![]()
网站 • 文档 • Cube.js模型文档 • Docker Hub • Slack社区
Synmetrix(前身为MLCraft)是一个开源数据工程平台和用于集中度量管理的语义层。它提供了一个完整的框架,用于在大规模下对度量数据进行建模、集成、转换、聚合和分发。
- 数据建模和转换:使用SQL和Cube数据模型灵活定义度量和维度。应用转换和聚合。
- 语义层:将来自各种来源的度量整合到一个统一、受管理的数据模型中。消除度量定义上的差异。
- 定时报告和警报:通过可配置的报告和警报监控度量并获得变化通知。
- 版本控制:随时间跟踪模式变化,以确保透明度和可审计性。
- 基于角色的访问控制:管理数据模型和度量访问权限。
- 数据探索:通过UI分析度量,或通过SQL API与任何BI工具集成。
- 缓存:使用Cube的预聚合和缓存优化性能。
- 团队:跨组织合作度量建模。
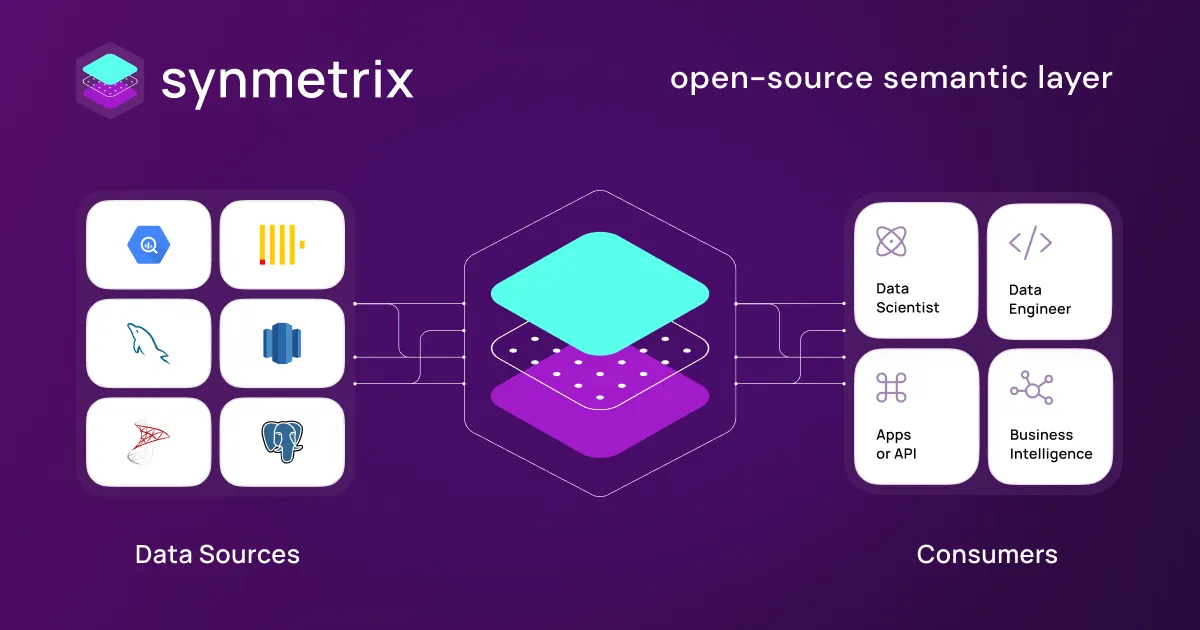
Synmetrix利用Cube (Cube.js)实现灵活的数据模型,可以整合来自各个仓库、数据库、API等的度量。这个统一的语义层消除了定义和计算上的差异,提供了单一真理来源。
然后可以通过SQL API将度量数据模型下游分发给任何消费者,允许集成到BI工具、报告、仪表板、数据科学等中。
通过结合数据工程的最佳实践,如缓存、编排和转换,与自助式分析能力,Synmetrix加速了从度量定义到消费的数据驱动工作流程。
-
数据民主化: Synmetrix 使得数据对非专家用户也易于访问,使组织中的每个人都能轻松做出基于数据的决策。
-
商务智能(BI)与报告: 将 Synmetrix 与任何 BI 工具集成,以进行高级报告和分析,改善数据可视化和见解。
-
嵌入式分析: 使用 Synmetrix API 直接将分析功能嵌入应用程序中,为用户提供其工作流程中的实时数据洞察。
-
LLM 的语义层: 通过 Synmetrix 的语义层提高 LLM 在数据处理和查询中的准确性,改善数据交互和精度。
仓库mlcraft-io/mlcraft/install-manifests包含了在任何地方部署Synmetrix所需的所有安装清单。您可以从此仓库下载docker-compose文件:
# 在新目录中执行此操作
wget https://raw.githubusercontent.com/mlcraft-io/mlcraft/main/install-manifests/docker-compose/docker-compose.yml
# 或者,您可以使用curl
curl https://raw.githubusercontent.com/mlcraft-io/mlcraft/main/install-manifests/docker-compose/docker-compose.yml -o docker-compose.yml
注意:确保检查docker-compose.yml文件中的环境变量。必要时进行修改。
执行以下命令,启动Synmetrix以
及用于数据存储的Postgres数据库。
$ docker-compose pull stack && docker-compose up -d
验证容器是否运行:
$ docker ps
CONTAINER ID IMAGE ... CREATED STATUS PORTS ...
c8f342d086f3 synmetrix/stack ... 1分钟前 运行中 1分钟 80->8888/tcp ...
