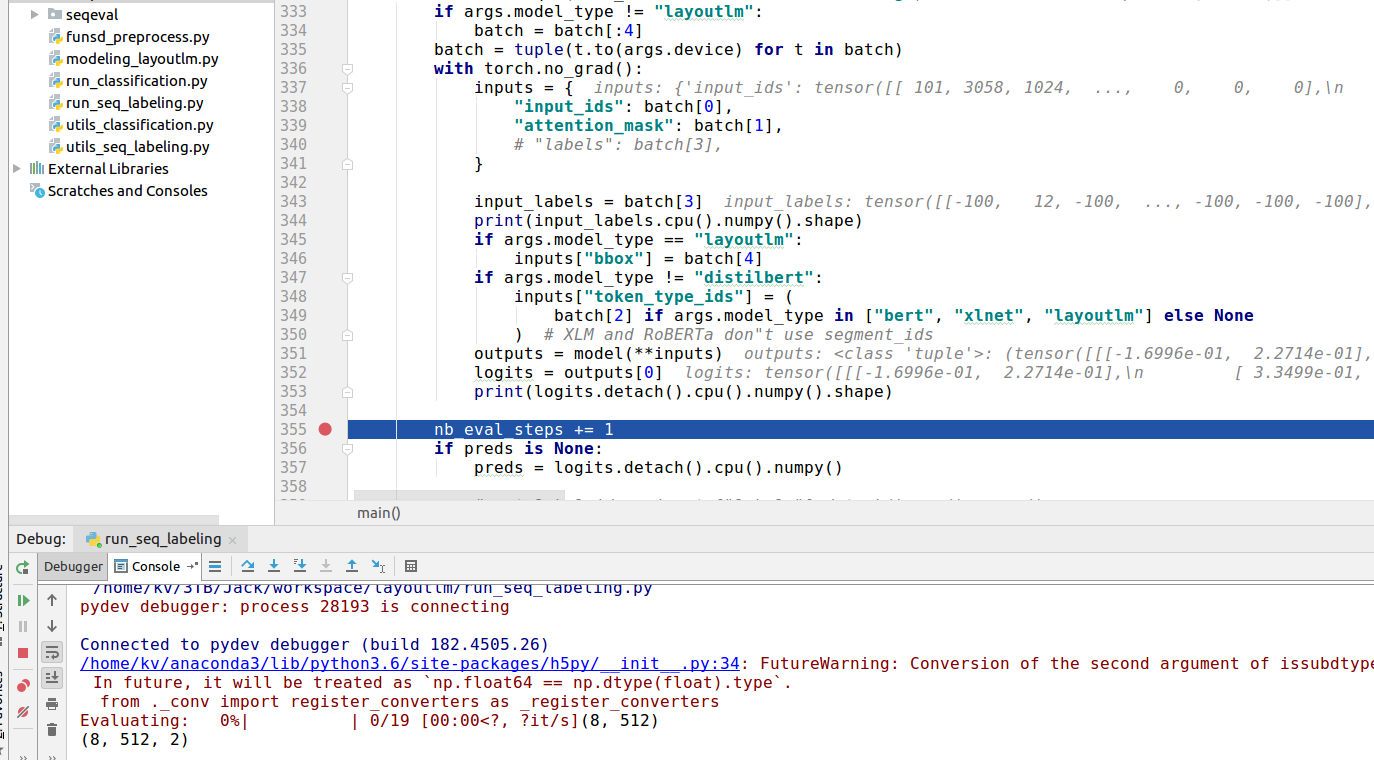
Hi, @ranpox , My file data/labels.txt seems correct as you discribe and the preprocessing step command is as the follow which equal to my run the python: wget https://guillaumejaume.github.io/FUNSD/dataset.zip python scripts/funsd_preprocess.py cat data/test.txt | cut -d$'\t' -f 2 | grep -v "^$"| sort | uniq > data/labels.txt i try to find the error where is happened, and find when run to the torch.nn.moudules.loss.py, the line 914 function: where self = CrossEntropyLoss(), input = tensor(...) ,target = tensor(...) So i think there is some worng in the input but i cannot know where lead to the wrong.I sincerely thank you in advance again and look forward to your help. |
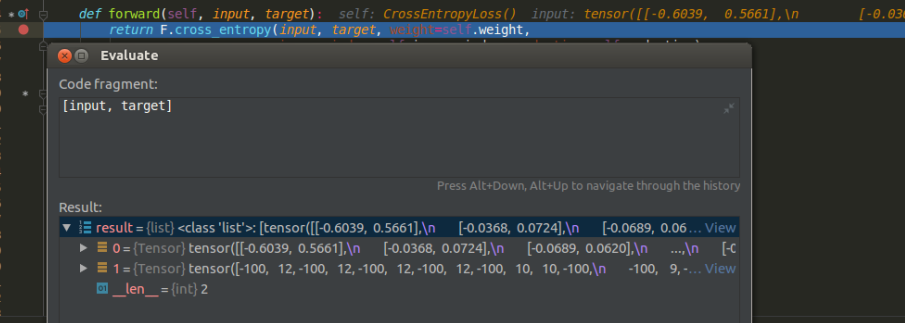
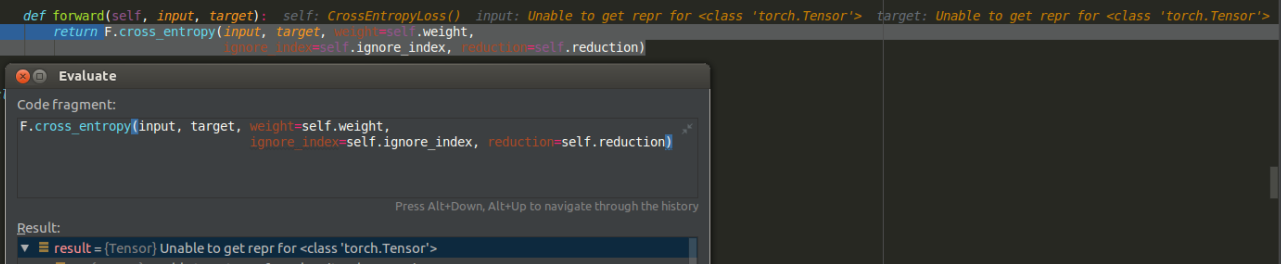
|
@ranpox based on your response to my thread regarding CUDA memory, I also tried @NancyNozomi configuration by setting --per_gpu_train_batch_size= 8, however, same error. |
|
@NancyNozomi which GPU did you use for the inference? |
|
Hi, @wolfshow |
|
@NancyNozomi have you ever tried updating the pytorch version and reducing the batch size? |
|
@wolfshow, |
|
@wolfshow, |
Hi there,
Thank you for your works very much and i'd like to use the LayoutLM network to try labeling in seq but I'm in trouble due to the question detail as follow:
for the env, i try to setup as readme.md but in the command
pip install -v --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./
there is a trouble so i use my env existed which also meet the requirement;
for the data, i download the FUNSD and preprocessing its testing_data follow the readme.md;
for the main, I run it in the run_seq_labeling.py but not command after preprocessing.I can finish the process of training but can not for the one of predicting. my conf is equivalent to the follow command:
python run_seq_labeling.py
--data_dir data
--model_type layoutlm
--model_name_or_path layout-large-uncased \ (Downloaded form google drive)
--output_dir out
--labels data/labels.txt
--do_predict
--do_lower_case
--overwrite_output_dir
and other command is not change from default. It will be error in
line 357: eval_loss += tmp_eval_loss.item()
and the error is
RuntimeError: CUDA error: device-side assert triggered
I debug it and this error may be created from
line 349: outputs = model(input)
due to the input is a dict of tensor contains {input_ids, attention_mask, labels, bbox, token_type_ids} but output is a tuple which contains 2 tensor but their data are Unable to get repr for 'torch.Tensor';
i run it as I understand it from paper but i do not know whether it is correct, and i have spend a long time in it but get none result, could you please provide some help for me. sincerely thanks;
The text was updated successfully, but these errors were encountered: