Simulation problem: predicted trajectory is not smooth #36
Comments
|
Hi @shubaozhang , thanks for reporting this to us. May I know which scenario token is this? Thanks |
|
Also, what happens to other frames. Do they look normal? |
|
|
The frames after frame 0 are all abnormal, like frame 1 in the above fig. |
All scenarios have the same problem: only frame 0 looks like normal |
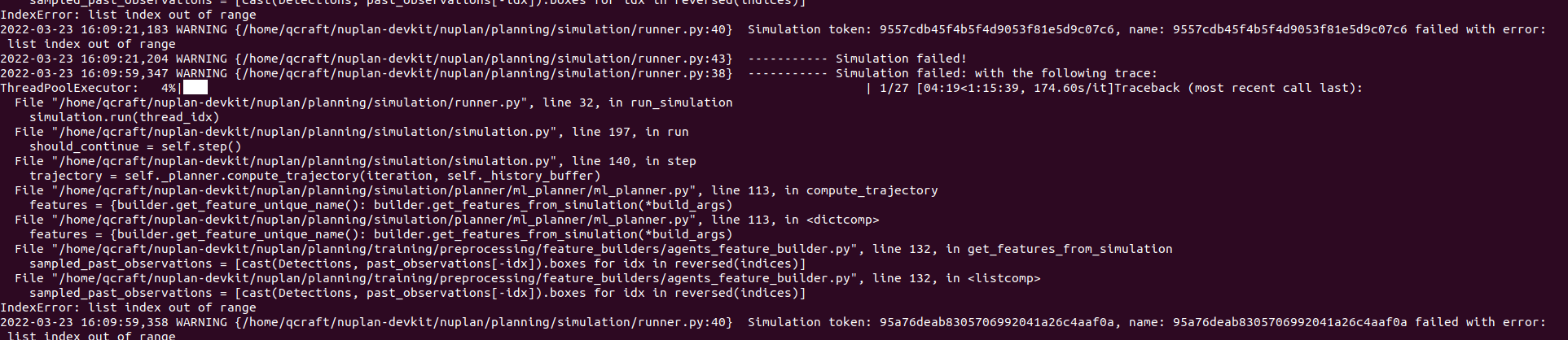
If we setting the subsample_ratio=1, the following error happens for all 27 scenarios.
simulation code: import os CONFIG_PATH = '../nuplan-devkit/nuplan/planning/script/config/simulation' #SAVE_DIR = Path(tempfile.gettempdir()) / 'tutorial_nuplan_framework' # optionally replace with persistent dir EXPERIMENT = 'vector' #LOG_DIR = '/home/qcraft/nuplan/experiments/' checkpoint = '/home/qcraft/nuplan/experiment/vector/2022.03.15.10.25.09/best_model/epoch=10-step=890.ckpt' MODEL_PATH = str(checkpoint).replace("=", "=") PLANNER = 'ml_planner' # [simple_planner, ml_planner] hydra.core.global_hydra.GlobalHydra.instance().clear() # reinitialize hydra if already initialized cfg = hydra.compose(config_name=CONFIG_NAME, overrides=[ main_simulation(cfg) parent_dir = Path(SAVE_DIR) / EXPERIMENT Tokens of all 27 simulated scenarios: 2022-03-23 16:13:17,122 INFO {/home/qcraft/nuplan-devkit/nuplan/planning/utils/multithreading/worker_pool.py:107} Submitting 27 tasks! |
|
i have the same problem.have you resolve it? |
|
Hey @shubaozhang @yangchentao-common |
|
Close the issue now. Please feel free to open another issue if you experience the same issue again |
Problem:
The simulation result on frame 0 looks normal, but the trajectory predicted on frame 1 is abnormal.