30ea14ddaa5e postgres:12 ... 1分钟前 运行中 1分钟 5432/tcp
安装所有依赖大约需要5-7分钟。等待直到出现 Synmetrix Stack is ready消息。您可以使用 docker-compose logs -f查看日志,以确认过程是否完成。
- 您可以在http://localhost/访问Synmetrix
- GraphQL端点位于http://localhost/v1/graphql
- 管理控制台(Hasura Console)可以在http://localhost/console找到
- Cube Swagger API可以在http://localhost:4000/docs找到
-
管理控制台访问:请确保在docker-compose文件中检查
HASURA_GRAPHQL_ADMIN_SECRET。这是访问管理控制台的必要条件。默认值为adminsecret。记得在生产环境中修改此值。 -
环境变量:设置所有必要的环境变量。Synmetrix将按默认值运行,但某些功能可能不会按预期执行。
-
预加载的种子数据:该项目配备了预加载的种子数据。使用下面的凭据登录:
- 电子邮件:
demo@synmetrix.org - 密码:
demodemo
该账户预配置了两个演示数据源及其相应的SQL API访问权限。对于SQL操作,您可以使用以下凭证与任何PostgreSQL客户端工具(例如DBeaver或TablePlus)一起使用:
主机 端口 数据库 用户名 密码 localhost 15432 db demo_pg_user demo_pg_pass localhost 15432 db demo_clickhouse_user demo_clickhouse_pass - 电子邮件:
- 登录名:
demo@synmetrix.org - 密码:
demodemo
| 数据库类型 | 主机 | 端口 | 数据库 | 用户 | 密码 | SSL |
|---|---|---|---|---|---|---|
| ClickHouse | gh-api.clickhouse.tech | 443 | default | play | 无密码 | true |
| PostgreSQL | demo-db-examples.cube.dev | 5432 | ecom | cube | 12345 | false |
Synmetrix利用Cube进行灵活的数据建模和转换。
Cube实现了一个多阶段SQL数据建模架构:
- 原始数据位于源数据库中,如Postgres、MySQL等。
- 使用Cube数据模型文件将原始数据建模为可重用的数据仓库。这些模型文件允许定义度量、维度、粒度和关系。
- 模型作为原始数据和应用代码之间的抽象层。
- Cube然后根据模型生成针对原始数据的优化分析SQL查询。
- Cube Store分布式缓存通过缓存查询结果优化查询性能。
这种建模架构使得使用Cube创建快速且复杂的分析查询变得简单,这些查询被优化以针对大型数据集运行。
统一数据模型可以整合来自不同数据库和系统的度量,为最终用户提供一致的语义层。
对于生产工作负载,Synmetrix使用Cube Store作为缓存和查询执行层。
Cube Store是一个为操作分析而特别构建的数据库,优化了快速聚合和时间序列数据。它提供:
- 分布式查询以实现可扩展性
- 高级缓存以实现快速查询
- 面向分析性能的列式存储
与Cube的集成以进行建模
通过将Cube Store和Cube结合使用,Synmetrix从出色的分析性能和度量建模的灵活性中受益。
| 仓库 | 描述 |
|---|---|
| mlcraft-io/mlcraft | Synmetrix单体仓库 |
| mlcraft-io/client-v2 | Synmetrix客户端 |
| mlcraft-io/docs | Synmetrix文档 |
| mlcraft-io/examples | Synmetrix 示例 |
如需使用Synmetrix的一般帮助,请参考官方Synmetrix文档。如需额外帮助,您可以使用以下任一渠道提问:
查看我们的路线图,了解我们目前正在做什么,以及我们计划在接下来的几周、几个月和几年内做什么。
核心Synmetrix可在Apache许可证2.0(Apache-2.0)下获得。
所有其他内容均可在MIT许可证下获得。
| 组件 | 要求 |
|---|---|
| 处理器 (CPU) | 3.2 GHz或更高,现代处理器,支持多线程和虚拟化。 |
| 内存 (RAM) | 8 GB或更多,用于处理计算任务和数据处理。 |
| 磁盘空间 | 至少30 GB的空闲空间,用于软件安装和存储工作数据。 |
| 网络 | 需要互联网连接,用于云服务和软件更新。 |
@ifokeev, @Libertonius, @ilyozzz