Editor model is set very late #37541
Comments
|
So, the rough order of things is like this:
I believe the order should be 1, 4, 2, 3. With some delaying in the extension service you can easily get to 1, 2, 4, 3 which makes the editor render roughly a second sooner. |
|
@jrieken viewlet and editor resolve in parallel if I remember correctly, the editor should never wait on the explorer to be loaed. I agree on pushing out the extension host loading to a later point would make sense. |
Wishful thinking... Nothing happens in parallel here. Yes, both use promises and both run async operations but because the viewlet is being asked first, it always wins |
|
@jrieken well "in parallel" meaning that both components go to disk and load files and the first one that gets back control will win to do the drawing. I am not sure how reordering the editor to be called first before the explorer would change anything because in the end it highly depends on what disk IO is being done from both components. |
|
I understand the theory but in practice I never measured a run where the editor won. Maybe that's because the explorer loads it's files very eagerly when being constructed whereas the editor widget needs to get the model set. Despite all parallelism, I believe the perceived performance depends a lot more on how soon you see text and a blinking cursor and not on how fast the tree populates and because of that we shouldn't even allow that "race" but start with the editor. |
|
Yeah, let's make sure the editor wins and see why that is not the case. |
|
Let's swap 1 and 2, Call me artist.
|
|
I have pushed ff82f1a which makes sure extension-host-startup and package.json-scanning is done after the editor is populated. This improves the perceived performance but it also causes flicker, e.g. the text is rendered without colors first, then the grammers/tokenizers are loaded, and then the text is re-rendered with colors. @bpasero I have also played with |
|
@jrieken sounds good, I will look into that part |
|
I have disabled my late-ext-host-launch-change because of #37751 |
|
I have pushed ab17bb7 which adds a new lifecycle event
|

|
I pushed a change to restore the editor first before sidebar and panel (c1bfc05). I still see the explorer showing data first before the editor shows any data. Next I will first get rid of |
|
Three things happen at the same time: (1) populating the editor, (2) populating the explorer, (3) scanning for extensions. And the reason for the editor being set so late is a big waterfall... This is what happens when calling
