[Research] Fastest Maxpool implementation #174
Labels
Comments
|
Initial implementation Arraymancer/src/nn_primitives/nnp_maxpooling.nim Lines 19 to 51 in b2a4035 This has several disadvantages:
It is short and easy to maintain though |
Merged
|
Maxpool implementation using reshape, it however requires fancy indexing with boolean masks for backpropagation: proc maxpool2d_reshape*[T](input: Tensor[T],
kernel: Size2D,
stride: Size2D = (1,1)
): tuple[cached_reshaped: Tensor[T], maxpooled: Tensor[T]] {.noinit.}=
## Fast maxpool implementation that uses clever reshaping.
## This only works for square pooling regions with:
## - kernel size = stride
## - input is a multiple of kernel size
let
N = input.shape[0]
C = input.shape[1]
H = input.shape[2]
W = input.shape[3]
kH = kernel.height
kW = kernel.width
assert kH == kW
assert kH == stride.height
assert kH == stride.width
assert H mod kH == 0
assert W mod kW == 0
result.cached_reshaped = input.reshape(N, C, H div kH, kH, W div kW, kW)
result.maxpooled = result.cached_reshaped.max(axis=3).max(axis=5).squeeze |
|
closed by: 30bba67 |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Max-Pooling is or at least used to be one of the key component of ConvNets.
Description from CS231n course here.
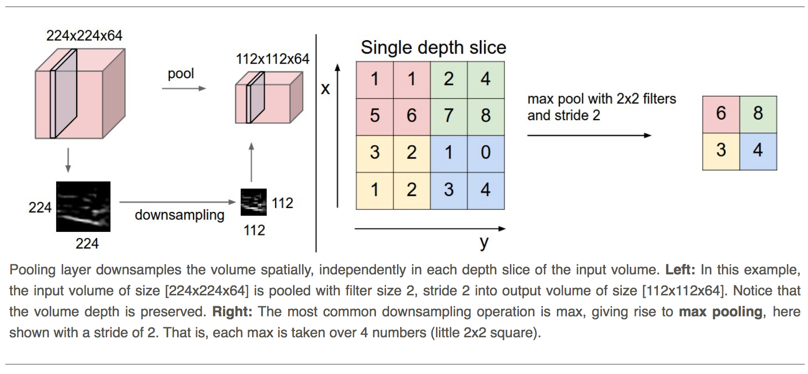
It is similar to convolution except that instead of doing matmul with the pooling mask, we just take the max. As such several implementations from naive to very clever exist:
Direct Max-pooling
Darknet
Caffe
NNPACK
Neon
im2col and argmax based maXpooling
Important: it seems like Argmax-based solution use Numpy fancy indexing (indexing with a Tensor) which is not available in Arraymancer
https://deepnotes.io/maxpool
Chainer
https://wiseodd.github.io/techblog/2016/07/18/convnet-maxpool-layer/
And the corresponding repo
Reshape based maxpooling
CS231n assignment
Matlab from StackOverflow
Numpy from StackOverflow
Auto switch between reshape (square image) and im2col:
DLMatFramework
The text was updated successfully, but these errors were encountered: