In this report, we present some experienced improvements to YOLO series, forming a new high-performance detector -- YOLOX. We switch the YOLO detector to an anchor-free manner and conduct other advanced detection techniques, i.e., a decoupled head and the leading label assignment strategy SimOTA to achieve state-of-the-art results across a large scale range of models: For YOLO-Nano with only 0.91M parameters and 1.08G FLOPs, we get 25.3% AP on COCO, surpassing NanoDet by 1.8% AP; for YOLOv3, one of the most widely used detectors in industry, we boost it to 47.3% AP on COCO, outperforming the current best practice by 3.0% AP; for YOLOX-L with roughly the same amount of parameters as YOLOv4-CSP, YOLOv5-L, we achieve 50.0% AP on COCO at a speed of 68.9 FPS on Tesla V100, exceeding YOLOv5-L by 1.8% AP. Further, we won the 1st Place on Streaming Perception Challenge (Workshop on Autonomous Driving at CVPR 2021) using a single YOLOX-L model. We hope this report can provide useful experience for developers and researchers in practical scenes, and we also provide deploy versions with ONNX, TensorRT, NCNN, and Openvino supported.
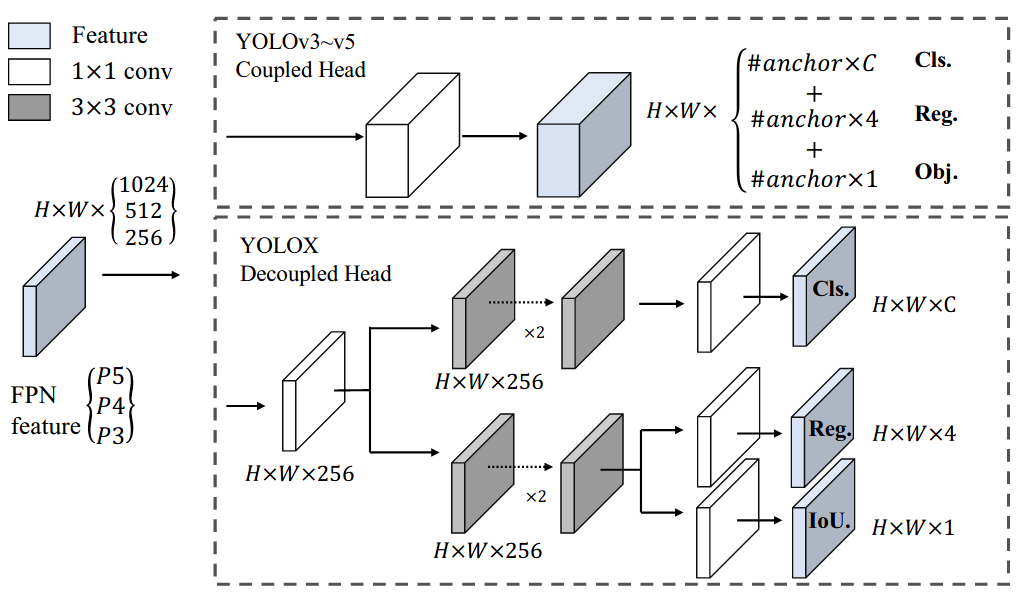
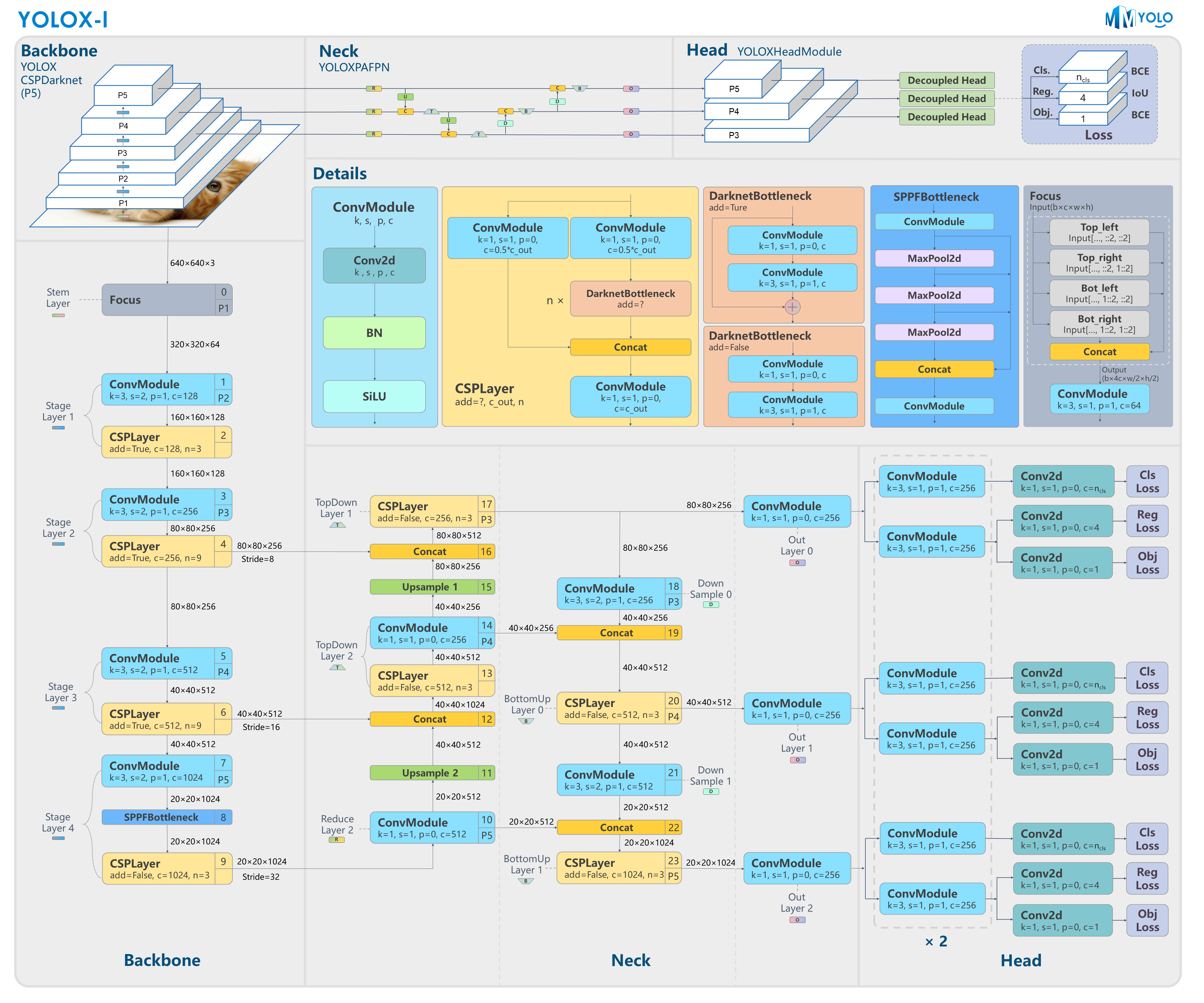 YOLOX-l model structure
YOLOX-l model structure
| Backbone | Size | Batch Size | AMP | RTMDet-Hyp | Mem (GB) | Box AP | Config | Download |
|---|---|---|---|---|---|---|---|---|
| YOLOX-tiny | 416 | 8xb8 | No | No | 2.8 | 32.7 | config | model | log |
| YOLOX-tiny | 416 | 8xb32 | Yes | Yes | 4.9 | 34.3 (+1.6) | config | model | log |
| YOLOX-s | 640 | 8xb8 | Yes | No | 2.9 | 40.7 | config | model | log |