Lots of waiting and delaying.... (around 1 second) Questions:
|
@jrieken it's been a while since I touched this, I think the editor model needs the backup model to be initialized in order to get the content. If a particular file has a backup it needs to be loaded from the backup file in user data, not the regular file. Here's where the loading happens: A
Not sure if I answered your question. |
|
@jrieken we need the I guess we could experiment with detecting the encoding and leaving the stream open to do the actual read of the file. We would need to be able to push back bytes to the stream though so that we can give the entire stream to As for the backups: I am not sure how we could load the backup and the model in parallel because we need to know if there is a backup to resolve the file properly. Are you suggesting to load both in parallel and then see if we actually have a backup and then pick that one over the file we resolved? |
|
@jrieken now that we have the startup phases in lifecycle service, should we change |
Well, fortunately not every file read does that. Question is why reading needs to wait for stating? Why doesn't the editor call
Not sure I understand that? We only give it 512 or 4096 bytes anyways. We could just start reading, buffer so many bytes require to detect encoding, guess the encoding via
I believe that the blocking call is just to build the index of of backup files not loading. We could also optimistically do it in parallel and drop the "real" file once we know a back exists. |
@jrieken we first do the stat to prevent unneeded disk IO for reading the file in case the file has not changed. Every time you click on a tab we do this call, even if the tab has already been opened before (because the file could have changed on disk and we do not trust the file events). If we would start to always read the file from disk in that case I think we would too much unnecessary work. We could however think about doing this either only on startup or just create a new
Yeah, I guess the challenge is with
Yes, that could work. |
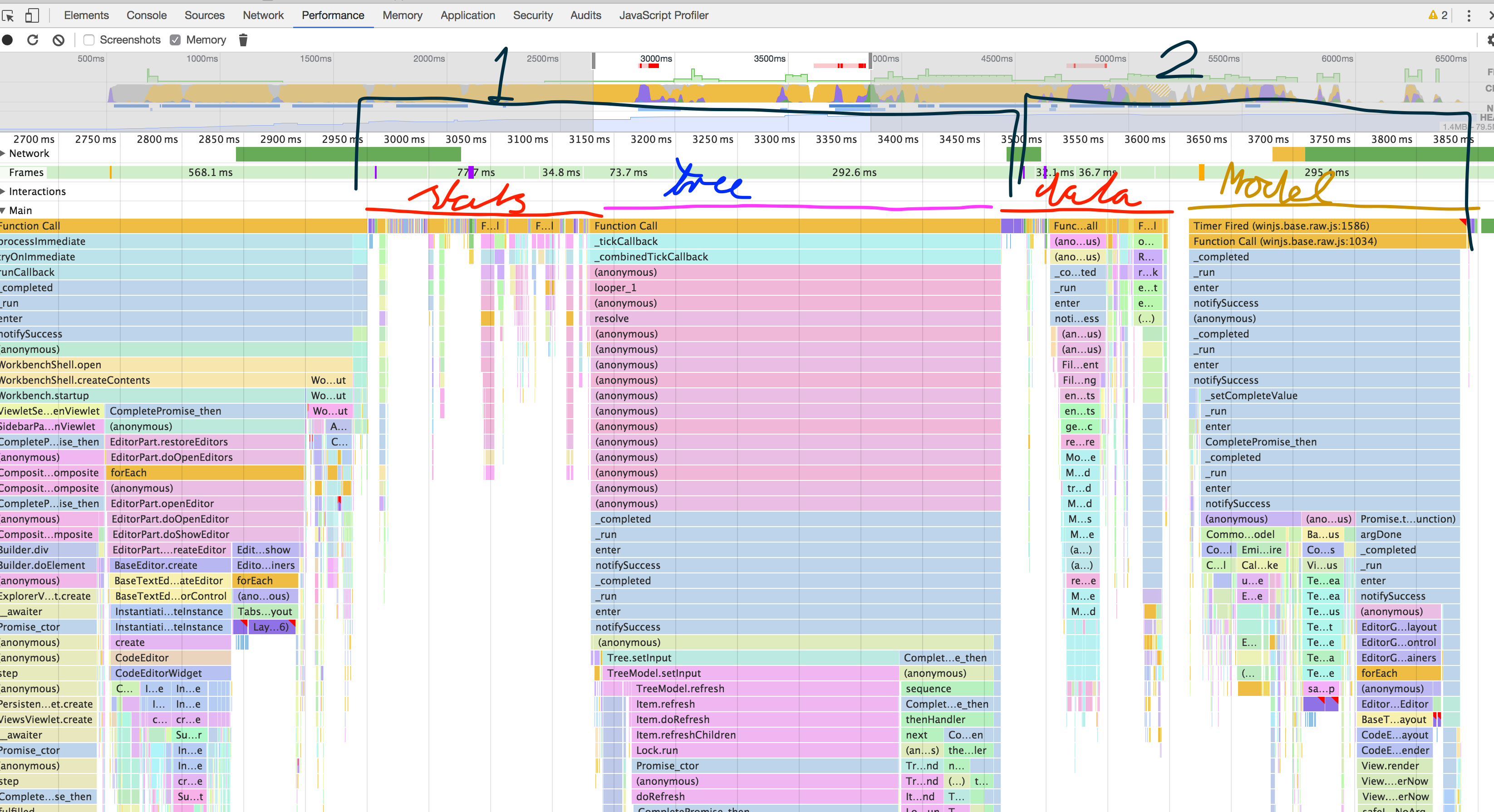
I used to Timeline/Performance and
console.timeStamp. Turns out that we instantiate the editor widget ~400ms after startup. However, setting the model only happens 2seconds later... In-between we do all kinds of things (extension parsing, tree updating etc, etc). We should look at all of them and justify why they are more important thansetModel...The patch to get the performance marks: timeStamp.patch.txt
The text was updated successfully, but these errors were encountered: