microphone -> stt -> press keys on keyboard -> tts
it listens to the microphone.
if the user tells it an order,
it turns the audio into text,
fullfill the order and
tell the user that it has done it.
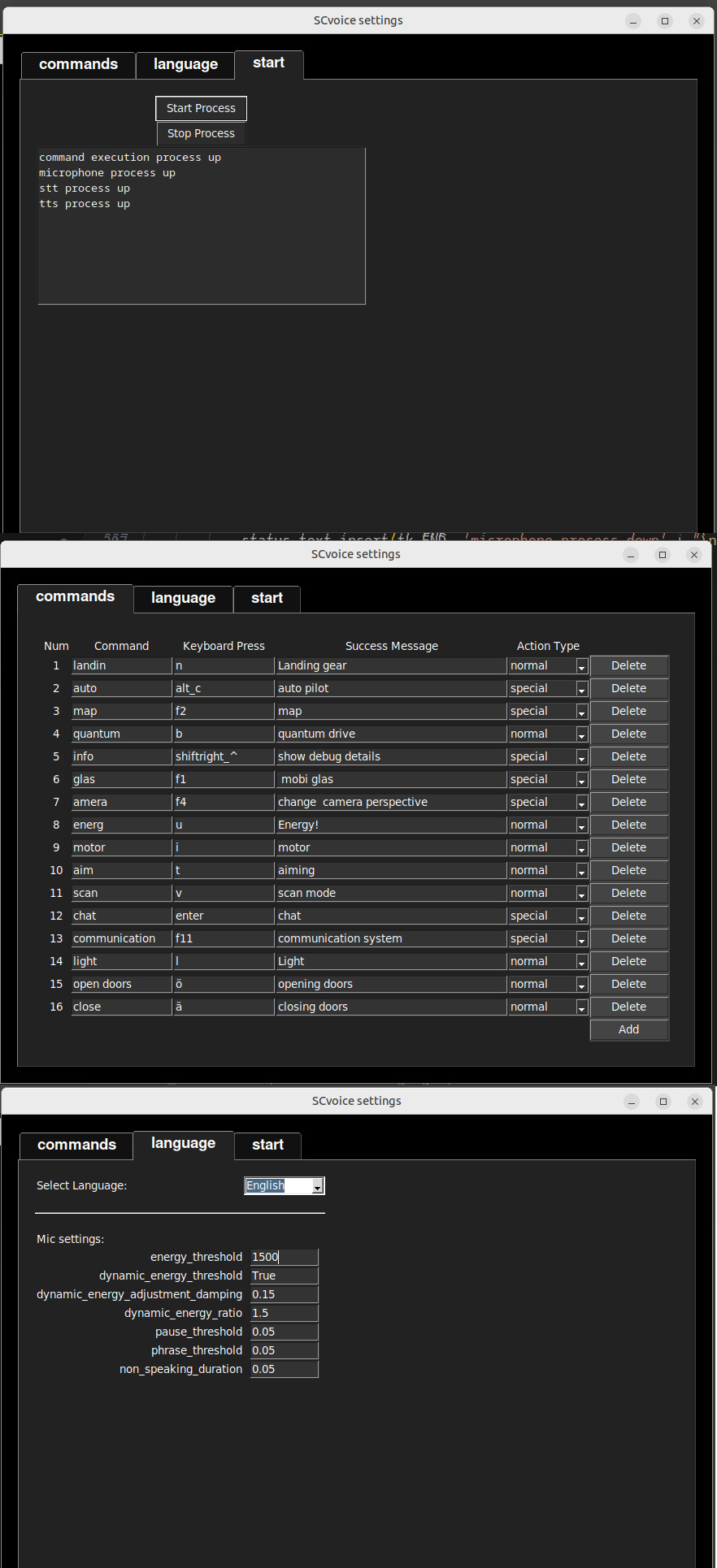
the string resulting from the spoken order is compared with the keywords of the orders wich can be set in gui.
if there is a match, a key is pressed or a key combination, and a successmessage is played. multi commands are possible.
so the user can tell an order, and the system does it an tells that it did do the order.
terminal in the folder of scvoice and start installscript
bash install_scvoice.sh
installs
ffmpeg for audio
espeak for text to speach
local python envirement
py libs in local envirement wicht are needed
then starts scvoice
start scvoice.sh
-might need reightclick -> settings -> permission -> run file as a progamm , to be started per click
or in terminal navigate to the folder and enter
venv/bin/python3 scvoice.py
join our Matrix chat at #SCvoice:fkeinsten.de
there are some errormessages under linux according to alsa and jackserver, this can be ingnored,
since it's a problem alsa has, wich does not break the functionality, and is caused by speechrecognition libery when trying to find the right microphone.
since the speech recgnition model is very small, it has limited capacity and high speed.
this makes it sutitable to drop ordes wich get fullfilles very fast, cause the tts needs less time.
but therefore it can not understand all words, while it is very reliable on words it knows.
multi orders are possible, if you for example tell 4 orders in a raw fast, they all are done.
for example:
"energy, engines, communication" -> would press "u" "i" "f11" and tell that it has done it.
since the command-execution and the audio feedback loop are running in different processes, it can press all the buttons ,
while it is still expessing that it pressed the first one.
this prevents, that the second coman has to wait until the message is fully played.
same for the recognition, it has its own loop, and while an audio order is processed. it is ready to take the next order.
therefor
microphon , stt , commandexecution and succesmessage, are running in 4 different processes. wich communitcate with queues.
this parallel processing, enables it to react fast enought to be useful in game. as i tested it,
it needs maybey 0.4sec from order spoken to fullfilles keypress. so it still has a delay, and you might could be faster with pressing keys.
speech_recognition
vosk stt model
pyttsx4 with espeak as tts
pyautogui and pynput for button presses and hotkeys
multiprocessing to make commandexecution faster, for multicommands
alphacephei https://alphacephei.com/
they provide exellent small and fast regognitiion models open source <3<3<3
all the models used here are made by them (VOSK)
espeak-ng provide open source tts, wich we use here as main option for audio success message output <3<3<3
and all the great python liberies:
pyttsx4
speech_recognition
pynput
...