### train.py
import os
import hydra
import tempfile
from pathlib import Path
from nuplan.planning.script.run_training import main as main_train
CONFIG_PATH = '../nuplan-devkit/nuplan/planning/script/config/training'
CONFIG_NAME = 'default_training'
SAVE_DIR = Path(tempfile.gettempdir()) / 'tutorial_nuplan_framework' # optionally replace with persistent dir
EXPERIMENT = 'vector' # vector or raster or others
#LOG_DIR = str(SAVE_DIR / EXPERIMENT)
LOG_DIR = str(SAVE_DIR + '/' + EXPERIMENT)
hydra.core.global_hydra.GlobalHydra.instance().clear()
hydra.initialize(config_path=CONFIG_PATH)
cfg = hydra.compose(config_name=CONFIG_NAME, overrides=[
f'group={str(SAVE_DIR)}',
f'cache_dir={str(SAVE_DIR)}/cache',
f'experiment_name={EXPERIMENT}',
'log_config=true',
'py_func=train',
'+training=training_vector_model', # vector model that consumes ego, agents and map vector layers and regresses the ego's trajectory
'resume_training=false', # load the model from the last epoch and resume training
'worker=single_machine_thread_pool', # ray_distributed, sequential, single_machine_thread_pool
'scenario_builder=nuplan_mini', # use nuplan or nuplan_mini database
'scenario_builder.nuplan.scenario_filter.limit_scenarios_per_type=500000', # Choose 500 scenarios to train with
'scenario_builder.nuplan.scenario_filter.subsample_ratio=1', # subsample scenarios from 20Hz (1.0) to 0.2Hz (0.01), 10Hz (0.5), 5Hz (0.25)
'lightning.trainer.params.accelerator=ddp', # ddp is not allowed in interactive environment, using ddp_spawn instead - this can bottleneck the data pipeline, it is recommended to run training outside the notebook
'lightning.trainer.params.precision=16',
'lightning.trainer.params.auto_scale_batch_size=false',
'lightning.trainer.params.auto_lr_find=false',
'lightning.trainer.params.gradient_clip_val=0.0',
'lightning.trainer.params.gradient_clip_algorithm=norm',
'lightning.trainer.params.accumulate_grad_batches=64',
'lightning.trainer.overfitting.enable=false', # run an overfitting test instead of traning
'lightning.optimization.optimizer.learning_rate=2e-4',
'lightning.trainer.params.max_epochs=25',
'lightning.trainer.params.gpus=8',
'data_loader.params.batch_size=3',
'data_loader.params.num_workers=48',
])
main_train(cfg)
simulation.py
import os
import hydra
import tempfile
from pathlib import Path
from nuplan.planning.script.run_simulation import main as main_simulation
CONFIG_PATH = '../nuplan-devkit/nuplan/planning/script/config/simulation'
CONFIG_NAME = 'default_simulation'
SAVE_DIR = Path(tempfile.gettempdir()) / 'tutorial_nuplan_framework' # optionally replace with persistent dir
EXPERIMENT = 'vector'
last_experiment = sorted(os.listdir(LOG_DIR))[-1]
train_experiment_dir = sorted(Path(LOG_DIR).iterdir())[-1]
checkpoint = sorted((train_experiment_dir / 'checkpoints').iterdir())[-1]
MODEL_PATH = str(checkpoint).replace("=", "=")
PLANNER = 'ml_planner' # [simple_planner, ml_planner]
#CHALLENGE = 'challenge_1_open_loop_boxes' # [challenge_1_open_loop_boxes, challenge_3_closed_loop_nonreactive_agents, challenge_4_closed_loop_reactive_agents]
CHALLENGE = 'challenge_3_closed_loop_nonreactive_agents' # [challenge_1_open_loop_boxes, challenge_3_closed_loop_nonreactive_agents, challenge_4_closed_loop_reactive_agents]
#CHALLENGE = 'challenge_4_closed_loop_reactive_agents' # [challenge_1_open_loop_boxes, challenge_3_closed_loop_nonreactive_agents, challenge_4_closed_loop_reactive_agents]
DATASET_PARAMS = [
'scenario_builder=nuplan_mini', # use nuplan mini database
'scenario_builder/nuplan/scenario_filter=all_scenarios', # initially select all scenarios in the database
'scenario_builder.nuplan.scenario_filter.scenario_types=[nearby_dense_vehicle_traffic, ego_at_pudo, ego_starts_unprotected_cross_turn, ego_high_curvature]', # select scenario types
'scenario_builder.nuplan.scenario_filter.limit_scenarios_per_type=10', # use 10 scenarios per scenario type
'scenario_builder.nuplan.scenario_filter.subsample_ratio=0.5', # subsample 20s scenario from 20Hz to 1Hz (0.05)
]
hydra.core.global_hydra.GlobalHydra.instance().clear() # reinitialize hydra if already initialized
hydra.initialize(config_path=CONFIG_PATH)
cfg = hydra.compose(config_name=CONFIG_NAME, overrides=[
f'experiment_name={EXPERIMENT}',
f'group={SAVE_DIR}',
'log_config=true',
'planner=ml_planner',
'model=vector_model',
'planner.model_config=${model}', # hydra notation to select model config
f'planner.checkpoint_path={MODEL_PATH}', # this path can be replaced by the checkpoint of the model trained in the previous section
f'+simulation={CHALLENGE}',
*DATASET_PARAMS,
])
main_simulation(cfg)
parent_dir = Path(SAVE_DIR) / EXPERIMENT
results_dir = list(parent_dir.iterdir())[0] # get the child dir
nuboard_file_2 = [str(file) for file in results_dir.iterdir() if file.is_file() and file.suffix == '.nuboard'][0]
Question:
I found that subsample_ratio affects the simulation. What does subsample_ratio means? What are the proper values of subsample_ratio during training and simulation?
The text was updated successfully, but these errors were encountered: