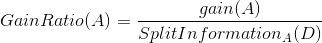A small suite of functions for calculating information entropy based measurements.
A core concept in machine learning and data science is information entropy. It's important when working with algorithms such as C4.5, ID3 etc. The functions have been carefully implemented following a TDD style and auto-generated documentation is available in the documentation folder.
The definitions given below can be found in Han, Kamber, and Pei's fantastic book on Data Mining: Concepts and Techniques.
The expected information needed to classify a data point in D is given by:
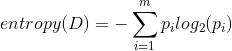
Information gain is defined as the difference between the original information requirement(i.e., based on just the proportion of the classes) and the new requirement (i.e., obtained after partitioning on A).
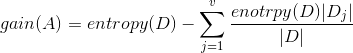
The split information represents the potential information generated by splitting the training data set, D, into v partitions, corresponding to the v outcomes of a test on attribute A.
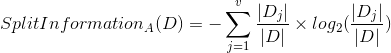
The gain ratio is the result of dividing the information gain by the split information to eliminate bias towards tests with many splits.