| YOLOX-s | 640 | 8xb32 | Yes | Yes | 9.8 | 41.9 (+1.2) | config | model | log |
| YOLOX-m | 640 | 8xb8 | Yes | No | 4.9 | 46.9 | config | model | log |
| YOLOX-m | 640 | 8xb32 | Yes | Yes | 17.6 | 47.5 (+0.6) | config | model | log |
| YOLOX-l | 640 | 8xb8 | Yes | No | 8.0 | 50.1 | config | model | log |
| YOLOX-x | 640 | 8xb8 | Yes | No | 9.8 | 51.4 | config | model | log |
YOLOX uses a default training configuration of 8xbs8 which results in a long training time, we expect it to use 8xbs32 to speed up the training and not cause a decrease in mAP. We modified train_batch_size_per_gpu from 8 to 32, batch_augments_interval from 10 to 1 and base_lr from 0.01 to 0.04 under YOLOX-s default configuration based on the linear scaling rule, which resulted in mAP degradation. Finally, I found that using RTMDet's training hyperparameter can improve performance in YOLOX Tiny/S/M, which also validates the superiority of RTMDet's training hyperparameter.
The modified training parameters are as follows:
- train_batch_size_per_gpu: 8 -> 32
- batch_augments_interval: 10 -> 1
- num_last_epochs: 15 -> 20
- optim cfg: SGD -> AdamW, base_lr 0.01 -> 0.004, weight_decay 0.0005 -> 0.05
- ema momentum: 0.0001 -> 0.0002
Note:
- The test score threshold is 0.001.
- Due to the need for pre-training weights, we cannot reproduce the performance of the
yolox-nanomodel. Please refer to Megvii-BaseDetection/YOLOX#674 for more information.
@article{yolox2021,
title={{YOLOX}: Exceeding YOLO Series in 2021},
author={Ge, Zheng and Liu, Songtao and Wang, Feng and Li, Zeming and Sun, Jian},
journal={arXiv preprint arXiv:2107.08430},
year={2021}
}