

Language Invariant Properties (WIP, and under documented, might break)
- Free software: MIT license
- Documentation: https://language-invariant-properties.readthedocs.io.
Meaning is influenced by a host of factors, among others who says it and when: "That was a sick performance" changes meaning depending on whether a 16-year-old says it at a concert or a 76-year-old after the opera. However, here are several properties of text that do (or should) not change when we transform the text. A positive message like "happy birthday!" should be perceived as positive, regardless of the speaker. Even when it is translated in Italian (i.e., "buon compleanno!"). The same goes for other properties, it the text has been written by a 25 years old female it should not be perceived as written by an old man after translation. We refer to these properties as Language Invariant Properties.
@misc{bianchi2021language,
title={Language Invariant Properties in Natural Language Processing},
author={Federico Bianchi and Debora Nozza and Dirk Hovy},
year={2021},
eprint={2109.13037},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
The class system I originally implemented does not support my new plans and thus I am working on fixing it. Long story short: I originally defined the abstractions thinking about machine translation based tasks but I now want to move this abstraction a little bit further up. Expect a mildly unstable API for a short while.
In this context, we have three "prediction sets" of interest:
- original data (O): this is the data we are going to use as a test set. We will use a classifier on it to compute the classifier bias (i.e., how well a classifier does on this test set). Moreover, we will translate this dataset and use another classifier (in another language) on this data.
- predicted original (PO): this is the data we obtain from running the classifier on O.
- predicted transformed (PT): this is the data we obtain from running the classifier on the translated O data.
The differences between O-PO and O-PT will tell us if there is a transformation bias or not.
tp = TrustPilot("english", "italian", "age_cat", "location/of_the_files/") # selects source and target language and a property to test
text_to_translate = tp.get_text_to_transform()["text"].values # get the text to translate
translated_text = YourTranslator().translate(text_to_translate) # run your translation model
tp.score(text_to_translate) # get KL and significancetp = TrustPilotPara("english", "english", "gender", "location/of_the_files/") # selects source and target language and a property to test
text_to_paraphrase = tp.get_text_to_transform()["text"].values # get the text to translate
paraphrased_text = YourParaPhraser().paraphrase(text_to_paraphrase) # run your translation model
tp.score(paraphrased_text) # get KL and significanceA more concrete on how to integrate this into translation pipeline is presented in the following listing, where we use the Transformer library to translate text from spanish to english.
from transformers import MarianTokenizer, MarianMTModel
from transformers import pipeline
tp = SemEval("spanish", "english", "location/of_the_files/")
to_translate = tp.get_text_to_transform()["text"].values
model_name = 'Helsinki-NLP/opus-mt-es-en'
model = MarianMTModel.from_pretrained(model_name)
tokenizer = MarianTokenizer.from_pretrained(model_name)
translation = pipeline("translation_es_to_en", model=model, tokenizer=tokenizer)
# not the fastest way to do this but it gives the idea
translated = []
for sent in to_translate:
translated.append(translation(sent)[0]["translation_text"])
print(tp.score(translated))The tool is going to output a bunch of metrics that describe the difference between the original data and the two predicted sets (the predicted on original and the predicted on transformed).
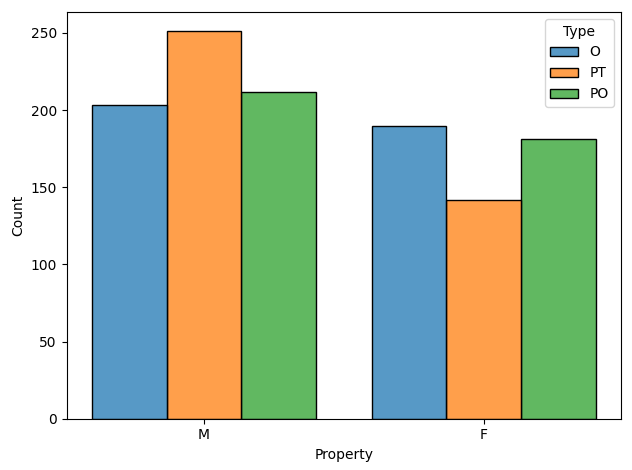
It is possible to generate plots that show the distribution of the predicted labels. For example, here we represent the results from Hovy et al. (2020) showing that translating italian to english makes the text sound "more male".
| DataSet | Languages | Tasks |
|---|---|---|
| TrustPilot | English, Italian, German, Dutch | Age, Binary Gender |
| HatEval | English, Spanish | Hate Speech Detection |
| AiT | English, Spanish | Sentiment |
For SemEval data, interested users should ask access here. Users can place the files in a folder they like, but they should split the data in a format similar to the one already provided for the TrustPilot data (train/test folders, a file for each language).
Adding a new Task should be easy. See for example how we model this for the TrustPilot dataset.
class TrustPilotPara(Dataset):
def __init__(self, source_language, target_language, prop, folder_path, **kwargs):
super().__init__(source_language, target_language, common_classifier=True, **kwargs)
self.prop = prop
self.base_folder = folder_path
def load_data(self, language, prop, task):
data = pd.read_csv(f"{self.base_folder}/{task}/{language}.csv")
data = data[["text", prop]]
data["text"] = data.text.apply(str)
data.columns = ["text", "property"]
return data
def get_text_to_transform(self):
return self.load_data(self.target_language, self.prop, "test")
def train_data(self):
source_train = self.load_data(self.source_language, self.prop, "train")
target_train = self.load_data(self.target_language, self.prop, "train")
source_test = self.load_data(self.source_language, self.prop, "test")
return source_train, target_train, source_testThis package was created with Cookiecutter and the audreyr/cookiecutter-pypackage project template.