Evaluation loop fails both with and without deepspeed #1472
Comments
|
Thanks @ananyahjha93 , we did merge a major refactor this week (#1419) that may be causing some instabilities on |
|
Thanks @ananyahjha93 for bringing this up. As @hanlint mentioned above, we’re in the process of a few major refactors so v0.9.0 is the most recent release, could you give that a try? |
|
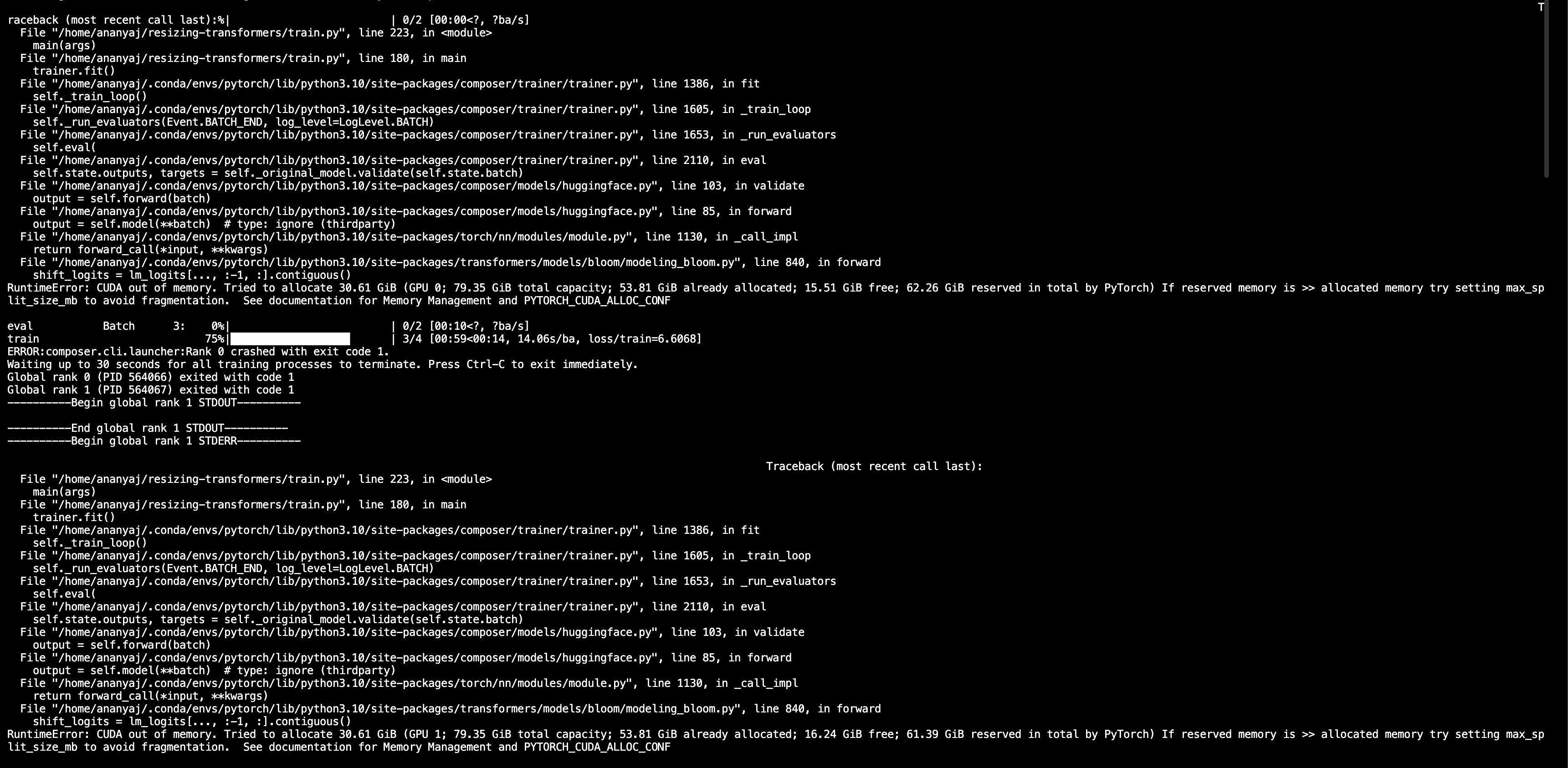
@bandish-shah tried 0.9.0, the eval loop crashes because of OOM error, which is weird because eval should not allocate additional memory on the GPU. This is the GPU usage while training: But once the eval loop starts, the code crashes with this message: |

|
🤔 If you are supplying the same Or alternatively, if you are installing from |
|
@hanlint that is most likely the obvious answer which I have been overlooking |
|
@hanlint closing this issue, yes you were right its the batch size for eval dataloader which was the issue, but I guess a line warning about this with the grad accum thing would be nice! |
|
@hanlint @bandish-shah the batch size thing mentioned fixes 0.9.0 and eval runs fine with it. But with the dev branch the problem of eval dataloader process exiting randomly continues. |
|
Hi @ananyahjha93 we're still working through stability issues on One thing that comes to mind looking at your environment information, I don't think we've tested Composer with Torch 1.12.1 + CUDA 11.3. Our latest Docker images are using Torch 1.12.1 + CUDA 11.6.2 which is what we run our CI testing on: It's a shot in the dark but would it be possible for you to try this configuration? |
|
so this seems to be a ninja version issue, because I was getting the following error on a different machine: zhanghang1989/PyTorch-Encoding#167 So using their fix I followed these steps: however, my dataloader crashes again, which made me look at ninja version in the requirements file shared by @hanlint . updating ninja to 1.10.2 works however, my question is why does installing ninja using this method works and not by doing a pip install? |
|
Yeah that's odd, my requirements were installed via |
|
@hanlint no, that is the weird part that is why it was so difficult to find this bug last week |
|
@hanlint I think you can close this issue here, since this was linked to a specific ninja version local to our systems. I don't think this is a bigger issue. Fixing the ninja version might be an easy fix. |
|
OK thanks! |
** Environment **
** To reproduce
Steps to reproduce the behavior:
Expected behavior
Eval loop should run without crashing.
Additional context
Error message without deepspeed.

Error message with deepspeed

I'll try to debug a bit more to see what's wrong but posting it here in the meantime.
The text was updated successfully, but these errors were encountered: