Bad performance for running this project #47
Comments
|
Did you set an excessive |
|
I would also add that you should use stop tokens to stop generation when you've generated enough. This is one of the biggest "tricks" Copilot uses; all of their requests are 512 tokens but due to stop tokens they almost never actually generate that many. |
|
Thanks for the replies. These are really helpful. And if I am using the copilot plugin where should I put these configs? |
|
Here is a request generated from vs code, it seems that the |
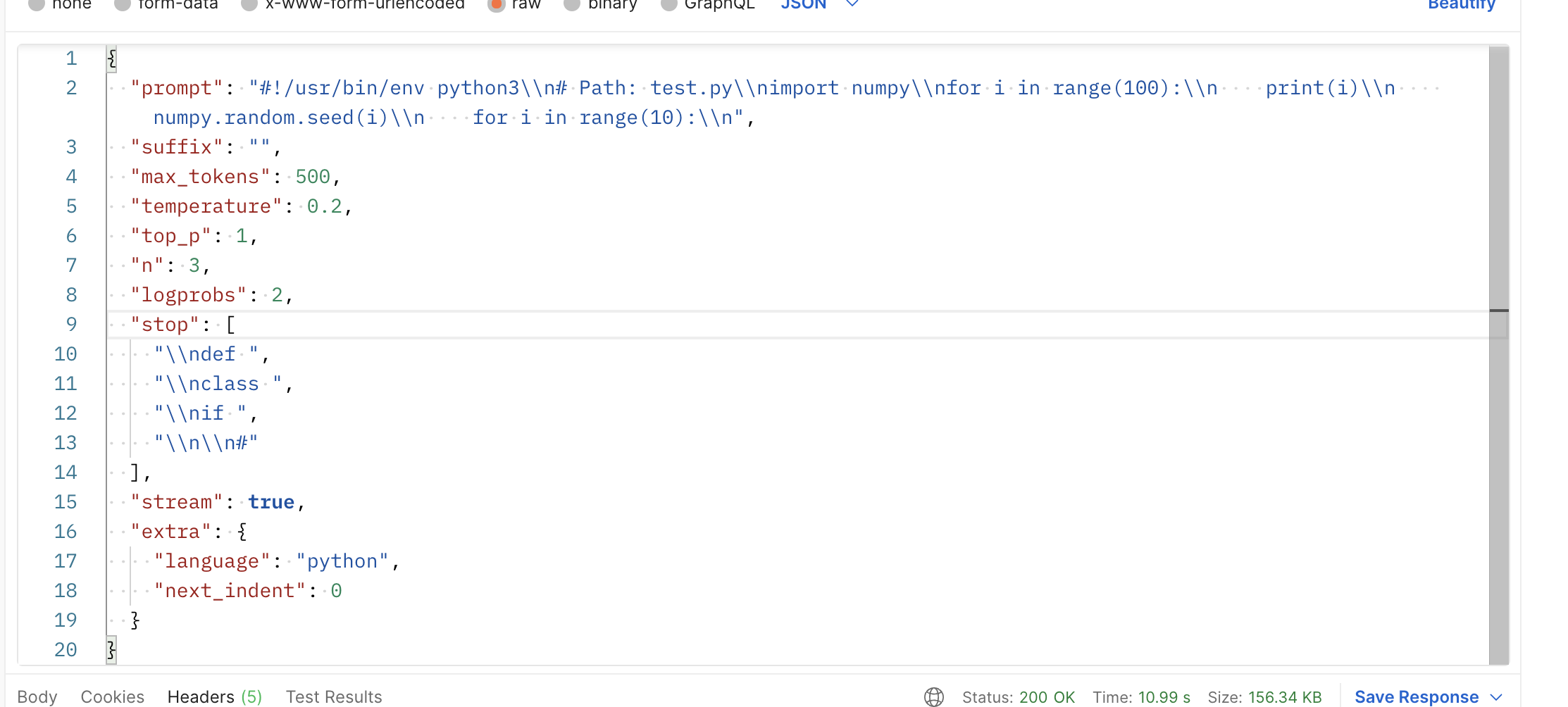
|
My 3090 GPU is going to be crazy when I set max_tokens to 100, and it would take minutes to get suggestions appear. Just curious about the capability of your GPU. |
You can see my configs in the issue and with the default config of BTW, how can I change the |
|
If you go to |

|
Can I set this max_token on fauxpilot side? I'm using the copilot plugin on vim and didn't find a way to configure this. |
Hi, I am trying to run the tritonserver and flask proxy in the same container and found that the performance is bad.
Every request need 4 or more seconds. This is not acceptable...But I am usng a V100 gpu which I think is good enough. Hope someone can help me figure out the reason.
This is the
config.env:This is the
nvidia-smiinfo:And here is the log when start the tritonserver:
The text was updated successfully, but these errors were encountered: